
Introduction
When it comes to running applications on Kubernetes in production, you will sooner or later have the challenge to update your services with a minimum amount of downtime for your users…and – at least as important – to be able to release new versions of your application with confidence…that means, you discover unhealthy and “faulty” services very quickly and are able to rollback to previous versions without much effort.
When you search the internet for best practices or Kubernetes addons that help you with these challenges, you will stumble upon Flagger, as I did, from WeaveWorks.
Flagger is basically a controller that will be installed in your Kubernetes cluster. It helps you with canary and A/B releases of your services by handling all the hard stuff like automatically adding services and deployments for your “canaries”, shifting load over time to these and rolling back deployments in case of errors.
As if that wasn’t good enough, Flagger also works in combination with popular Service Meshes like Istio and Linkerd. If you don’t want to use Flagger with such a product, you can also use it on “plain” Kubernetes, e.g. in combination with an NGINX ingress controller. Many choices here…
I like linkerd very much, so I’ll choose that one in combination with Flagger to demonstrate a few of the possibilities you have when releasing new versions of your application/services.
Prerequisites
linkerd
I already set up a plain Kubernetes cluster on Azure for this sample, so I’ll start by adding linkerd to it (you can find a complete guide how to install linkerd and the CLI on https://linkerd.io/2/getting-started/):
$ linkerd install | kubectl apply -f -
After the command has finished, let’s check if everything works as expected:
$ linkerd check && kubectl -n linkerd get deployments
[...]
[...]
control-plane-version
---------------------
√ control plane is up-to-date
√ control plane and cli versions match
Status check results are √
NAME READY UP-TO-DATE AVAILABLE AGE
flagger 1/1 1 1 3h12m
linkerd-controller 1/1 1 1 3h14m
linkerd-destination 1/1 1 1 3h14m
linkerd-grafana 1/1 1 1 3h14m
linkerd-identity 1/1 1 1 3h14m
linkerd-prometheus 1/1 1 1 3h14m
linkerd-proxy-injector 1/1 1 1 3h14m
linkerd-sp-validator 1/1 1 1 3h14m
linkerd-tap 1/1 1 1 3h14m
linkerd-web 1/1 1 1 3h14m
If you want to, open the linkerd dashboard and see the current state of your service mesh, execute:
$ linkerd dashboard
After a few seconds, the dashboard will be shown in your browser.
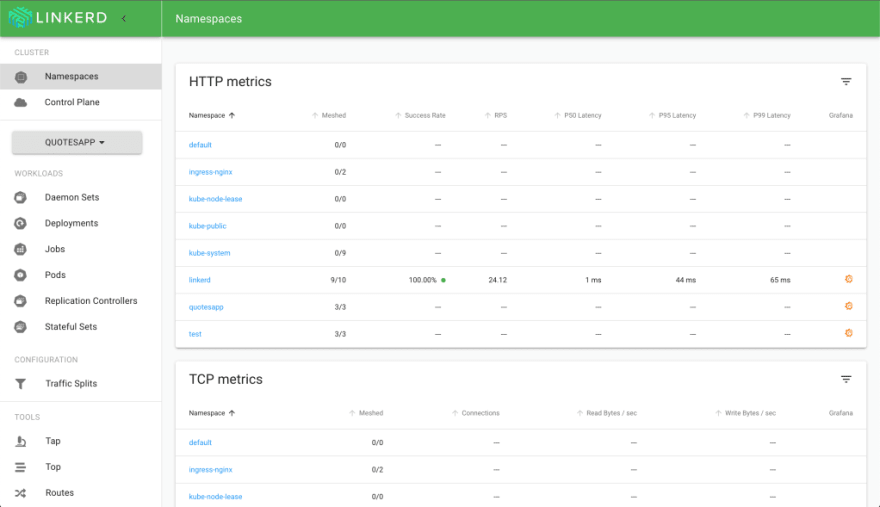
Microsoft Teams Integration
For alerting and notification, we want to leverage the MS Teams integration of Flagger to get notified each time a new deployment is triggered or a canary release will be “promoted” to be the primary release.
Therefore, we need to setup a WebHook in MS Teams (a MS Teams channel!):
- In Teams, choose More options ( ⋯ ) next to the channel name you want to use and then choose Connectors.
- Scroll through the list of Connectors to Incoming Webhook , and choose Add.
- Enter a name for the webhook, upload an image and choose Create.
- Copy the webhook URL. You’ll need it when adding Flagger in the next section.
- Choose Done.
Install Flagger
Time to add Flagger to your cluster. Therefore, we will be using Helm (version 3, so no need for a Tiller deployment upfront).
