
The TPC-H dataset is commonly used to benchmark data warehouses or, more generally, decision support systems. It describes a typical e-commerce workload and includes benchmark queries to enable performance comparison between different data warehouses. I think the dataset is also useful to teach building different kinds of ETL or analytics workflows, so I decided to explore ways of making it available in Amazon Athena.
Typically, you'd download a data generator from the Transaction Processing Performance Council's (TPC) website and tell it how much data to generate. Afterward, you grab a coffee and another coffee, and at some point, you have the data, which can be imported into your favorite data warehouse.
The waiting part is the one I'm not too excited about, so I decided to explore alternative options. Googling led me to this AWS Github repository that the Redshift team seems to use to run benchmarks on their data warehouse. Conveniently, they've generated datasets already and are just loading them from a public S3 bucket. Very interesting.
We can find datasets ranging from 10GB, over 100GB to 3TB, and even 30TB, which should be plenty for our experiments and learning about data analytics. Conveniently, the repository also includes ddl.sql files for each size that describe both the structure of the database tables as well as their location and format in S3.
Here's an abbreviated example of one such ddl.sql:
/* ... */
create table nation (
n_nationkey int4 not null,
n_name char(25) not null ,
n_regionkey int4 not null,
n_comment varchar(152) not null,
Primary Key(N_NATIONKEY)
) distkey(n_nationkey) sortkey(n_nationkey) ;
/* ... */
copy nation from 's3://redshift-downloads/TPC-H/2.18/30TB/nation/' iam_role default delimiter '|' region 'us-east-1';
/* ... */
This makes our task significantly easier. For the most part, the plan is now to make this data available as an Athena table in the raw format and then convert it to an optimized format, i.e., (partitioned) parquet using a CTAS (Create Table As Select) statement, leaving Athena to do the heavy lifting.
Naturally, I started with the 10GB dataset because I like quick feedback cycles, and waiting for 3TB transformations didn't seem very desirable. Also, the data is located in us-east-1, and I'm running my things in eu-central-1, which means I (more specifically, my boss) will be paying for data transfer costs on top of the Athena processing fees.
I quickly noticed that the 10 GB dataset is stored in an odd way. If we look at an excerpt from its ddl.sql, we can see that they're copying the data into Redshift from individual files that are located at the same level in S3.
copy region from 's3://redshift-downloads/TPC-H/2.18/10GB/region.tbl' iam_role default delimiter '|' region 'us-east-1';
copy nation from 's3://redshift-downloads/TPC-H/2.18/10GB/nation.tbl' iam_role default delimiter '|' region 'us-east-1';
This is a problem because Athena tables can only be defined on prefixes and not individual objects. Fortunately, that's only the case for the 10GB dataset. The other sizes reference prefixes, which contain multiple files, and that makes setting up tables for these easier.
To resolve this issue for the 10GB dataset, we have to copy the data to an S3 bucket that we control and store the individual files in separate prefixes. That makes the process for the 10GB workflow more complicated than the larger datasets, but didn't find a better way to work around this. As a result we'll have two DAGs later, one, that handles the smaller dataset, and another, that can handle any of the other sizes.
Ah, DAG - this is the first time I'm mentioning it after the headline - I've written the provisioning process as a DAG for Airflow, mostly because I felt like it. Airflow is not usually meant to be (mis)used for these one-off processes. If you're new to Airflow, maybe check out this introduction to Airflow on AWS that we published a while ago. From now on, I'm going to assume some familiarity with it.
The DAGs I'll be talking about are available on Github, and I won't be covering every implementation detail as they're a bit verbose. We'll first focus on the simple case, which means the bigger datasets, because the more complex case is just an extension of these.
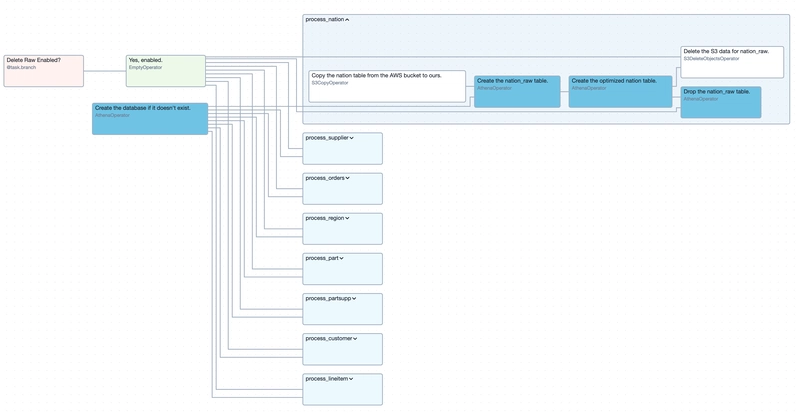
For the 100GB+ datasets, I've written a DAG that accepts a few parameters and then creates Athena tables based on the raw data in the AWS S3 Bucket, executes a CTAS query to convert this data into parquet, stored in our bucket, and finally deletes the intermediate table for the raw data (which can be disabled). In the GUI, the DAG looks something like this:

