What is a Tiny URL
It's a service that takes a long url like https://www.example.com/averylongpathoftheurlthatneedstobeshortened and converts it to something like https://sho.rt/34ssd21. Now whenever someone visits the short URL they will be redirected to the original URL
Advantage
With short url, it becomes easier to share and remember urls (provided you can define your own endpoint)
Disadvantages
The one problem that arises with this the risk of now knowing where you are getting redirected to. This can easily be used to phish people.
Requirements
- Generate a short URL for a given long URL. Need to ensure they are unique. If not, then users can visit websites that they were not meant to see (like your portfolio)
- Be able to see the number of clicks of the short URL generated.
Performance Consideration
- Median URL has 10k clicks and popular URL can have more than million clicks
- We may have to support 1 trillion short URLs at a time (Yes, its trillion)
- The average size of the short URL would be in KBs, so total space required would be
1 trillion * 1KB = 1 PB - We will optimize for reads since most people would just be reading rather than generating
Link generation
In order to generate a shorter link for the provided long link, we can use a hash function which would take some parameters and generate a short url for us
Example hash function
hash(long_url, user_id, upload_timestamp)
- long_url: The URL that needs to be shorted
- user_id: The user who is shortening the URL
- upload_timestamp: The time at which the short url is created
Now we need to accommodate a lot of URLs in order to avoid collision between the links, thus we need to determine the length of the short URL (this is the path of the URL i.e https://www.sho.rt/<hash_function_output>)
We will be using lower case alphabets and digits to generate the short URL path. So now we have total 36 characters (10 digits + 26 alphabets).
If the length of the short URL path is n then we have 36^n possibilities. In our earlier assumption we have aimed to store 1 Trillion URLs.
For n = 8
Number of possibilities = 36 ^ 8 ~= 2 Trillion
With n = 8, we have enough possibilities.
So our hashed URL would look something like this
hash(long_url, user_id, upload_timestamp) = https://www.sho.rt/2fjh7rw6
The length of short url path 2fjh7rw6 is 8
Now what should we do in order to deal with hash collisions, we can look for the next available hash since we would be storing the data in a DB table.
Assigning URLs (Writes)
Now we will try to decide on strategies to store the generated short URL.
Replication
We want to maximize our write throughput wherever possible even though our overall system would be optimized for reads.
Now let's assume we are using multi leader replication. We have 2 masters.
User 1 creates a link with hash abc on Master 1 and User 2 creates the same hash abc on Master 2.
After some time both the Masters sync up, in doing so they encounter that
hash abc exists on both of them. In order to solve this conflict the system is designed to use Last Write Wins policy. With that the value of abc is stored def.com which was uploaded by User 2 and the value xyz.com which was set by User 1 is lost.
When User 3 who is expecting "xyz.com" for hash abc is getting def.com, this leads to confusion.
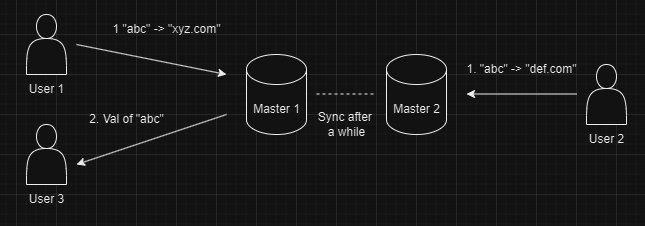
The above issue can cause a lot of confusion and thus we will go with Single Leader Replication for our case
With single leader we won't have the data lost issue as described above but we now have a single point of failure but since our system would be more read heavy, we should be find with Single leader replication
Caching
We can use cache in order to speed up our writes by first writing to our cache and then flush those values to our data base.
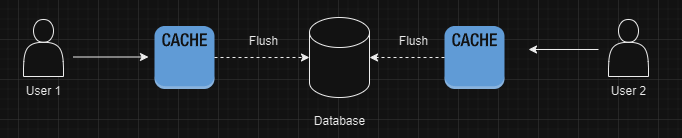
This approach has the same issue of same hash being generated on both caches.
So, using a cache would not make much sense here
Partitioning
It is an important aspect of our design since we can use it to improve our reads and writes by distributing the load across different nodes
Since we have generated a short URL which is a hash we can use range based hashing reason being that the short URLs generated should be relatively even.
Now if a hash is generated against a long URL and it is being stored in one of the nodes but that node already has the generated short URL entry, then we can use probing to deal with this. The advantage of probing is that similar hashes will be present in the same node.
