
Introducing GraphStarz
https://github.com/BryceEWatson/graph_starz
GraphStarz is an open-source application that combines AI-driven image analysis with a graph database to organize and explore your image collection. I created it to address a common problem: as our photo libraries grow, it becomes difficult to sort, tag, and find images manually. By leveraging AI, GraphStarz can automatically recognize attributes in images – such as objects, people, settings, style, and mood – and use those attributes to tag and relate images together. The motivation was to make image organization smarter and less labor-intensive, so you spend more time enjoying your photos instead of managing them.
At the heart of GraphStarz is a graph database that stores images as nodes with relationships linking them based on shared attributes or metadata. This approach allows the system to map complex many-to-many connections between photos in ways a traditional folder or relational database cannot. For example, if two images share a common tag like “beach” or were taken in the same location, they can be directly connected in the graph. This makes it easy to find all images of a certain theme or to traverse from one photo to related ones by following their links. Graph databases excel at queries that involve traversing relationships, enabling questions like “show me all images that have person X and were taken in location Y” – queries that would be cumbersome or even impossible with a standard relational approach.
What truly sets GraphStarz apart is its engaging graph-based user interface for navigation. Instead of clicking through folders or scrolling lists, you can visually explore your image network. Picture an interactive web of connected images: click on an image and see lines (edges) connecting to other related photos – perhaps ones with the same person, similar scenery, or a shared event. Navigating your library becomes a discoverable adventure; you might start at one photo and organically jump to related ones in a few clicks. This graph UI makes browsing more intuitive and fun, turning your image collection into a connected story rather than isolated snapshots. By combining AI-assisted tagging with graph-driven organization, GraphStarz delivers a novel experience for managing and exploring images that scales beyond what manual tagging could achieve.
Early Access
GraphStarz is currently in early access, with a controlled rollout to ensure the best possible experience as it grows. Access to the application is managed through a whitelist system. If you're interested in trying out GraphStarz and helping shape its development, I'd love to hear from you! You can reach out to request access, and I'll be happy to add you to the whitelist. This approach allows me to gather valuable feedback and insights from early users while maintaining a stable and responsive service.
Evolution of GraphStarz
GraphStarz began as a simple early prototype aimed at proving the core idea: that AI could automate image recognition and a graph structure could link related images. In the prototype, a basic image recognition model was used to analyze a handful of photos. This early version could identify various attributes in each image and assign tags. The results were promising – the prototype automatically grouped images by detected themes (like sunsets or pets) without any manual input. This validated the concept that an AI-powered system could meaningfully organize images on its own. However, the prototype was very minimal: just a small app running image classification on a set of files and outputting a basic form of relationship data. There was no friendly UI or robust database yet, just the building blocks of AI-driven tagging.
Encouraged by the prototype, I evolved the project into a more feature-rich, monolithic Next.js application. Next.js (a React framework) was used to build a unified web app that combined the front-end UI, back-end server logic, and even some AI processing into one cohesive codebase. In this monolithic architecture, when a user uploads an image, the Next.js server orchestrates all the steps in a controlled sequence: it calls the AI image recognition component, waits for the results (like detected tags, descriptions, style, and mood), then saves the image and its relationships into the graph database, and finally updates the UI. All these functions run under the umbrella of the Next.js app, which made development initially straightforward – one deployment contained everything needed for GraphStarz to work. This MVP (Minimum Viable Product) allows for end-to-end functionality: users can upload photos, have them auto-tagged, and browse connections via the graph UI, all within a single application.
Some interesting logic to check out:
- Image Analyzer contains the AI prompting and tool use logic that retrieves the image attributes.
- Upload API Route acts as the Orchestrator (to be replaced with Event Queue).