$ helm repo add flagger https://flagger.app
$ kubectl apply -f https://raw.githubusercontent.com/weaveworks/flagger/master/artifacts/flagger/crd.yaml
[...]
$ helm upgrade -i flagger flagger/flagger \
--namespace=linkerd \
--set crd.create=false \
--set meshProvider=linkerd \
--set metricsServer=http://linkerd-prometheus:9090 \
--set msteams.url=<YOUR_TEAMS_WEBHOOK_URL>
Check, if everything has been installed correctly:
$ kubectl get pods -n linkerd -l app.kubernetes.io/instance=flagger
NAME READY STATUS RESTARTS AGE
flagger-7df95884bc-tpc5b 1/1 Running 0 0h3m
Great, looks good. So, now that Flagger has been installed, let’s have a look where it will help us and what kind of objects will be created for canary analysis and promotion. Remember that we use linkerd in that sample, so all objects and features discussed in the following section will just be relevant for linkerd.
How Flagger works
The sample application we will be deploying shortly consists of a VueJS Single Page Application that is able to display quotes from the Star Wars movies – and it’s able to request the quotes in a loop (to be able to put some load on the service). When requesting a quote, the web application is talking to a service (proxy) within the Kubernetes cluster which in turn talks to another service (quotesbackend) that is responsible to create the quote (simulating service-to-service calls in the cluster). The SPA as well as the proxy are accessible through a NGINX ingress controller.
After the application has been successfully deployed, we also add a canary object which takes care of the promotion of a new revision of our backend deployment. The Canary object will look like this:
apiVersion: flagger.app/v1beta1
kind: Canary
metadata:
name: quotesbackend
spec:
targetRef:
apiVersion: apps/v1
kind: Deployment
name: quotesbackend
progressDeadlineSeconds: 60
service:
port: 3000
targetPort: 3000
analysis:
interval: 20s
# max number of failed metric checks before rollback
threshold: 5
# max traffic percentage routed to canary
# percentage (0-100)
maxWeight: 70
stepWeight: 10
metrics:
- name: request-success-rate
# minimum req success rate (non 5xx responses)
# percentage (0-100)
threshold: 99
interval: 1m
- name: request-duration
# maximum req duration P99
# milliseconds
threshold: 500
interval: 30s
What this configuration basically does is watching for new revisions of a quotesbackend deployment. In case that happens, it starts a canary deployment for it. Every 20s, it will increase the weight of the traffic split by 10% until it reaches 70%. If no errors occur during the promotion, the new revision will be scaled up to 100% and the old version will be scaled down to zero, making the canary the new primary. Flagger will monitor the request success rate and the request duration (linkerd Prometheus metrics). If one of them drops under the threshold set in the Canary object, a rollback to the old version will be started and the new deployment will be scaled back to zero pods.
