
SLIs, or service level indicators, are powerful metrics of service health. They’re often built up from simpler metrics that are monitored from the system. SLIs transform lower level machine data into something that captures user happiness.
Your organization might already have processes with this same goal. Techniques like real-time telemetry and using synthetic data also build metrics that meaningfully represent service health. In this article, we’ll break down how these techniques vary, and the unique benefits of adopting SLIs.
What are SLIs?
Service level indicators, or SLIs, are metrics that represent your service’s health in specific areas. They can be simple metrics like percentile latency of request for a method, or complex metrics like a latency histogram of 3 different methods. Complexity aside, the most important goal of an SLI is to quantify customer satisfaction.
For example, you might have SLIs that reflect the user experience of adding an item to their shopping cart, which causes a pop up to show the cart’s current contents. These metrics can include:
- How long it takes for the database to update the shopping cart internally
- How long it takes for the database to update the customer’s current total cost
- How long it takes for the shopping cart pop up to load
You might also know that most users don’t immediately click through the pop up to see the full shopping cart page. If you are experimenting with advanced SLIs, you can then decrease the presence of metric for the pop up links in the SLI compared to the others. The end result is a single composite SLI composed of all of the smaller indicators above that represent how satisfied the customer is with adding something to their cart.
SLIs are always tied to an SLO, or service level objective. The SLO sets the point at which the company is no longer accepting of unreliability of the SLI and the resulting inconvenience to the customers. In our example, you might determine that 99% of the time, adding something to the shopping cart should take 500ms or less. Maintaining this SLO, or having this latency SLI remain greater than 99%, ensures your customers remain happy.
Now that we’ve taken a look at what SLIs are, let’s look at what SLIs AREN’T.
What is real-time telemetry?
Real-time telemetry is the practice of observing data coming from a system as it runs. The concept of telemetry is used in a wide variety of industries, including:
- Agricultural telemetry places monitoring stations in fields to relay data about the conditions of the crops
- Medical telemetry includes devices embedded in the body which transmit reports on health conditions
- Aerospace telemetry uses sensors to relay the conditions of aircraft back to pilots
- Retail telemetry tracks sales of each product at each location and correlates them to find trends
- Server monitoring tracks CPU usage over time to indicate overutilization or under-utilization
In each example, the basic process is the same: a monitoring tool is deployed within the system which then reports back to a central repository. The repository is then analyzed to make informed decisions about the system.
This process is the same for telemetry in software. Code is added to each service that continually updates a log of the service’s behavior. The log is then monitored to determine the health of the system.
How are SLIs and real-time telemetry different?
Both SLIs and real-time telemetry report on the health and reliability of your system. However, SLIs are more focused on user experience than overall system health. Reliability is a subjective term reflecting how users perceive the responsiveness of your service. SLIs are based on the aspects of your service that quantify the customer satisfaction, whereas telemetry generally reports neutrally.
Because of this focus on the user experience, SLIs use more black box monitoring than telemetry. Black box and white box monitoring refer to whether or not data is gathered from within the system’s code (white box) or by testing the system from the outside, as a user would (black box). SLIs want to account for every factor in the most critical user experiences, so gathering data from a user’s perspective is helpful.
Also because of the focus on user experience, SLIs are always tied to an SLO, or service level objective. SLOs are set to the point where the user is pained by the unreliability of the SLI. Unlike telemetry, which neutrally reports on system health, SLIs are always seen in the context of an SLO. Until the SLO is in danger of being breached, changes in the SLI aren’t always cause for alarm. You can monitor the rate at which the SLI approaches the SLO, and adjust your velocity accordingly. SLIs allow you to prioritize responses based on customer impact.
What is synthetic data?
Synthetic data refers to data which isn’t directly observed from a system, but comes from simulations of the system. This helps you gather information about how the system would respond in rare situations, or situations that are difficult to directly measure.
