
Twitter has officially released its new API, aka version 2. It comes with great premises. Introduced with an astonishing video and proudly promoted as a rebuild "from the ground up to better support developers", including business, academic researchers, students, and makers.
I was really excited to see the new opportunities that it brings. While still in an early access phase, I must say that I'm a bit disappointed so far. Let's see why.
The great.
The developer portal, including the developer's dashboard, has been fully rebranded. Information is a bit easier to find, more structured. There are many more quickstarts which is really great for a newcomer.
One thing that I've immediately liked is the improved way of filtering data. A bit like in GraphQL, you can ask Twitter which properties you are interested in.
For example, when asking for tweets, Twitter sends by default the id and text (content) of the tweet. If you are interested in receiving specific metrics, like the number of retweets, you can ask for that by adding a new parameter.
This will look like the following:
?tweet.fields=created_at,public_metrics
It reduces the payload to just what you want - which is always great. Though I'd love to be able to have more granularity. For example, ask for retweets only, and not having all public_metrics. Also, the default fields are mandatory. There's no way to overrides that.
The meh.
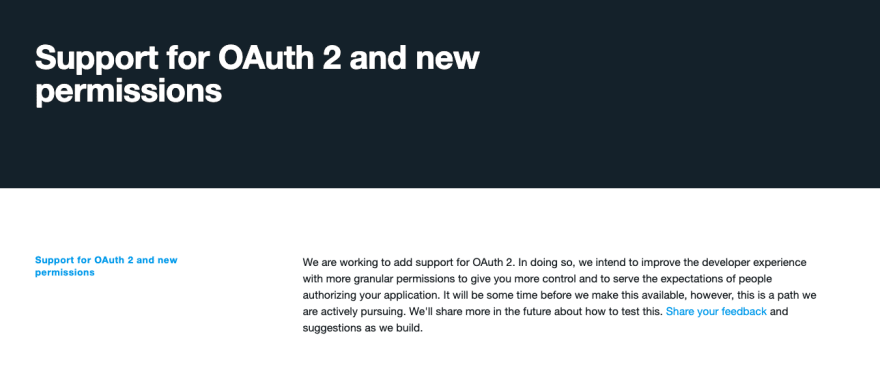
The API still uses OAuth 1.0a for the authentication part. That's probably the first thing that "shocked" me. Most APIs have migrated to OAuth 2.0 for years. It's really surprising that Twitter didn't take the leap when releasing this new version.
OAuth 2.0 has introduced the notion of scopes, which is very familiar today. By keeping OAuth 1.0a, Twitter will not be able to provide granularity to the developer on the user's data.
In other words, by allowing an application, it will always have full access to your data. Which is not something people want anymore. Twitter says it's on the roadmap though.
Also, Auth 1.0a is far more difficult to use from a developer's perspective. It requires signing each request for example. But, I'm using a tool called Pizzly (that I've participated to build) to help with that.
More broadly, I haven't seen many innovations with that new API. It's mostly a REST API, with some interesting concepts (e.g. the ”fields” parameters). But some other APIs already have similar concepts in place (Google APIs has used the field parameters for years).
The ugly.
The API quotas are still very low. An application can't request more than 500,000 tweets per month. I've estimated that when browsing my feed on Twitter, I'm looking at about 50 tweets per session. Per month, that's 50 * 30 = 1500 tweets.
Building an application that just renders a user's feed would stop working at just a few hundred active users. It's really not that much.
I also have this feeling that this new API isn't targetting small developers. For instance, when starting to look at the new Twitter API, I wanted to build a graph of my Twitter timeline to make it looks a bit like GitHub Contributions Graph.

There's no such endpoint that lets you do that in the new Twitter API. No endpoint to retrieve tweets of an authenticated user. And the public tweets can be retrieved in the last 7 days only. It's a bit of a shame that Twitter keeps its user's data for itself.
Another example that strengthens this feeling, one of the 6 available endpoints is the sampled stream which delivers "a roughly 1% random sample of publicly available Tweets in real-time". That's kind of awesome! But the amount of data that you need to manage is massive...
Conclusion
The API is still in an Early Access phase and we can see it.
Not all endpoints are available. As of writing, only 6 endpoints are. And for example, you can't post a new tweet with the version 2; neither manage DMs. So it's really early to get the most of this new API.
Also, tons of great features are still on the roadmap. But I have the overall feeling that the new Twitter API is mostly targetting big players (established companies, academic researchers, etc.).

Top comments (14)
Kinda disappointed they didn't actually make it a graphql endpoint, I thought that was the plan
Honest question: why would you have cared for a GraphQL endpoint if the REST API contains what you need (I'm talking about content, not form, let's assume the new REST API is already satisfactory in its content) ?