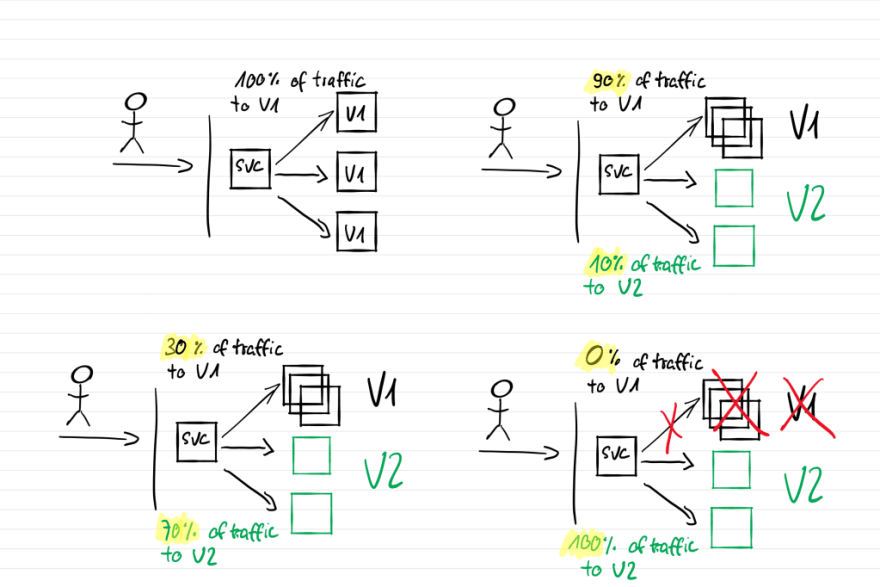
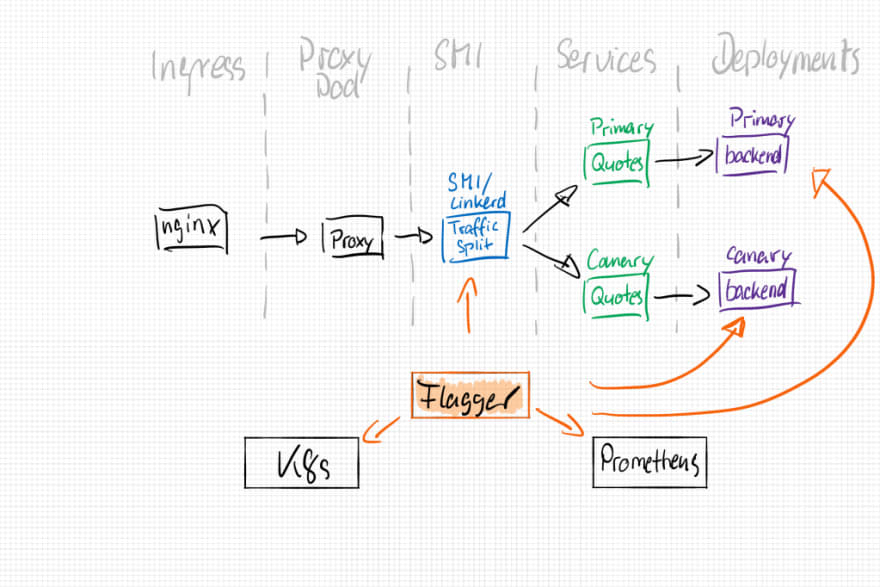
To achieve all of the above mentioned analysis, flagger will create several new objects for us:
- backend-primary deployment
- backend-primary service
- backend-canary service
- SMI / linkerd traffic split configuration
The resulting architecture will look like that:
So, enough of theory, let’s see how Flagger works with the sample app mentioned above.
Sample App Deployment
If you want to follow the sample on your machine, you can find all the code snippets, deployment manifests etc. on https://github.com/cdennig/flagger-linkerd-canary
First, we will deploy the application in a basic version. This includes the backend and frontend components as well as an Ingress Controller which we can use to route traffic into the cluster (to the SPA app + backend services). We will be using the NGINX ingress controller for that.
To get started, let’s create a namespace for the application and deploy the ingress controller:
$ kubectl create ns quotes
# Enable linkerd integration with the namespace
$ kubectl annotate ns quotes linkerd.io/inject=enabled
# Deploy ingress controller
$ helm repo add ingress-nginx https://kubernetes.github.io/ingress-nginx
$ kubectl create ns ingress
$ helm install my-ingress ingress-nginx/ingress-nginx -n ingress
Please note , that we annotate the quotes namespace to automatically get the Linkerd sidecar injected during deployment time. Any pod that will be created within this namespace, will be part of the service mesh and controlled via Linkerd.
As soon as the first part is finished, let’s get the public IP of the ingress controller. We need this IP address to configure the endpoint to call for the VueJS app, which in turn is configured in a file called settings.js of the frontend/Single Page Application pod. This file will be referenced when the index.html page gets loaded. The file itself is not present in the Docker image. We mount it during deployment time from a Kubernetes secret to the appropriate location within the running container.
One more thing : To have a proper DNS name to call our service (instead of using the plain IP), I chose to use NIP.io. The service is dead simple! E.g. you can simply use the DNS name 123-456-789-123.nip.io and the service will resolve to host with IP 123.456.789.123. Nothing to configure, no more editing of /etc/hosts…
So first, let’s determine the IP address of the ingress controller…
# get the IP address of the ingress controller...
$ kubectl get svc -n ingress
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
my-ingress-ingress-nginx-controller LoadBalancer 10.0.93.165 52.143.30.72 80:31347/TCP,443:31399/TCP 4d5h
my-ingress-ingress-nginx-controller-admission ClusterIP 10.0.157.46 <none> 443/TCP 4d5h
Please open the filesettings_template.js and adjust the endpoint property to point to the cluster (in this case, the IP address is 52.143.30.72, so the DNS name will be 52-143-30-72.nip.io).