We also need to keep track of consistent hashing ring on coordination service, minimize reshuffling on cluster size change
Single Node (Master Node)
In single leader replication, we have a single write node. In this scenario there could be cases where 2 users end up generating the same hashes, What should be done in that situation ? We could use locking but the hash entry does not exist in the DB yet
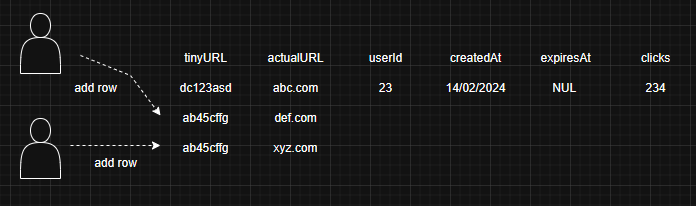
To deal with this we have some workarounds
Predicate Locks
What are predicate locks ? This is a shared lock on row based on some condition that is satisfied.
For example,
We have the below query
SELECT * FROM urls WHERE shorturl = 'dgf4221d'
Now user1 is trying to run this query and in the meanwhile user2 is already utilizing the conditions mentioned in the above query then user1 needs to wait for user2 to finish.
Now we can lock the rows that don't exist yet and then insert the required row. If another user wants to create the same entry they will not be able to do so, since there is a predicate lock on the row because of the first user.
Example query to create a lock on the row (For Postgres)
BEGIN TRANSACTION ISOLATION LEVEL SERIALIZABLE;
-- Check if the user exists (this will acquire a predicate lock)
SELECT * FROM users WHERE email = 'user@example.com';
-- If no rows are found, insert
INSERT INTO users (email, name) VALUES ('user@example.com', 'John Doe');
COMMIT;
In order to improve the speed of the queries we can index on the short url column would make the predicate query much faster(O(n) vs O(logN))
We can also use stored procedure to deal with hash collision. If a user receives a collision then we can use probing to store the long url in the next available hash for the user.
Materializing conflicts
We can populate all the DB with all the possible rows so that users can lock onto row when they are trying to write.
Let's calculate the total space required to store 2 trillion short urls
No. of rows = 2 trillion
Size of 1 character = 1 byte
Length of each short url = 8
Total Space required = 2 trillion * 1 byte * 8 characters = 16 TB
16TB is not a lot of storage since we have personal PC with 1 TB storages
When a user is updating an existing entry, the DB will lock that row and if another user tries to update the same row then they would be incapable of doing so
Engine Implementation
We don't need range-based queries since we are going to mostly query a single row while reading or writing. So, a hash index would be much faster. We cannot use a in memory DB since we have 16 TB of data.
We have 2 choices - LSM tree + SS Table and BTree
| Feature | LSM Tree + SSTable | B-Tree |
|---|---|---|
| Write Performance | ✅ High (sequential writes, batched flushing) | ❌ Lower (random disk writes for every insert/update) |
| Read Performance | ❌ Moderate (requires merging multiple SSTables) | ✅ High (direct lookup using tree traversal) |
| Write Amplification | ✅ Lower (writes are buffered and flushed in bulk) | ❌ Higher (writes propagate across multiple levels) |
| Read Amplification | ❌ Higher (may need to scan multiple SSTables) | ✅ Lower (direct path to data via tree traversal) |
| Storage Efficiency | ✅ Better (compaction reduces fragmentation) | ❌ Less Efficient (fragmentation due to node splits) |
| Compaction Needed? | ✅ Yes (merging SSTables to optimize reads) | ❌ No (data is structured directly in a balanced tree) |
| Durability | ✅ Yes (WAL ensures no data loss before flushing to SSTables) | ✅ Yes (data stored directly in the tree structure) |
| Concurrency Control | ✅ Better (writes are append-only, reducing contention) | ❌ More Locking Needed (modifies multiple nodes in-place) |
| Disk I/O | ✅ Optimized (sequential writes, fewer random writes) | ❌ More I/O (random writes and in-place updates) |
| Use Case | 🔹 Write-heavy workloads (NoSQL, Logs, Streaming data) | 🔹 Read-heavy workloads (Relational Databases, Indexes) |
| Examples | 🔹 Apache Cassandra, LevelDB, RocksDB, Bigtable | 🔹 MySQL (InnoDB), PostgreSQL, Oracle DB |
Considering all the above points and requirement of our system. It makes a lot of sense to use BTree
Database Choice
So far we have made the following choices
- Single leader replication
- Partiotion
- B-Tree based
Keeping all of these things in mind, we can use a relational DB and since we don't need to make distributed query we can choose MySQL for our case (We could also go with Postgresql here).
Maximizing read speeds
We can replicate data on multiple nodes in order to handle the user traffic.
We could possibly get stale data from replica but we could check leader on null result (This can lead to more load on the leader)
Handling Hotlinks
There may be some links that are accessed by a large number of people as compared to the other links. These links can be called Hotlinks
A caching layer can help mitigate a lot of load.
