
One of the foundations of incident management in SRE practice is the incident retrospective. It documents all the learnings from an incident and serves as a checklist for follow-up actions. If we step back, there are 7 main elements to a retrospective. When done right, these elements help you better understand an incident, what it reveals about the system as a whole, and how to build lasting solutions. In this article, we’ll break down how to elevate these 7 elements to produce more meaningful retrospectives.
1. Messages to stakeholders
Incident retrospectives can be the core of your communication with customers and other stakeholders, post incident. We talk a lot about how retrospectives function best when they involve input and feedback from all relevant stakeholders. That doesn't necessarily mean squeezing tons of folks into one meeting or sending out one long pdf to a large group without thoughtful considerations.
The best example of this is distinguishing between customer stakeholders and internal team stakeholders. Customers should be kept in the loop and assured that a resolution is imminent or has already come, but they probably don't need to know (or shouldn't know) the minutiae.
Communicating retrospectives to stakeholders requires empathizing with how they use your services. Describe the incident in the context of what matters most. But don’t beat around the bush, either — you don’t want to come across like you’re hiding or downplaying the impact. Simple, factual statements such as “if you use service x to do y, you lost that ability for 12 hours” is enough to convey your understanding.
Once you’ve established the impact, start to regain trust. Reassure stakeholders about relevant things that didn’t go wrong. In the aftermath of an incident, stakeholders could be worried that there are other problems that weren’t reported. Explicitly state that there wasn’t any data lost, or private information made public, or any other relevant concerns.
Share your action plans with stakeholders too. They may not have the context to understand the details of your solution, but you can explain the impact your plan will have. Be direct to convey your confidence. Again, simple statements work great: “the outage was caused by insufficient server bandwidth. A new process will automatically expand bandwidth in response to increased load. This will alleviate an incident like this in the future.” This is the language of scientific research, which removes personal pronouns from the prose. It’s a great way to keep statements simple, avoid finger-pointing, and remain factual and ideally data-driven.
By expanding your message to stakeholders in this way, they’ll understand that their pain has been understood, and addressed systematically and enduringly.
2. Monitoring context
In more technical retrospectives, generally for study by internal development teams, it’s useful to include any monitoring data your system captures at the time of the incident. Did the incident occur during significant traffic? Did it also lead to slowdowns in other areas of the system? This information can lead to helpful revelations.
But you can go even further with this data! Include long-term baseline measurements for these metrics to provide a standard. You might notice that some metrics follow a pattern that accounts for anomalies during the incident. Don’t mistake coincidence for causation.
Also note where your monitoring data was insufficient. Can you think of any metrics that, if you were capturing them, could have tipped you off about the incident earlier? One of the main goals of the retrospective is to drive systemic change. Look for these opportunities to improve your monitoring system.

3. Communication timelines
Hopefully you have a tool to easily build a communication timeline from Slack, MS Teams, or whatever else you use to chat. It’s important to know what steps were taken, how long they took, and when breakthroughs were made. Include information about what roles people played and what tasks they were assigned.
However, it’s also important to see where miscommunication occurred. Did people do redundant work? Were some tasks or steps forgotten or skipped over? Were there misunderstandings about expectations? Note these issues blamelessly. It’s not someone’s fault if they overlooked something; they were doing their best in a stressful situation. That’s why you need policies and procedures to cover the gaps. Investigate these issues to develop policies that would prevent them.
Inevitably, your war room discussion will have some chatter. You probably want to make an “all-business” retrospective that leaves out anything irrelevant, and that’s likely the right move for retrospectives that will be seen by external stakeholders. For internal retrospectives, though, this extra expression can be valuable. It’s good to see how people were feeling during an incident, when they felt stress and relief. It can open up thinking about the human side of incident response, and makes the retrospective more fun to review later.
4. Contributing factors
A big part of the retrospective is uncovering why the incident happened. Without determining that, you can’t make systemic changes to be stronger for next time. The key to making meaningful and enduring changes is to dig deep. Techniques such as the five whys can help you find the causes behind causes. Illustrating it with tools like the Ishikawa diagram can make it easier to understand.