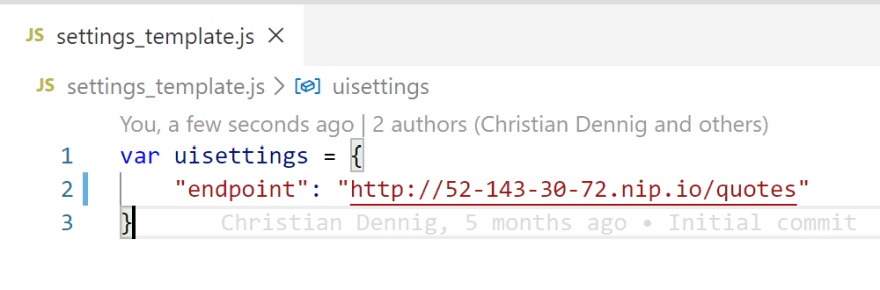
Next, we need to add the correspondig Kubernetes secret for the settings file:
$ kubectl create secret generic uisettings --from-file=settings.js=./settings_template.js -n quotes
As mentioned above, this secret will be mounted to a special location in the running container. Here’s the deployment file for the frontend – please see the sections for volumes and volumeMounts:
apiVersion: apps/v1
kind: Deployment
metadata:
name: quotesfrontend
spec:
selector:
matchLabels:
name: quotesfrontend
quotesapp: frontend
version: v1
replicas: 1
minReadySeconds: 5
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
template:
metadata:
labels:
name: quotesfrontend
quotesapp: frontend
version: v1
spec:
containers:
- name: quotesfrontend
image: csaocpger/quotesfrontend:4
volumeMounts:
- mountPath: "/usr/share/nginx/html/settings"
name: uisettings
readOnly: true
volumes:
- name: uisettings
secret:
secretName: uisettings
Last but not least, we also need to adjust the ingress definition to be able to work with the DNS / hostname. Open the file ingress.yaml and adjust the hostnames for the two ingress definitions. In this case here, the resulting manifest looks like that:

Now we are set to deploy the whole application:
$ kubectl apply -f base-backend-infra.yaml -n quotes
$ kubectl apply -f base-backend-app.yaml -n quotes
$ kubectl apply -f base-frontend-app.yaml -n quotes
$ kubectl apply -f ingress.yaml -n quotes
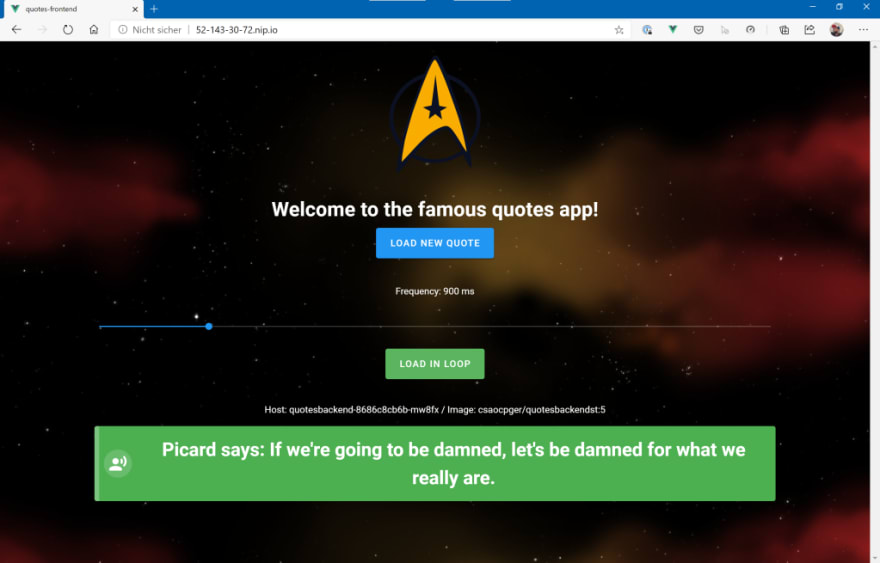
After a few seconds, you should be able to point your browser to the hostname and see the “Quotes App”:
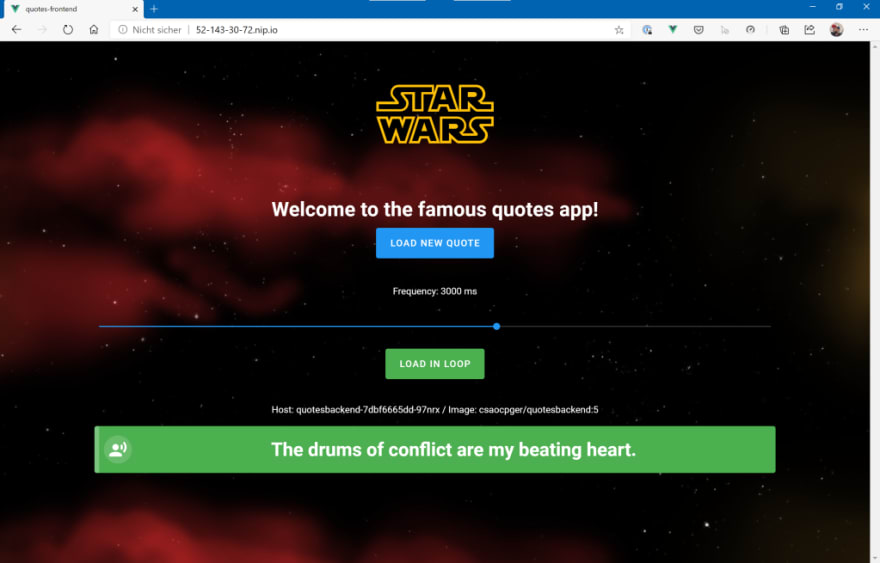
If you click on the “Load new Quote” button, the SPA will call the backend (here: http://52-143-30-72.nip.io/quotes), request a new “Star Wars” quote and show the result of the API Call in the box at the bottom. You can also request quotes in a loop – we will need that later to simulate load.
