Originally published on Failure is Inevitable.
Application delivery is getting harder each day with the rise in complexity, the demand for services to be always-available, and the increasing pressure on teams to innovate. Service level objectives, or SLOs, can help.
In this blog, we’ll discuss how SLOs are the key to modern application delivery, how to manage and measure them, the importance of observability for your SLO solution, and how to begin the journey to reliable application delivery today.
Why application delivery is harder than ever
Our world has changed. Not only in the sense of increasingly complex technology, but also on a very personal level. With remote work, COVID-19, and the extra stress of decision fatigue leading to reduced cognitive capacity, our own ability to deliver has changed. At the same time, our customers rely on us now more than ever.
The apps that customers use must be available and perform at high levels every cycle. Traditionally, development would slow feature releases to ensure that quality. But speed is crucial as well. Customers want new features and reliability, and existing processes may not support this. Digitalization has become the new mode for survival.
So what does this mean for teams? According to AppDynamics’ “The Agents of Transformation Report 2020: COVID-19 Special Edition,” there are three main reasons for the accelerated urgency of digitalization:
- Rise in app complexity: 80% of teams struggle with spikes in traffic and lack of observability. This impacts customer experience.
- Digital is speeding up: 79% of teams see COVID-19 accelerating digital transformations. Organizations that don’t pivot in this direction risk losing the market.
- Slow is the new down: Latency is as important to monitor as availability. 55% of respondents said slowness was the most frustrating problem when using digital services. This response to slowdowns might be surprising, but after investigation, it makes sense. Think about how much time latency costs users versus unavailability. When an app is down, your user knows right away and moves on to other tasks. They’ve only lost a few seconds. But when an app is slow, it saps time from your customers.
Imagine you're depositing a check on your banking app. You wait for the app to open, for it to log you in, to connect to your camera, to scan the check, and so on. A slow app takes time away from users at every stage. This is why SLOs focus on latency as well as availability.
Additionally, today's environments are no longer simple, monolithic architectures. You must support hybrid architectures spanning many operating models, leading to interdependencies. This increases the risk of having islands of dissociated data. Unfortunately, tools can add to this tsunami of data, creating new islands of data.
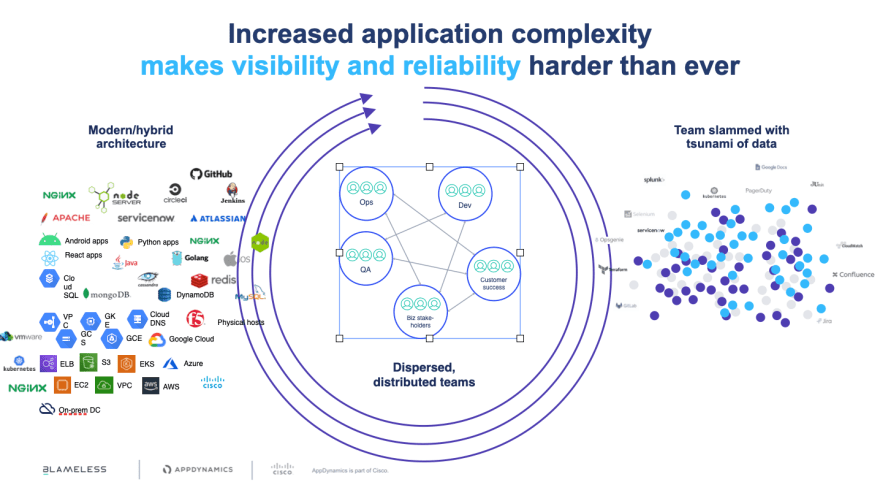
Customer experience lives across these islands and hides within that data tsunami. And insight into this data is hard to glean. The left hand needs to know what the right hand is doing to function as a pair. Humans achieve this with a central nervous system (CNS). The CNS collects and correlates data with context, deriving insight so you can take action. Observability functions the same way for technical systems.
Observability as the central nervous system
Observability is the central nervous system for the digital enterprise. Within organizations, it’s what connects applications to business, to security, and more. Monitoring tools integrate with your systems to decipher what’s important, eliminating data islands. From the AppDynamics perspective, below is a diagram of what this observability central nervous system looks like.

Once you have this level of observability, you need to ensure that you have a feedback loop in place. SLIs and SLOs give you this data-driven basis for decisions, closing the loop. This is especially important in the context of slowdowns.
SLOs alert you to slowdowns
As an industry, we’ve gotten good at responding to outages. Slowdowns are different, and we aren’t as adept at recognizing and resolving them yet. SLOs give us the means to respond more effectively to slowdowns.
Think of SLOs as a meteorology report into how your service is doing. SLOs capture what your monitoring is doing in conjunction with the most important parts of your service’s user journey. SLIs (service level indicators) are the monitoring units that pull information and pass it on to the SLO. The SLO's job is taking that information provided from the SLI and comparing it against thresholds.
Let's say you have an SLI for a latency of 250 milliseconds. You want 95% of interactions to achieve this. Your SLO is going to take these events and measure them against each other. This captures what you expect the customer to experience and reports any anomalies.
Anomalies are recorded via your error budget. Error budgets suggest the amount of unplanned system failure that you can have for your SLO. SLOs capture failure within a timespan and use those values to show where your error budget stands. If slowdowns reach a rate your customers will find unacceptable, it will trigger an alert. With this data, you can make decisions that benefit customers and internal stakeholders.
Using SLOs to align competing priorities
Organizations comprise people with competing priorities. Operations doesn’t want to push features to production if that means the pager buzzing all weekend. Developers don’t want to get blocked on releases by operations. Sales and marketing want new features to sell and promote. So, how can you prioritize all these needs?
SLOs can help with all this, too.