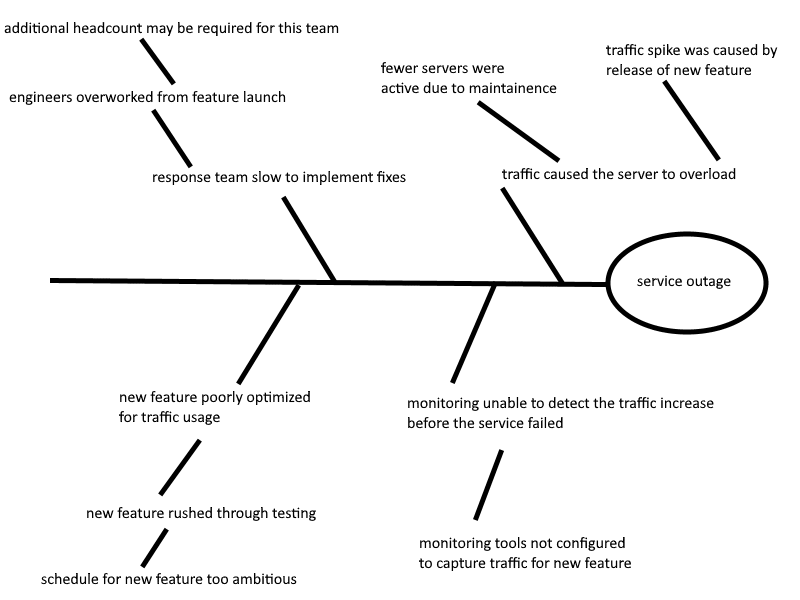
When digging for these factors, be holistic. Don’t just think about technical issues, but dive into problems with training, headcounts, stress, personal factors in engineers’ lives — anything that could have impacted how people work on your system. Pulling in management and other teams into these discussions could be necessary when reflecting on major incidents.
Of course, all this investigation should be done blamelessly. Assume everyone’s good faith and best intentions. If a mistake was made, look into what information or safeguards could have prevented it. Settling for punishing an individual will prevent you from making major systemic improvements.
5. Technical analysis
This is a section mostly for your engineering teams. If there’s factors in here that should be understood by non-engineers, be sure to provide that information and its impact somewhere else in the retrospective report. Here, you should be detailed enough that future engineers can get useful information when resolving future, similar incidents.
As you did with monitoring data, you should include information about how the code should work, and how it usually works. This context is important, as the intended function of the code may have changed by the time someone reviews it. You should also discuss how future development is expected to impact code in production. Knowing how the code is expected to run in production allows you to be keenly aware when incidents occur.
6. Followup actions
This is one of the most important parts of the retrospective. All of your learning about why the incident happened should transform into actions. Find ways to change the factors that lead to the incident. The retrospective can act as a hub for tracking these items. As you review the retrospective, check and make sure they’re progressing.
The followup actions don’t just have to address the direct causes of the incident. This is also an opportunity to improve your incident response policies, your tools of measuring the impact of incidents (like SLOs), your monitoring setup, even your retrospective standards! You can never be too holistic when solving problems.
To motivate people to work on these followup tasks, include some context. Summarize why each action was chosen after the incident. Also discuss the impact it will have in preventing future incidents. No one wants to spend time responding to the same, or similar incidents over and over. It’s not only soul-destroying for the team, which can quickly lead to burnout. It’s also not good for business. You should include enough information that people will understand the importance without having to reread the entire retrospective.
7. Narrative
Including a narrative summary of the incident is often overlooked. It won’t contain any new information, but it’s still useful. All of this information can be overwhelming, so use this part of the retrospective as a way to make the incident approachable for future study. Think about it in terms of a story. You start with describing things as they should be. Then you introduce the problem and how it disrupts the norm. Walk through the experience of the affected customers as well as the team that was tasked to solve the issue. You cover what they tried, what worked, and what they learned.
Rather than details, you should focus on impact in this section. How severe was the incident, and what made it so? When studying the incident later, many details will be irrelevant to the current system. However, understanding how people responded when things went very poorly will always be a useful lesson.

Top comments (0)