- Image Repository handles Neo4j database interactions
While the monolithic approach works for a small scale, it has real limitations as GraphStarz grows. One issue is scalability: a monolith means every part of the application is packaged together, so scaling up one aspect (say, the intensive AI analysis) means scaling the entire app. If many users upload images at once, the Next.js server has to handle multiple CPU-heavy image recognitions in addition to serving the web UI and database access. The only way to handle increased load is to run more copies of the whole application, which is inefficient. As the AWS architecture guidance notes, a monolithic app must often be scaled in its entirety even if only one component is the bottleneck, leading to resource wastage (Monolithic vs Microservices - Difference Between Software Development Architectures- AWS). Another problem is the tight coupling between components. All processes (upload handling, AI tagging, database writes, UI updates) are interwoven in one service, so a change to one part (like swapping out the AI model or modifying the database schema) could impact others. Even small changes require careful regression testing of the whole system, since everything is deployed together. This matches a known drawback of monoliths: a tiny update in one area can require redeploying the entire application and risk side effects elsewhere. The controlled orchestration within Next.js is becoming a double-edged sword – it ensures everything works in lockstep, but that also means if one part fails or slows down, it can affect the entire pipeline.
This phase has highlighted that while a monolithic design is great for a quick start, it can hold back scalability and flexibility once the application grows. GraphStarz's user experience – the graph UI and auto-tagging – has been well-received, but the backend architecture needs a rethink to support more users, more images, and more complex processing. I'm currently planning a major refactor that will transform GraphStarz into an event-driven architecture, which will provide a more robust and scalable foundation for the application's future.
Planning the Next Evolution: Event-Driven Architecture
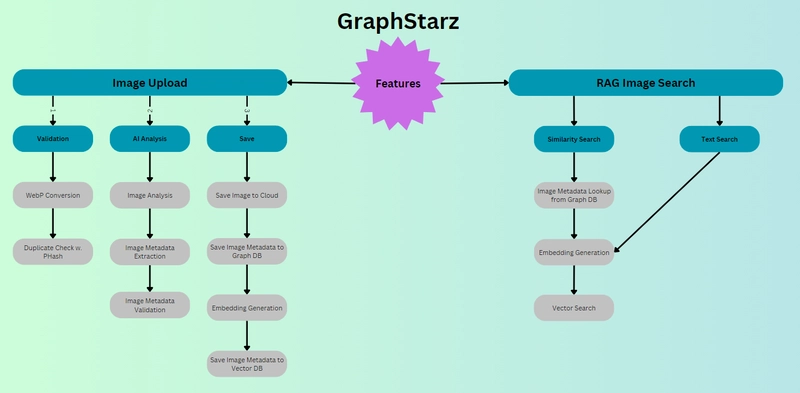
To address the shortcomings of the monolith, I'm planning to redesign GraphStarz into an event-driven, message-based architecture. In this new model, the tightly-coupled orchestration of the Next.js server will be replaced by a set of independent services that communicate through asynchronous events. This transformation, illustrated in the Scalable MVP roadmap diagram (see attached images), shows how GraphStarz will move from a single-process sequence to a distributed pipeline of processing stages. The shift will bring numerous advantages in terms of loose coupling, scalability, reliability, and fault tolerance.
In an event-driven architecture, components (services) don’t call each other directly or wait on each other; instead, they publish events or messages to a message broker, and other components subscribe to those events. This decoupling means each service can run and scale independently. If we compare the approaches: previously, the Next.js app would call the image AI function and then the database in a linear fashion (synchronous calls). Now, when an image is uploaded, the upload service simply emits an “Image Uploaded” event into a message queue and immediately moves on. A dedicated consumer service listening for that event (say, a validation service) will pick it up, process it, then emit its own event like “Image Validated”. Another service (the AI analyzer) subscribed to “Image Validated” events will grab it, do the heavy AI work, then emit “Image Analyzed” with the results. Finally, a saving service will consume the analyze event and save the data to the graph database. Each stage is autonomous and connected only by the flow of messages, not by direct code calls.