It's not necessarily that it's not a GraphQL API, it's that they seemed to have explored it for a long time at least to my knowledge, but then release an adaptation of REST to the public
Don't know if they use it internally
Sure, that could be.
I was curious about your preference over having an external GraphQL API over a REST one moreso than their internal architecture.
After all, unless they tell us, we won't know if internally they use GraphQL or RPC or whatever to have microservices communicate
I totally agree
Hi, Corentin! Thank you so much for checking out the v2 endpoints we have released so far, and for posting this really helpful write-up. This is exactly what we need as we progress with the new version, I really mean it, a lot of people internally at Twitter have read this, thank you.
I'm not commenting here to "defend" v2, but I'd love to have the chance to comment on a few things, if you're open to it :-)
You and some of the other commenters have talked about GraphQL. Twitter joined the GraphQL Foundation about a year ago (I literally sit next to the folks who built out that internal API, well I did when I was in the office...) and it's true that our internal APIs do use GQL extensively; you all comment on and question why we haven't exposed that externally, and it's a combination of wanting to provide a recognisable RESTful experience for longer term developers, as well as enabling us to retain control of performance etc. It's not a perfect response, I know, but believe me that it was something that was deeply considered for v2, and I think we've landed somewhere that provides some of the benefits at least. We can continue to improve and reconsider, here.
Authentication! Man, this is one of my day-to-day nightmares and opportunities. We really want to shift over to the more granular and standard settings that OAuth 2.0 can provide, but we also have a HUGE installed app and developer and user base, so this is going to take some time to transition. I'm one of the folks that is working with our product and engineering teams on updating this. It's going to take some time, but we do care, we do hear you all, and we want to move to something more common as well. Do stay tuned on this.
"More broadly, I haven't seen many innovations with that new API. It's mostly a REST API, with some interesting concepts" that's completely fair, it was designed to be somewhat familiar if you've done REST API work before. I'd point out that there are legitimate new and interesting things in the data - poll results, pinned Tweets, and above all, annotation / topic information. There are also some changes and redactions, and a TON of cleanup of all those perpetual "null" values that were just leftovers from the past. If there are things you think we should be making available, UserVoice is your friend, we are listening!
"The API quotas are still very low...
I also have this feeling that this new API isn't targetting small developers"
I hear that, too, from you and other active developers. It's a little bit buried in the current docs, but if you check out the FAQ for the new Projects concept, it is not our intention to permanently cap apps. We are not yet in a place to say what the options are, but we definitely want to enable use of the API platform at scale where we can do so. Again, I'd ask you to stay tuned for updates!
Final point on the lack of functionality - yep, we know this. The v2 rollout will take time, and it takes engineering effort to build a whole new API on a new technical foundation. Be assured that yes, posting Tweets (with stuff like polls in the Tweets!) is on the horizon, but it could be a way out. Really appreciate your feedback as we head there, and please keep sharing what you think, if we don't hear from you all, we don't know what you're feeling. Thank you!
Thanks a lot Andy for taking the time to read through this post and giving all of us more context about the new version. I definitely understand this is not easy to release a whole new API and it requires tons of work.
I'm really glad that OAuth 2.0 is on the way and looking forward for the next features to come. Really appreciate that you are taking feedback from the community. To all the engineers and DevRel working on it, keep up the great work ;)
Hello again! Just thought I'd revisit this conversation now that much more of the v2 API is available (we just launched the reverse chronological home timeline feature, yesterday). OAuth 2 is there now - although still being iterated on to improve it - and the majority of features are available, I guess a few big missing parts are still Direct Messages, Trends, and media upload (all of which are coming). I recently made an "Awesome List" to help folks to explore, as well. I know it has taken a while since you posted this, but as I said before, this is an ongoing process for a large API base, and progress has been made!
Thanks again for all your feedback in those initial days post-launch, we listened then, and we are still listening!
That's awesome! Thanks for taking the time to share the updates right here.
The V2 has Oauth 2.0 or so it states in the docs:
developer.twitter.com/en/docs/twit...
I totally agree this is not 100% correct to say that the new Twitter API does not have OAuth 2.0. But what you're mentioning is OAuth 2.0 with Bearer Token, which is like providing an API Key to the developer and ask him to use it in every request.
If you are looking for user data, you've to use OAuth 1.0a. Which does not offer scopes as the commonly used OAuth 2.0 (with Access Token) does. This is what I intended to say by saying the new Twitter API still relies on OAuth 1.0a.
Ok, thanks for clarifying.
Thanks for researching this and sharing these details.
Thanks for reading it through ;)