Flagger Canary Settings
We need to configure Flagger and make it aware of our deployment – remember, we only target the backend API that serves the quotes.
Therefor, we deploy the canary configuration (canary.yaml file) discussed before:
$ kubectl apply -f canary.yaml -n quotes
You have to wait a few seconds and check the services, deployments and pods to see if it has been correctly installed:
$ kubectl get svc -n quotes
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
quotesbackend ClusterIP 10.0.64.206 <none> 3000/TCP 51m
quotesbackend-canary ClusterIP 10.0.94.94 <none> 3000/TCP 70s
quotesbackend-primary ClusterIP 10.0.219.233 <none> 3000/TCP 70s
quotesfrontend ClusterIP 10.0.111.86 <none> 80/TCP 12m
quotesproxy ClusterIP 10.0.57.46 <none> 80/TCP 51m
$ kubectl get po -n quotes
NAME READY STATUS RESTARTS AGE
quotesbackend-primary-7c6b58d7c9-l8sgc 2/2 Running 0 64s
quotesfrontend-858cd446f5-m6t97 2/2 Running 0 12m
quotesproxy-75fcc6b6c-6wmfr 2/2 Running 0 43m
kubectl get deploy -n quotes
NAME READY UP-TO-DATE AVAILABLE AGE
quotesbackend 0/0 0 0 50m
quotesbackend-primary 1/1 1 1 64s
quotesfrontend 1/1 1 1 12m
quotesproxy 1/1 1 1 43m
That looks good! Flagger has created new services, deployments and pods for us to be able to control how traffic will be directed to existing/new versions of our “quotes” backend. You can also check the canary definition in Kubernetes, if you want:
$ kubectl describe canaries -n quotes
Name: quotesbackend
Namespace: quotes
Labels: <none>
Annotations: API Version: flagger.app/v1beta1