This loose coupling yields multiple benefits. Components are isolated – the AI analysis engine knows nothing about how the UI works or how the data will be stored, it just processes an image and emits a result event. Because of this, services can be scaled out or updated independently. If image analysis is a bottleneck, we can run multiple instances of that service without touching the others. If a service crashes or needs a restart, it doesn’t bring down the whole system – incoming messages will wait in the queue until a consumer is ready again, which improves fault tolerance. As Amazon’s architecture guide notes, an event-driven (decoupled) system makes it easier to scale and update components independently, and one service can fail without cascading to others (What is EDA? - Event Driven Architecture Explained - AWS). The workflow also becomes more reliable: messages can be persisted in the broker, so if there’s a spike in load, they queue up rather than overwhelming the app, and they won’t be lost even if a service is temporarily down. In short, GraphStarz can handle more users and more images gracefully by horizontally scaling its processing pipeline. The attached architecture diagram from the roadmap visually contrasts the old and new designs – where the monolith was a single box doing all tasks sequentially, the new event-driven model is a chain of discrete nodes (services) each connected by message queues, creating a streamlined assembly line for image processing.
Key Architectural Decisions and Components:
RabbitMQ over Kafka as the Message Broker: GraphStarz chose RabbitMQ to drive its event messaging. RabbitMQ is a mature, general-purpose message broker known for its reliability and support for complex routing, which fits the needs of coordinating image processing tasks. It provides low-latency message delivery and is excellent for handling background jobs and orchestrating workflows between microservices (When to use RabbitMQ or Apache Kafka - CloudAMQP). In contrast, Apache Kafka – another popular choice – is designed for high-throughput streaming of massive data (a distributed log of events). Kafka is powerful, but can be overkill for an application like GraphStarz which needs more straightforward task queuing and doesn’t initially deal with firehose-level event streams. I opted for RabbitMQ to keep the system simpler and because it natively supports features like work queues and routing keys that align with the processing stages they needed. (Indeed, RabbitMQ’s common use case is acting as a message broker between microservices and handling background tasks, whereas Kafka excels at heavy continuous data streams and replay scenarios (When to use RabbitMQ or Apache Kafka - CloudAMQP).) This choice helps GraphStarz achieve the needed throughput and reliability without adding unnecessary complexity.
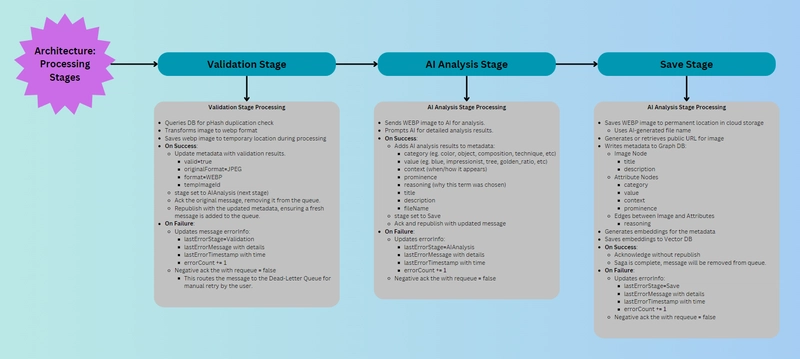
Robust Queue Strategy (Acknowledgments and Dead-Letter Queues): With RabbitMQ as the broker, the architecture employs a careful queue management strategy to ensure reliability. Each message (for example, “process this image”) is only removed from the queue when a worker service has completed its task and manually acknowledges the message. This manual acknowledgment means if a service crashes or fails before finishing, the message stays in the queue (or is requeued) so no image job gets lost. Furthermore, GraphStarz uses dead-letter queues for error handling: if a message cannot be processed after a certain number of attempts or triggers an exception in a consumer, it is routed to a special dead-letter queue. This prevents problematic messages from clogging the main queue and allows the team to inspect and debug failures separately. For instance, if the AI analysis service consistently fails on a certain image (say the image file is corrupted), that message can be shuttled to a dead-letter queue after a few retries. This way, normal processing continues for other images, and the problematic data can be reviewed later. These queue strategies greatly improve the system’s fault tolerance – the pipeline is resilient to individual failures and can recover or isolate them without stopping the whole system.