Synthetic data can also refer to simulating usage of your real system in order to gather results. This helps you see the effects of rare or extreme use cases, or use cases that are difficult to observe when they naturally occur.
In both cases, you’re abstracting away from your real system or real users to access new information. Getting accurate results requires accurate models. You need to determine whether the investment in building models is worth the information gained.
How are SLIs and synthetic data different?
Whereas synthetic data is helpful for extreme cases, SLIs focus on the most common and important use cases. SLIs can be built by studying user journeys, which track how a user typically interacts with your service. The goal is to encapsulate the most common ways users rely on your service into metrics.
SLIs and synthetic data also differ in their intent. Synthetic data is usually created for a particular experiment or test. The service is modeled under the chosen conditions or is accessed with the chosen use cases. Once the scenario is explored, that particular use of synthetic data is likely discontinued. On the other hand, SLIs continually reflect the real use of services in production. Rather than seeking new scenarios, you’re making sure incidents don’t impact regular operations.
Here’s a summary of some key differences between SLIs, real time telemetry, and synthetic data:
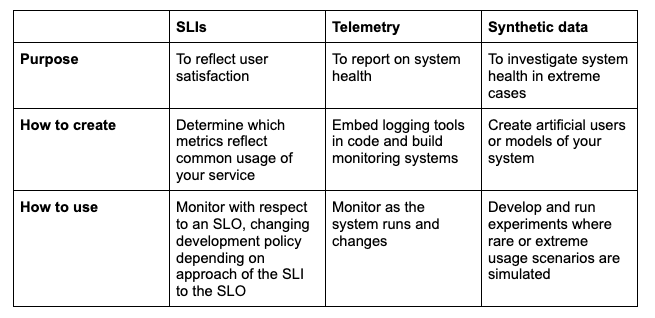
Why try SLIs?
SLIs have many unique benefits for your organization. Here are a few worth considering:
SLIs align goals on customer happiness
It can be difficult to know where to allocate your resources for improving reliability. Ultimately, you know that customer happiness is the most important factor for your organization. But how do you know your efforts will make your customers happy? SLIs provide the solution.
SLIs are built by studying user journeys. These model the most common ways customers use your services. If most of your customers use the search functions and login page for your site, you can prioritize those service areas highly in your SLIs. Conversely, if very few customers use another service area, you can reduce the number of SLIs or even eliminate them for that service.
When considering development projects or operations policies, you can consider how they’ll affect the SLI. Let’s revisit our example of the shopping cart update SLI. If you were to make a change to how the database links items for sale with customers, it could change the speed of the involved metrics. You can estimate how such a change would propagate to the SLI. If it would risk breaching the SLO, you should reevaluate the decision. If not, you can be more confident in moving ahead.
This creates a bridge between the most basic monitoring data and the ultimate goal of customer happiness. All teams can look at how their choices will impact the basic metrics, and align their decision-making based on the SLI.
SLIs quantify customer happiness in an actionable way
Since SLIs reflect the areas that impact customer happiness, they allow you to track customer happiness as a metric. SLIs are also always tied to an SLO, which sets the point where the SLI becomes unacceptable to the customer. These metrics allow you to see how much an incident impacts your customers. This allows you to triage and classify incidents in a meaningful and actionable way.
For example, if you experience a server outage that takes down certain service areas, it can be difficult to understand exactly what the impact was. A very small blip in the availability of a crucial service might bother customers more than a longer failure of a seldom-used service. SLIs can put this all in an actionable context. Incidents that cause big customer impacts will receive proportionally big responses.
SLIs drive learning and growth
Your SLIs and SLOs shouldn’t be set once and then forgotten about. Instead, they should be continually reviewed and revised as your customers’ needs change. Don’t think of this as a burden, but an opportunity. Revisiting your SLIs is the perfect chance to study your users’ behaviours again. Challenge your assumptions of what customers need most from your services. The lessons SLIs teach you can improve even your largest strategic roadmaps.

Top comments (0)