Kind: Canary
Metadata:
Creation Timestamp: 2020-06-06T13:17:59Z
Generation: 1
Managed Fields:
API Version: flagger.app/v1beta1
[...]
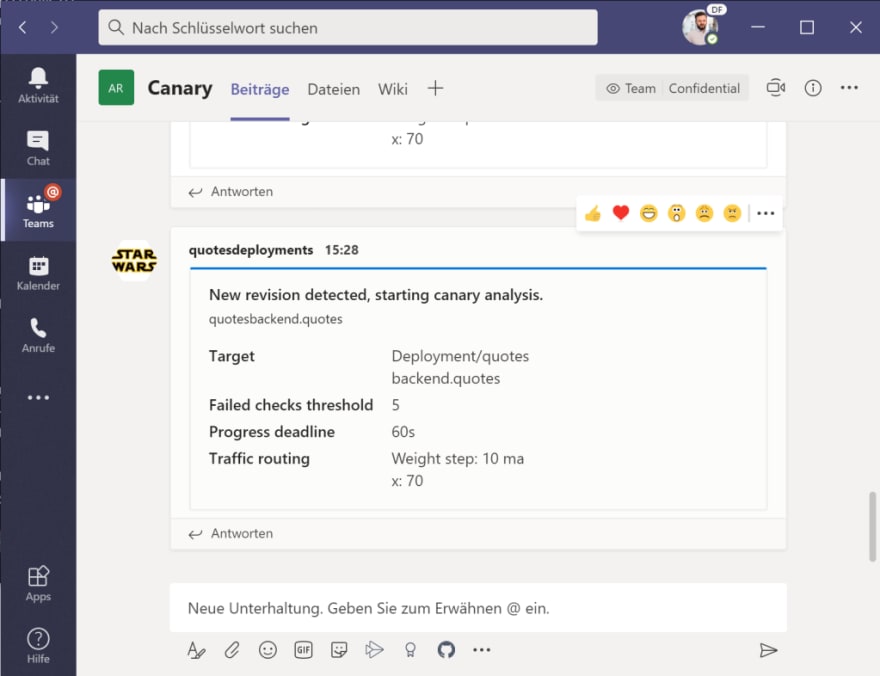
You will also receive a notification in Teams, that a new deployment for Flagger has been detected and initialized:
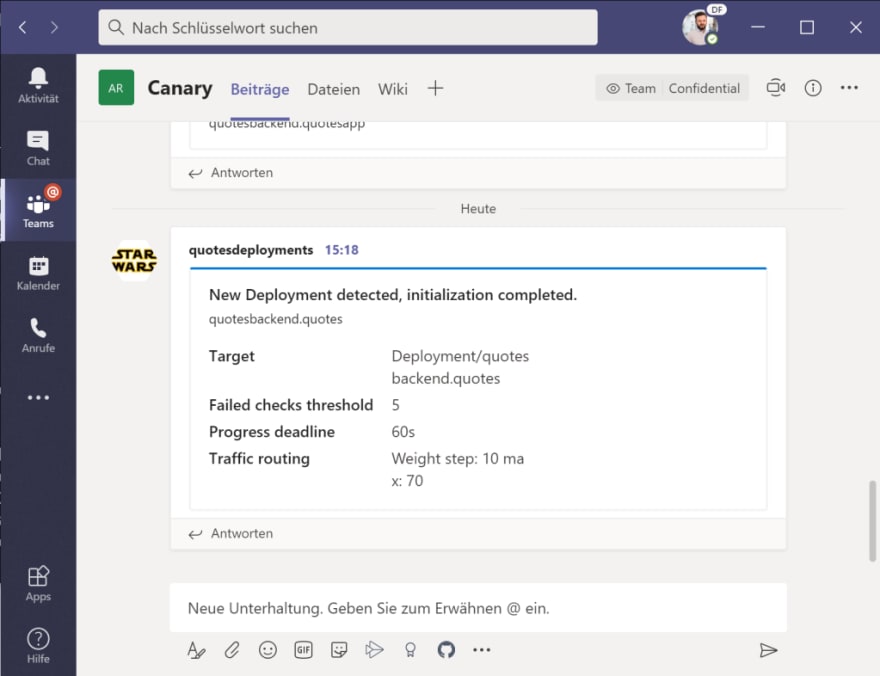
Kick-Off a new deployment
Now comes the part where Flagger really shines. We want to deploy a new version of the backend quote API – switching from “Star Wars ” quotes to “Star Trek ” quotes! What will happen, is the following:
- as soon as we deploy a new “quotesbackend”, Flagger will recognize it
- new versions will be deployed, but no traffic will be directed to them at the beginning
- after some time, Flagger will start to redirect traffic via Linkerd / TrafficSplit configurations to the new version via the canary service, starting – according to our canary definition – at a rate of 10%. So 90% of the traffic will still hit our “Star Wars” quotes
- it will monitor the request success rate and advance the rate by 10% every 20 seconds
- if 70% traffic split will be reached without throwing any significant amount of errors, the deployment will be scaled up to 100% and propagated as the “new primary”
Before we deploy it, let’s request new quotes in a loop (set the frequency e.g. to 300ms via the slider and press “Load in Loop”).
Then, deploy the new version:
$ kubectl apply -f st-backend-app.yaml -n quotes
$ kubectl describe canaries quotesbackend -n quotes
[...]
[...]