Asynchronous Processing Pipeline (Validation → AI Analysis → Save): The new GraphStarz backend is organized into stages, each handled by independent consumers that communicate via RabbitMQ messages. The stages include: 1) Validation Service: when an image upload event is received, this service verifies the payload (e.g., checks the image format, size, perhaps scans for duplicates or inappropriate content). It ensures that only valid data proceeds. Once done, it emits an “Image Validated” event into the next queue. 2) AI Analysis Service: this service listens for validated events. Upon receiving one, it loads the image (e.g., from storage) and runs AI algorithms on it – this could involve calling a computer vision model to detect objects, recognize faces or landmarks, extract color themes, or generate descriptive keywords. The output might be a set of tags or a vector embedding representing the image’s content. After successful analysis, it emits an “Image Analyzed” event along with the extracted metadata. 3) Save/Database Service: listening for analyzed events, this component takes the AI results and updates the GraphStarz database. It creates or updates the image node in the graph DB, adds relationships (for example, linking the image node to “Person: Alice” node because Alice was recognized in the photo, or to a “Location: Paris” node because the Eiffel Tower was detected). It may also store the raw metadata or thumbnails as needed. Once saved, the image is fully indexed in the graph, and the front-end can be notified (either via another event or by pulling updates) that a new image and its connections are available for browsing. All these stages run asynchronously – the validation service can be working on image1 while the analysis service is busy with image0, and meanwhile the save service might be handling image-1’s data. They are decoupled and connected only through the message broker, which acts as the intermediary carrying outputs of one stage as inputs to the next. This design allows each stage to be scaled (e.g., if AI analysis is the slowest, we can run multiple analyzers in parallel consuming from the same queue). It also adds reliability – if one stage falls behind, the message queue buffers the backlog so that no data is lost, just processed a bit later. The Scalable MVP architecture diagram shows this pipeline structure clearly: instead of one component doing everything, you see a chain of specialized workers and RabbitMQ queues gluing them together. This modular pipeline is the core of GraphStarz’s new scalable architecture.
Overall, the event-driven revamp will make GraphStarz much more scalable and robust. The loose coupling and message-driven flow mean the app can handle higher loads and be extended more easily. New processing stages can be added by simply introducing new event types and consumers, without rewriting the whole system. The comparison between the old orchestrated approach and the new event-driven model (as depicted in the attached roadmap diagrams) underscores a classic trade-off in software design: the monolithic approach was easier to get started (everything in one place), whereas the event-driven microservices approach is a bit more complex to set up but pays off with flexibility and reliability. As one reference on software architecture succinctly puts it, loose coupling in event-driven systems yields scalability and fault tolerance as a free benefit (3 benefits of event-driven architecture | MuleSoft Blog). GraphStarz’s journey to this architecture will pave the way for the next phase of its growth.
Future Vision and Scalability
Once the new event-driven architecture is implemented, GraphStarz will be poised to scale rapidly as adoption increases. If the user base suddenly grows or a big batch of images needs processing, the system will be able to meet the demand by spinning up more instances of the planned services. For example, suppose a thousand users all upload photos around the same time – RabbitMQ will dutifully queue all those tasks, and we could increase the number of AI analysis worker processes to handle the surge in parallel. Each microservice (validation, analysis, saving, etc.) will be able to scale horizontally without affecting the others, which means the app can elastically grow its throughput. Modern container orchestration tools (like Kubernetes or Docker Swarm) could be used to manage these services, enabling auto-scaling rules (e.g., if the queue length grows, start more consumers). Because each component will be independent, bottlenecks can be addressed in isolation – maybe image analysis needs GPU-powered instances to speed it up, while the web front-end just needs more ordinary servers to handle user requests. The planned architecture will support this tailored scaling, ensuring that GraphStarz remains responsive even under heavy load. This positions the project well for increased adoption: whether it's a small community of photographers or a large enterprise using it to catalog images, the backend will be able to grow to meet the need.
