
By: Emily Arnott
Originally published on Failure is Inevitable.
SRE advocates addressing problems blamelessly. When something goes wrong, don’t try to determine who is at fault. Instead, look for systemic causes. Adopting this approach has many benefits, from the practical to the cultural. Your system will become more resilient as you learn from each failure. Your team will also feel safer when they don’t fear blame, leading to more initiative and innovation.
Learning everything you can from incidents is a challenge. Understanding the benefits and best practices of analyzing contributing factors can help. In this blog post, we’ll look at:
- A definition for root cause analysis
- A definition for contributing factor analysis
- How to choose between RCAs and contributing factor analysis
- Best practices for contributing factor analyses
- How to incorporate learning from analyses back into development
What is a root cause analysis?
Root cause analysis, or RCA, is a method for finding the reason an incident occurred. Here it is, summarized in four steps:
- Identify the incident. You should understand the exact boundary of what is and isn’t considered part of the incident.
- Create a timeline. Log all events impacting the system. Start when the aberrant behavior begins and end when the system returns to normal.
- Judge the events for causality. Consider the impact of each event leading up to the incident. Did it indirectly or directly cause the incident? Was it necessary for the incident to happen? Was it irrelevant?
-
Build a causal diagram. A causal diagram or graph is an illustrative tool. It shows how events contribute to the incident. Here is an example:
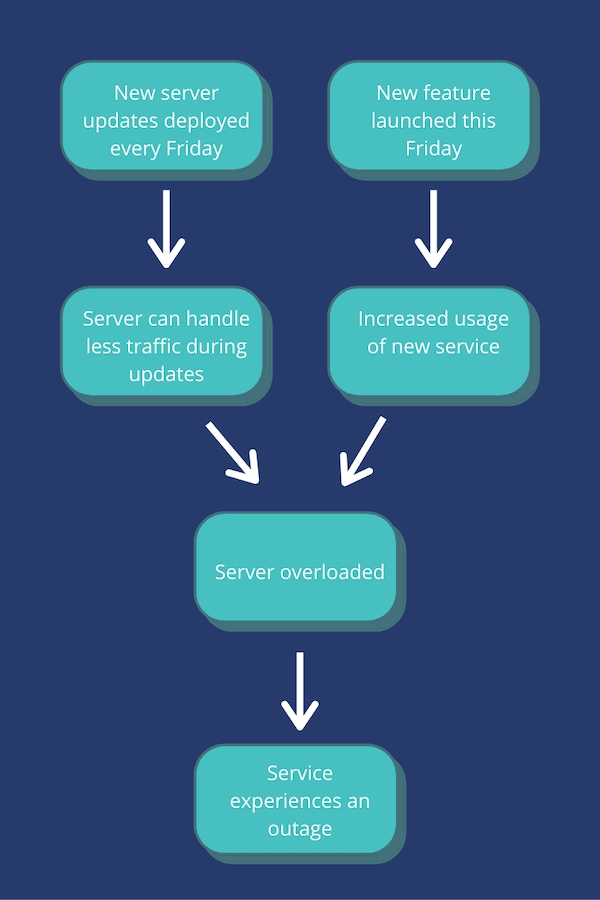
What is a contributing factor analysis?
A contributing factor analysis is another methodology for examining an incident. Rather than pinpoint a single root cause of an incident, the contributing factor analysis looks for a broader range of factors This is a more holistic approach. It considers technical, procedural, and cultural factors. For the above example of a server outage, here are some factors you may also consider:
- The feature launch schedule doesn’t account for server update timings
- No policy to scale up server availability for feature launches
- Server architecture could be updated to support more traffic
- Incident response team could be overworked with new feature launch, delaying backup server availability
Contributing factor analysis should be part of a larger incident retrospective approach. Teams should try to identify contributing factors that can lead to actionable change.
How do you choose between an RCA and a contributing factor analysis?
RCAs and contributing factor analysis each have use cases. RCAs are often formally required while contributing factor analysis is a useful internal tool. Let’s break down why.
When are RCAs used?
RCAs can be part of an organization’s official response to an incident. Because they are often public-facing, they have strict guidelines for formatting. This standardization can be challenging. In a discussion with Blameless, Nic Benders from New Relic shared his thoughts on RCAs:
“The RCA process is a little bit of a bad word inside of New Relic. We see those letters most often accompanied by ‘Customer X wants an RCA.’ Engineers hate it because they are already embarrassed about the failure and now they need to write about it in a way that can pass Legal review.”
Even if they’re unpleasant, RCAs can be necessary. Customers have come to expect openness around failure. Dheeraj Khanna from Tenable explains:
“Today, the industry has become more tolerant to accepting the fact that if you have a vendor, either a SaaS shop or otherwise, it is okay for them to have technical failures. The one caveat is that you are being very transparent to the customer. That means that you are publishing your community pages, and you have enough meat in your status page or updates.”
When are contributing factor analyses used?
Contributing factor analyses help translate the causes of an incident into actionable changes. As this document is for internal use, teams can be more open about the failure and teams can improve.
Nic Benders discusses the shortcomings of RCAs in capturing these areas. “It remains challenging for me to try and find a way to address those people skills and process issues. Technology is the one lever that we pull a lot, so we put a ton of technical fixes in place. But, there are three elements to those incidents. And I worry that we're not doing a good job approaching the other two: people skills and processes.”
When trying to learn the most you can from incidents, looking at all contributing factors is a must. Although you may need both types of analysis, contributing factor analyses are often more useful.
Best practices for blameless contributing factor analysis
Remove the value of blame. While analyzing an incident, blame offers an easy answer. Making an individual at fault removes the responsibility from the system. This means that no changes are necessary to the system; the work is already done. You should not value the solution of blame. By focusing on systemic causes, you can learn more and improve your system further.
Look beyond individuals. Humans aren't perfect. Imagine while conducting a retrospective the team realized that an alert was triggered. But, a team member ignored it. Why? It's time to dig deeper than the individual. Are alerts often noisy or irrelevant? Has this person had enough on-call training and experience? Or have they been on call for too long without a break? By asking these questions, you can arrive at meaningful lessons. It is the best way to ensure the mistake doesn’t happen again.
Celebrate failure. When uncovering factors, celebrate each one as an opportunity for learning. It may seem that the more factors you uncover, the more work you’ve made for yourselves. You don’t want this to discourage team members from suggesting other factors. Create a psychologically safe environment for people to brainstorm. Make sure each contribution is valued.
How to feed learning from analyses back into development
One of the key benefits of a contributing factor analysis is generating actionable insights into the system. But how do you ensure that these lessons lead to changes in development and policy? Here are some tips:
- Create a central repository of required actions per incident
- Invite development teams to incident review meetings
- Bake action items into future sprints, working with product when necessary
- Link learning and tasks to larger initiatives for the organization
- Have review meetings after task completion to ensure the desired changes occurred
Keep a cycle flowing between the causes of incidents and the changes you make. This will help your system continually improve in relevant ways.
Blameless can help your contributing factor analysis process. Blameless incident retrospectives serve as a hub for learning and future changes. Blameless aggregates the data you need to discover systematic causes behind each incident. To see how, check out a demo.
If you enjoyed this blog post, check out these resources:

Top comments (0)