As you can see, I've employed task groups to visually group the individual processing steps. Since this is a DAG I expect to be triggered manually, I've also made it configurable through Params.
with DAG(
dag_id="create_larger_tpch_dataset",
dag_display_name="Create a large TPC-H dataset",
default_args={"retries": 1, "retry_delay": timedelta(minutes=5)},
params={
"size": Param(
default="100GB",
enum=["100GB", "3TB", "30TB"],
description="Size of the dataset to create, this is based on the unoptimized version of the data.",
title="Dataset Size (unoptimized)",
),
# ...
),
"s3_prefix": Param(
default="tpch_100gb/",
description="Prefix to store the data under. Must be either / (root of bucket) or a string ending in slash, e.g. some/prefix/",
type="string",
title="S3 Prefix",
pattern=r"(^\/$|^[^\/].*\/$)",
),
# ...
"athena_output_location_s3_uri": Param(
default="s3://aws-athena-query-results-account-eu-central-1/",
type="string",
pattern=r"^s3:\/\/[a-z0-9-_]*\/.*$",
title="Athena Result location",
description="S3 URI to store the Athena results under, e.g. s3://my-bucket/and_prefix/.",
),
},
) as dag:
Airflow uses the parameters to provide this convenient GUI to start the DAG.

As you can see, the DAG allows you to select a database in Athena where you want to create your tables, the storage location for the optimized data, and a temporary Athena result location. Selecting a workgroup is also mandatory to make this work. You can also disable dropping the tables for the raw data here, but you should be aware that they reference data in us-east-1, and querying them may incur more charges than you expect.
If you only need a subset of the tables, you'll have to edit the DAG definition yourself. You'll find a TABLE_NAMES list near the top of the file - just comment out whichever tables you don't need.
Depending on which dataset size you picked, this may run for a few minutes, but afterward, you should see eight new tables in the database you entered. Later, we'll run benchmark queries to ensure everything works as expected. But first, let's have a look at the DAG for the 10GB of data. As mentioned above, we need to copy the data into one of our S3 buckets first so that Athena can use it as a table.
Here I ran into a problem where the S3CopyObjectOperator can natively only copy objects up to 5GB in size, so I had to write an extension of that operator, which I documented in this blog post.
Aside from copying the data to our bucket, we also needed an additional cleanup step in the end to remove it if the user chooses. The raw data is uncompressed, so we can save a few dollars here.
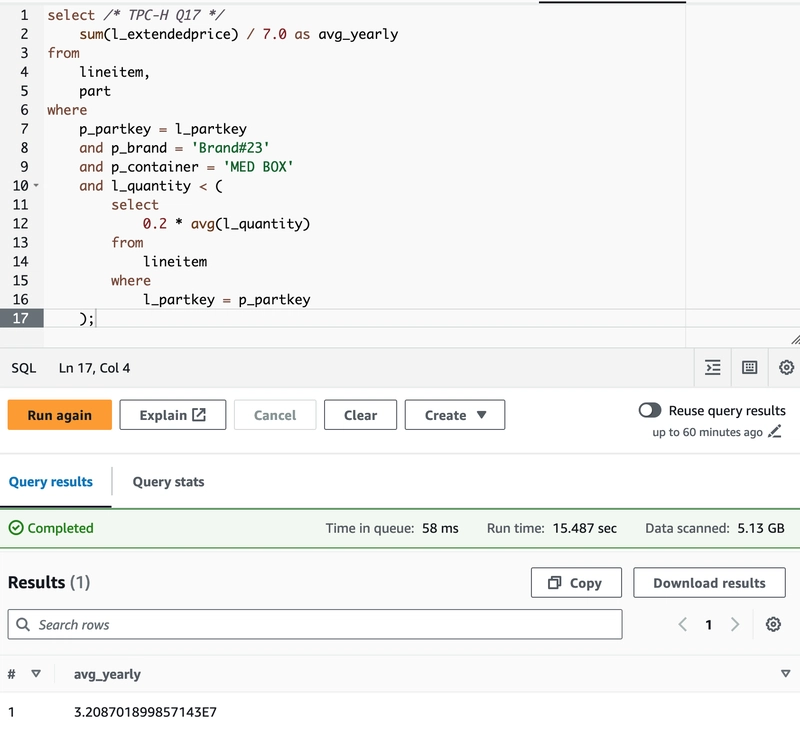
The parameters for this DAG are very similar. I didn't need the size selector, and aside from that, only a few descriptions differ, so I'm not going to show the GUI again. Instead, let's test that our data is accessible by running a few benchmark queries from the aforementioned AWS repository. Unfortunately, there are some syntax differences between Athena SQL and Redshift SQL, so not all of them can be used as-is, but here's an example that works on the 100GB dataset (which is about 22GB as parquet):
So, how can you use these? I've put the DAGs on Github, you can just download them and add them to your DAG directory, where Airflow should pick them up. Then you trigger the DAG you want through the GUI after configuring the paramters and you're good to go.
There are some more things I should mention before we're done. The data appears to be created using the v2.18 generator, and a new major version is out, but that shouldn't be too much of an issue since this is intended to be used for demos or practicing anyway. Additionally, we're relying on AWS keeping the data around in their S3 bucket, but they've been doing that for years, so I'm fairly confident this is stable.
In conclusion, I've shown you how to provision the TPC-H dataset in Athena using Airflow. Now go and build on top of it!
— Maurice
Title Photo by Mika Baumeister on Unsplash

Top comments (0)