Looking ahead, I envision several enhancements that build on the current foundation:
More Advanced AI Analysis: The initial AI capabilities might focus on basic object detection and tagging, but there’s huge potential to incorporate more sophisticated image understanding. Future versions could use advanced vision AI models (such as deep CNNs or Vision Transformers) to recognize not just objects, but also actions, contexts, and even specific people (with user consent). GraphStarz could integrate face recognition to identify people who appear across your photos, or scene understanding models to classify events (birthday parties, beach trips, etc.). Another avenue is generating captions or descriptions for images using image-to-text models, which could then be stored as nodes or attributes in the graph (enabling semantic search). The graph database can capture these richer annotations by linking images to a wider variety of nodes (people, places, activities, objects, themes, and so on). With more AI power, GraphStarz will become an even smarter assistant that not only groups photos by obvious tags but can surface subtle connections (e.g., “these photos all have a similar style or mood”). Since the architecture is modular, plugging in a new AI service or model is straightforward – a new analysis microservice could be added to the pipeline to perform, say, image aesthetic scoring or duplicate photo detection, posting its results back into the graph.
Deeper Integrations with Other Tools: The future of GraphStarz could see it playing well with other AI and data systems. For instance, integration with voice or chatbot assistants would allow users to query their image collection in natural language (“GraphStarz, show me all pictures of Alice at the beach last summer”). This would involve linking a language understanding component (perhaps using an NLP or GPT-based service) with the graph query engine – exactly the kind of cross-service communication that the event-driven design can accommodate. Another idea is connecting GraphStarz with external knowledge graphs or location datasets: if a landmark is recognized in a photo, GraphStarz could fetch information about it (from Wikipedia or a knowledge graph) and attach context to the image node. Or it might integrate with cloud storage providers and their AI APIs, letting users import images from Google Photos or Dropbox and enriching those with GraphStarz’s own analysis. Cross-domain AI integration (like combining image data with text data or sensor data) could lead to new features – imagine correlating photos with calendar events or social media posts by time and place, creating a broader “memory graph.” The scalable architecture means adding these integrations can be done by adding new event producers/consumers that interface with external APIs, without rewriting the core.
Enhanced Graph Navigation and UI: On the front-end side, there’s a vision to make the graph-based UI even more powerful and user-friendly. This might include features like timeline views, filters on the graph (to highlight specific relationships like location-based connections or people-based connections), or even AR/VR style exploration of your photo graph. While UI/UX is a different concern than backend architecture, the backend’s ability to quickly query and deliver relationship data (thanks to the graph DB) will support a snappy and rich interface. The team may incorporate more of the graph database’s capabilities, such as graph algorithms to find clusters of similar images or the shortest path between two images (e.g., how is image A related to image B?). These would give users unique insights into their collections (perhaps discovering that two friends who never met both appear in photos with you at the same venue, connecting through that place node). The future could also bring collaboration features – letting multiple users’ photo collections merge or link graphs (with permissions), thereby connecting memories across people. With the robust backend, GraphStarz can scale to accommodate these heavier query loads and new usage patterns.
In essence, the new architecture is not just about handling more load; it’s about providing a flexible platform for rapid innovation. If GraphStarz gains a surge of users, I can respond by scaling out services and know the system will hold up. And as new ideas for features or integrations come up, the modular design means they can be developed and deployed as new services or modules without disturbing the existing system. The project is on a path where growth – both in user base and in functionality – is supported by solid engineering. The roadmap ahead is exciting: GraphStarz aims to become a comprehensive AI-powered image relationship platform, and with this scalable architecture in place, it has the runway to get there.

Join the Journey
I'm excited about the future of GraphStarz and would love to have you join me on this journey! Whether you're interested in AI, graph databases, or scalable architectures, there are many interesting challenges to tackle. As a solo developer (with some amazing design help!), I welcome any contributions, feedback, or expertise you'd like to share. Feel free to check out the project on GitHub, try it out, or reach out if you'd like to collaborate. Your insights could help shape the next evolution of GraphStarz!

Top comments (1)
Some comments may only be visible to logged-in visitors. Sign in to view all comments.