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning Synced 14m flagger quotesbackend-primary.quotes not ready: waiting for rollout to finish: observed deployment generation less then desired generation
Normal Synced 14m flagger Initialization done! quotesbackend.quotes
Normal Synced 4m7s flagger New revision detected! Scaling up quotesbackend.quotes
Normal Synced 3m47s flagger Starting canary analysis for quotesbackend.quotes
Normal Synced 3m47s flagger Advance quotesbackend.quotes canary weight 10
Warning Synced 3m7s (x2 over 3m27s) flagger Halt advancement no values found for linkerd metric request-success-rate probably quotesbackend.quotes is not receiving traffic: running query failed: no values found
Normal Synced 2m47s flagger Advance quotesbackend.quotes canary weight 20
Normal Synced 2m27s flagger Advance quotesbackend.quotes canary weight 30
Normal Synced 2m7s flagger Advance quotesbackend.quotes canary weight 40
Normal Synced 107s flagger Advance quotesbackend.quotes canary weight 50
Normal Synced 87s flagger Advance quotesbackend.quotes canary weight 60
Normal Synced 67s flagger Advance quotesbackend.quotes canary weight 70
Normal Synced 7s (x3 over 47s) flagger (combined from similar events): Promotion completed! Scaling down quotesbackend.quotes
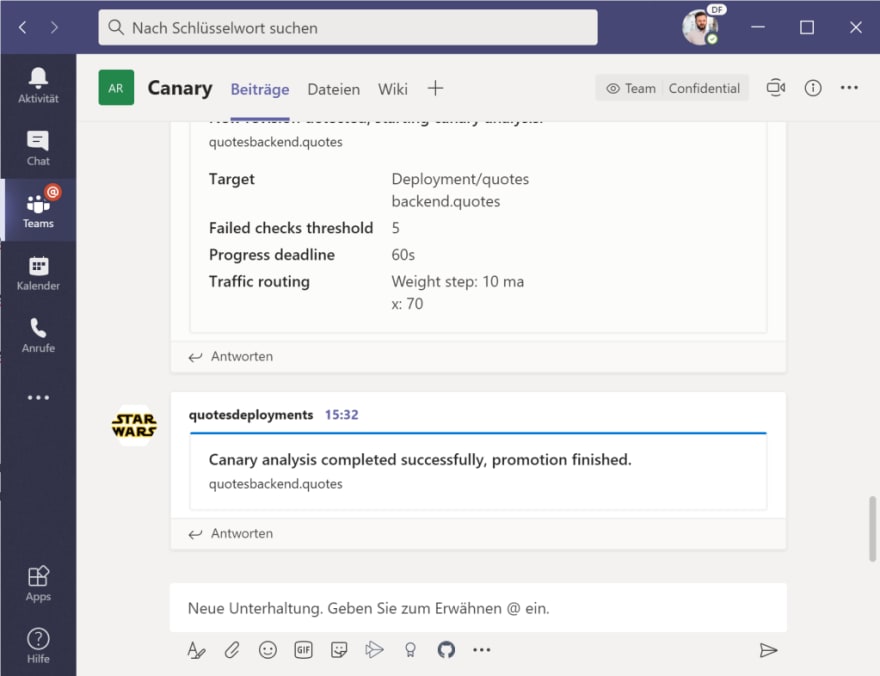
You will notice in the UI that every now and then a quote from “Star Trek” will appear…and that the frequency will increase every 20 seconds as the canary deployment will receive more traffic over time. As stated above, when the traffic split reaches 70% and no errors occured in the meantime, the “canary/new version” will be promoted as the “new primary version” of the quotes backend. At that time, you will only receive quotes from “Star Trek”.
Because of the Teams integration, we also get a notification of a new version that will be rolled-out and – after the promotion to “primary” – that the rollout has been successfully finished.
What happens when errors occur?
So far, we have been following the “happy path”…but what happens, if there are errors during the rollout of a new canary version? Let’s say we have produced a bug in our new service that will throw an error when requesting a new quote from the backend? Let’s see, how Flagger will behave then…
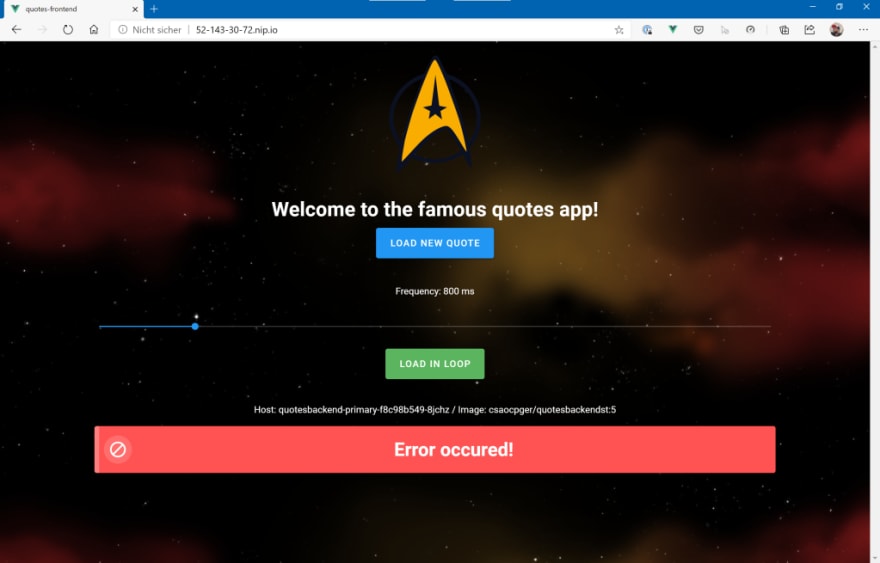
The version that will be deployed will start throwing errors after a certain amount of time. Due to the fact that Flagger is monitoring the “request success rate” via Linkerd metrics, it will notice that something is “not the way it is supposed to be”, stop the promotion of the new “error-prone” version, scale it back to zero pods and keep the current primary backend (means: “Star Trek” quotes) in place.
