
For a deep dive into building Serverless APIs using Hasura GraphQL join us at Create:Serverless. Allison and Burke will discuss how you can bring together your data sources into a unified GraphQL API with the Hasura GraphQL Engine & Azure Functions.
Sessions at Create:Serverless will be FREE to attend and I'm excited to be your host during the day :)
What do GraphQL and Serverless have in common?
They might seem unrelated, but in fact, both of them are very popular at the moment and have a similar trending pattern. While you're reading this article, I'm confident someone is open sourcing a new library either for Serverless or for GraphQL - awesomesauce, maybe for both - that will enable us to build amazing products more easily. The hype train, that's one thing that they have in common 🚂!
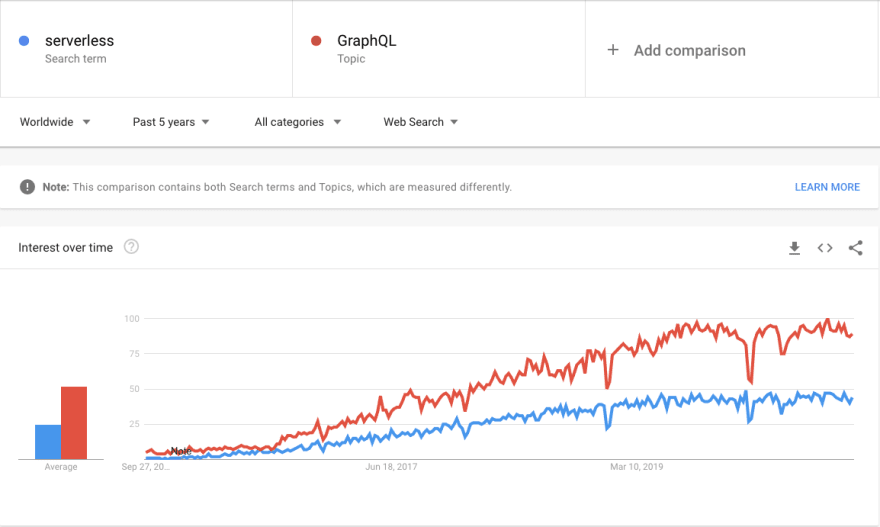
Serverless and GraphQL have seen a massive adoption with Javascript developers.
With GraphQL, frontend developers can intentionally move fast in building applications. With few exceptions, the back and forth and dependencies between backend and frontend teams are eliminated by the easiness of sharing data between the two. With Serverless, it's become a LOT easier to extend our frontend skills and build APIs without acquiring expertise in provisioning and managing servers.
Both of them have emerged around the same timeline, marking the dawn of a new era in developer productivity and tools.
Why GraphQL
GraphQL is a query language for your API and a runtime to execute those queries on your existing data. It was developed by Facebook in 2012 when they started rewriting their mobile applications to native clients. The initial goal was to define a data fetching API powerful enough to describe all of Facebook. They ended up creating a Javascript reference implementation and open sourcing a spec that help address a few very important challenges when building APIs:
Overfetching data - retrieving data that we don't need
Traditionally, to help solve this problem, we create a new endpoint that returns only the data we need or update an existing endpoint and include the required data. Whereas that can be compelling, and that's something that most of the teams do, it adds complexity to our code. We'll now have to process the response and filter out the data that we don't need on the client-side. On top of that, we have a leaking abstraction - there's now a strong coupling between our backend and frontend that reflects our client code's data needs.
Underfetching data - also known as a chatty API, when our APIs force clients to make multiple requests to perform a single operation
You might be familiar with the n+1 problem - when a request to one item turns into n+1 requests since it has n associated items. The roundtrips to the server consume valuable user data and time.
One of the reasons we need to think about overfetching and underfetching is that both directly impact our user's experience. Having to process data on the client-side and making multiple roundtrips to the server incurs a delay on our client apps, which in turn has a direct impact on the user perception:

API proliferation and lack of up to date documentation
The first two challenges lead to a high number of poorly documented and maintained endpoints that are tightly coupled to our client apps.
With GraphQL queries, clients only retrieve the data they need - they control the size & shape of the data that the API returns. Developers have access access to a single API endpoint with realtime documentation for available operations that can be run against the API.
Why Serverless
Serverless enables us to run code in reaction to events, without having to worry about managing their runtime. The platform provider will automatically scale up and down the number of resources needed to meet the current workload while maintaining reliable performance for our users. One of the most common uses cases for serverless is building web APIs for frontend and mobile applications.
What are the benefits of using Serverless and GraphQL together?
Serverless and GraphQL like any other strong symbiosis relationship complement one another beautifully.
With Serverless we get easy integration of different data sources, while with GraphQL we can easily unify multiple data sources together.
With Serverless, we get autoscalability out of the box, and with GraphQL, we get a single endpoint that will allow us to query multiple data sources.
With Serverless, we end up writing less code focusing on the problems we're solving for, and with GraphQL, we make a smaller number of requests optimizing for user performance.
With Serverless and GraphQL, we can achieve more by doing less.
Want to do more with Serverless?
Join us at CREATE:Serverless on Sep 30 (8:00am PDT / 12:30am EDT) for a 4-hr free virtual event with 8 sessions and a 50-minute hands-on workshop to jumpstart your serverless journey
Bookmark our anchor post and do check back for updates

Top comments (0)