SLOs can help three core stakeholders in the following ways:
- Product and engineering: SLOs provide a data-driven way to focus resources. With the do-more-with-less mentality, teams must pick the most crucial features to spend engineering time on. SLOs help align those priorities using metrics like CSAT and churn.
- Operations: Operations wants to limit business risk. SLOs help communication with developers to achieve both innovation velocity and quality. This team will look at SLO metrics like availability, latency, and throughput.
- Business: These efforts are important, but if the business can’t attract and keep customers, it won’t last. SLOs help this team by providing leading indicators of customer happiness. With SLOs as a unifying tool, organizations can make decisions that take all these competing priorities and needs into account.
Yet, SLOs don’t come without their challenges.
Common pitfalls of SLOs
When helping our customers establish SLOs, we hear four main questions. Let’s walk through each and reflect on how to work through them:
- What is the value of SLOs beyond a measurement of reliability? SLOs aren't only a measurement of reliability. They're also a way to give people power. They provide you knowledgeable insight into what's actually happening in your system. You can look at graphs or reports, but it's hard to centralize that data and extract the value in real time. SLOs are a turning point. If your SLO starts to drop below your threshold, you get an early indicator of a real problem in your system.
- How do I know if my SLOs measure customer experience? You want to make sure that, when your SLOs are defined, that they're as close to the user journey as possible. If your SLO is measuring customer experience, it will change over time as your business does. That means that SLOs will need to be revisited and iterated on an ongoing basis.
- How do I get organizational buy-in to drive adoption of SLOs for the long term? Teams successful in SLO adoption drive this from the bottoms up, with top-down support. The best way is to show immediate value in small increments. Make small investments in SLO with one or a couple teams, then show the value by measuring SLOs over a period of time. Two months is enough time to measure your SLO and show impactful improvement.
- At what point do I stop working on features and start working on reliability? One way to know this is by consulting your error budget. An error budget should contain a policy dictating when to stop feature work. This could happen after two consecutive windows of error budget depletion. It could be after a single incident depletes a certain percentage. The important thing is that all parties agree on the error budget policy.
Now that we’ve addressed these common issues, it’s time to look at how to begin SLO adoption.
Embarking on the SLO journey
According to Blameless’ own engagements with various organizations, over half of SLO implementation initiatives fail the first time. This is often because they lack the right process and culture. You’ll need both for SLOs to be a success.
SLO adoption process

As SLOs will change as your company changes, the process of SLOs is cyclical. You’ll need to iterate on them to ensure that you’re still honed in on customer experience. The image above shows the cycle you can refer to.
- Document the user journey: This is where you’ll map out the critical services for your user. What points are most visible and painful to them? If your organization has a centralized QA function, these user journeys are likely already documented. Ask the team if they have documentation you can reference as a helpful starting point.
- Calculate SLIs and connect SLOs: At this step, you’ll figure out what metrics matter most. Latency is a common SLI to measure. Determine the latency which your customer will find acceptable, and set your SLO. Keep in mind that there is such a thing as too much reliability. If you customer can’t notice the difference, don’t use resources to optimize at that level.
- Monitor SLOs against customer experience and define error budgets: To make sure that your SLOs are working, keep close tabs on customer satisfaction. If your SLO appears to be satisfied, yet your customer success team reports complaints, you need to adjust your SLO. Define error budgets and policies to make sure reliability remains a priority.
- Alert on SLOs to improve focus and limit noise: Set alerts that help your team keep tabs on your error budget depletion. When setting these SLOs, optimize for low noise. If a human doesn’t need to intervene, no one should get paged.
- Minimize toil through SRE best practices: Make sure your SLO process is hardened by other SRE best practices. Automation, in-depth incident retrospectives, and a culture of continuous learning all contribute to the success of SLOs.
Culture is at the heart of SLO adoption, and necessary to mention as well.
Blameless culture
SLOs are difficult to get right, and failure is inevitable. It’s important to create a culture of psychological safety so team members feel they can fail forward. Additionally, you’ll need to set guardrails that work against blame and attribution. There is no such thing as human error; each error can be traced back to a systemic failure.
With both culture and processes in place, you’re ready to begin your SLO journey. But there is still one thing to consider: tooling.
Adopting SLOs with Blameless and AppDynamics

Think back to our analogy of the central nervous system. To act with purpose, we need visibility, insights, action, and feedback.
Together, AppDynamics and Blameless integrate all these dimensions to enable proactive service management. AppDynamics provides visibility and insight and Blameless provides action and feedback. Let's look at how this works.

A global insurance provider captures real-time service metrics with AppDynamics, which also provides real-time telemetry, logs, and other critical pieces of data to help make its system observable. AppDynamics correlates this data to the user experience and picks up early indicators of potential customer-facing impact. These insights will inform the organization’s SLOs.
The insurance provider leverages Blameless to map AppDynamics data to key user journeys within Blameless (ie overall mobile app reliability). The team can operationalize SLOs with Blameless by identifying SLIs and connecting them to relevant SLOs, creating and monitoring error budgets, and defining error budget policies.
If an SLO is breached or an error budget policy is triggered Blameless can start an incident. Collection of data and context is automated, so your team hits the ground running. Through the incident, Blameless records important tasks and messages with our automated chatbot.
After resolution, we aggregate the data for you and create an incident retrospective. This document tracks follow-up and action items, encouraging you to reinvest your learnings. This better protects your error budget and customer satisfaction in the future.
With AppDynamics providing you with visibility and insight into your systems and Blameless driving action and feedback, you’ll close the loop on your development cycles, enabling fast and reliable delivery. If you want to learn more about our integration with AppDynamics, see our integration guide here.
If you enjoyed reading this, check out these resources:

Top comments (0)