$ kubectl apply -f error-backend-app.yaml -n quotes
$ k describe canaries.flagger.app quotesbackend
[...]
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning Synced 23m flagger quotesbackend-primary.quotes not ready: waiting for rollout to finish: observed deployment generation less then desired generation
Normal Synced 23m flagger Initialization done! quotesbackend.quotes
Normal Synced 13m flagger New revision detected! Scaling up quotesbackend.quotes
Normal Synced 11m flagger Advance quotesbackend.quotes canary weight 20
Normal Synced 11m flagger Advance quotesbackend.quotes canary weight 30
Normal Synced 11m flagger Advance quotesbackend.quotes canary weight 40
Normal Synced 10m flagger Advance quotesbackend.quotes canary weight 50
Normal Synced 10m flagger Advance quotesbackend.quotes canary weight 60
Normal Synced 10m flagger Advance quotesbackend.quotes canary weight 70
Normal Synced 3m43s (x4 over 9m43s) flagger (combined from similar events): New revision detected! Scaling up quotesbackend.quotes
Normal Synced 3m23s (x2 over 12m) flagger Advance quotesbackend.quotes canary weight 10
Normal Synced 3m23s (x2 over 12m) flagger Starting canary analysis for quotesbackend.quotes
Warning Synced 2m43s (x4 over 12m) flagger Halt advancement no values found for linkerd metric request-success-rate probably quotesbackend.quotes is not receiving traffic: running query failed: no values found
Warning Synced 2m3s (x2 over 2m23s) flagger Halt quotesbackend.quotes advancement success rate 0.00% < 99%
Warning Synced 103s flagger Halt quotesbackend.quotes advancement success rate 50.00% < 99%
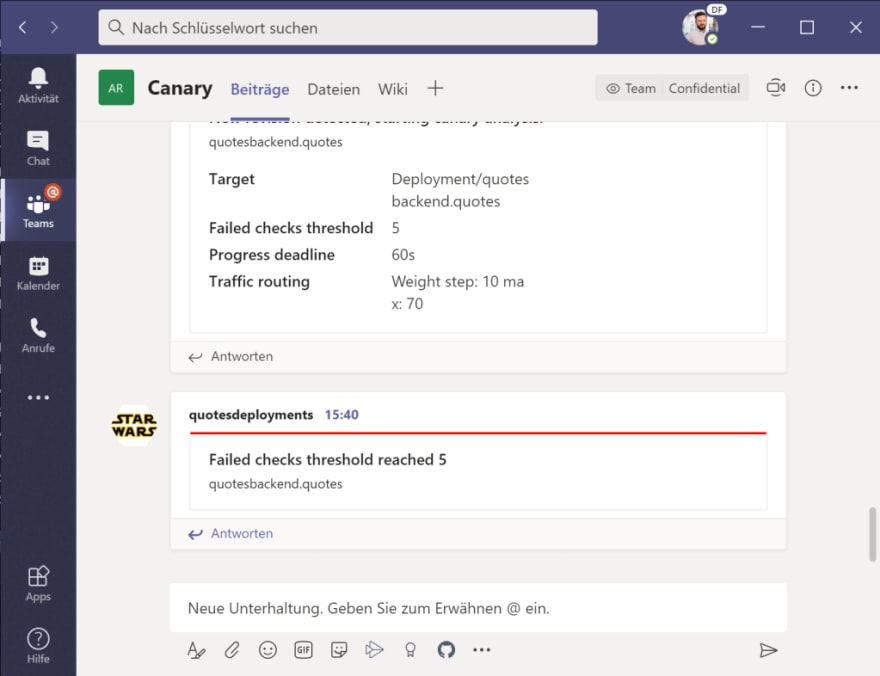
Warning Synced 83s flagger Rolling back quotesbackend.quotes failed checks threshold reached 5
Warning Synced 81s flagger Canary failed! Scaling down quotesbackend.quotes
As you can see in the event log, the success rate drops to a significant amount and Flagger will halt the promotion of the new version, scale down to zero pods and keep the current version a the “primary” backend.
Conclusion
With this article, I have certainly only covered the features of Flagger in a very brief way. But this small example shows what a great relief Flagger can be when it comes to the rollout of new Kubernetes deployments. Flagger can do a lot more than shown here and it is definitely worth to take a look at this product from WeaveWorks.
I hope I could give some insight and made you want to do more…and to have fun with Flagger :)
As mentioned above, all the sample files, manifests etc. can be found here: https://github.com/cdennig/flagger-linkerd-canary.

Top comments (0)