- Caching layer can be scaled independently of DB
- Partitioning the cache by shortURL should lead to fewer cache misses
Populating cache
We can't push every link to cache since we don't which links would be popular. So what should be the approach.
Use write back - This will cause write conflicts since there could be multiple entries for the same short URL
Use Write through - If the cache goes down then we risk losing the shortURL data and this also slows down the write speeds since now we are waiting for the DB to finish the update as well.
Use Write around - We can use this to update the DB first and then in case of a cache miss we can update the cache data as well. This will increase your cache miss but eventually we can better reads.
Analytics Solutions
We will now discuss the ways to update the number of clicks on a particular shortURL
Naive Approach
We keep a clicks counter per rows, we could just increment it.
So, if 2 users are trying to read the same row at the same time then we can have a race condition since now both the users will try to increment the counter at the same time this might lead to wrong count updates
We could have something like a lock / use atomic increment operation per row.
Stream Processing
We can place individual data somewhere that doesn't require grabbing locks and then aggregate later
We can explore the below options
DB - Relatively slow
In-Memory DB - Superfast but not durable
Log Based message - We can write to a write ahead log, which is durable and can be processed at later point
Now we can place the date in some sort of queue like Kafka
Click consumer
We have the following options to process the clicks data from the queue
HDFS + Spark
Batch jobs to aggregate the clicks data will be too infrequent since we would need to dump the clicks data to HDFS first and then process it.Flink
Process each event individually in realtime, may send too many writes to the database depending on implementation.Spark streaming
Processes events in configurable mini-batch sizes. This also does not put a lot of load on the DB unlike Flink
Considering our scenario and how frequently we want to update the clicks data, we can choose Spark Streaming since it processes the data in batches which does not put a lot of load on DB and also updates the DB frequently
Stream consumer frameworks enable us to ensure exactly one processing of events via checkpointing or queue offsets
Process Exactly once
We are guaranteed that the queue and Spark streaming will process the event exactly once but when we are trying to udpate the DB with the click data we might face some issues.
If Spark streaming wants to update the click count by 100 and sends a request to the DB and DB acknowledges the changes but in between the network Spark streaming service goes down. Now when the service comes back up it would not have received the acknowledgment for the previous 100 click count data and it would repush that data to DB

Now we have couple of options for this
Two phase commit - This is too slow for our systems since we would need a coordinator node to implement the 2 phase commit between the spark streaming service and DB
Idempotency Keys - Every update would have a idempotency key t o verify the latest update, if same key is present then we can reject the update
This would scale poorly if there are multiple publishers for the same row i.e lot of updates from multiple spark streaming services to the same row
One Publisher per row
Imaginee our data is growing and we need to process all the clicks data. Now to handle traffic we have implemented multiple kafka queues and spark streaming but now when we are trying to update the data we might need to store multiple idempotency keys in order to update the data correctly which might not be a good idea
Now, we can partition our Kafka queues and spark streaming consumers by short URL. we can ensure that only one consumer is publishing clicks for a short url at a time.
Benefits
- Fewer idempotency keys to store
- No need to grab locks on publish step
Deleting Expired Links
We can run a relatively less expensive batch job every x hours to check for expired links.
Only has to grab locks for row commonly being read
### High Level Diagram
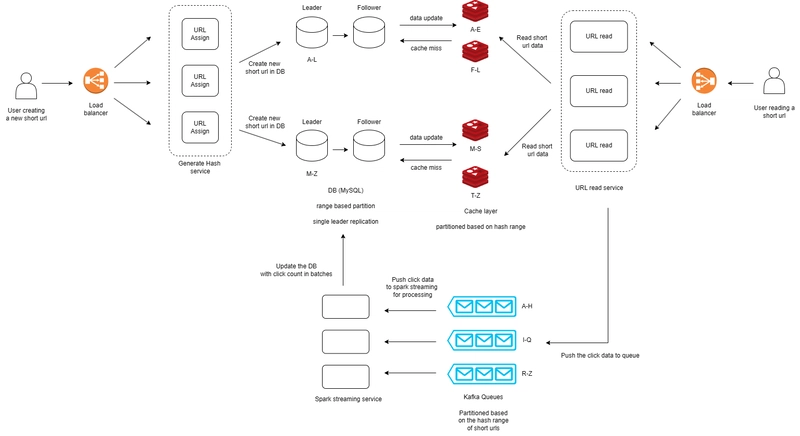
Conclusion
Now with this system we should be able to support the initial numbers that we have quoted. Do let me know what can be improved in this system.
Credits
https://youtu.be/5V6Lam8GZo4?list=PLjTveVh7FakJOoY6GPZGWHHl4shhDT8iV

Top comments (0)