
Introduction
The vast majority of data science projects are born into Jupyter Notebooks. Being interactive and easy to use, they make exploratory data analysis (EDA) so convenient. They are also widely used for further steps such as machine learning model development, performance assessment, hyper-parameter tuning, among others. However, as the project makes progress and the deployment scenarios are under investigation, notebooks start to suffer in terms of versioning, reproducibility, interoperability, file type issues, etc. In other words, as the project moves from isolated local environments to common ones, one needs more software engineering oriented tools than data science specific ones. At this point, some of the DevOps practices can contribute.
A common and inevitable best practice of modern software development is using version control, In daily practice, it is almost equivalent to use git. It helps switching among different versions of files. However, it has limitations where the file size limit and file type compatibility are the major ones. One can conduct version control of .py or .ipynb files conveniently. However, versioning a dataset in size of couple of hundred megabytes or a file in .bit format is not possible or convenient with git. At this point, a free and open source tool, namely Data Version Control (DVC) by iterative.ai, comes into the scene.
1.1 DVC
DVC is a highly capable command line tool. As a global definition, it makes dataset and experiment versioning convenient by complementing some other major developer tools such as Git. As an example, it enables dataset versioning together with git and cloud (or remote) storage. It provides command line tools to define .dvc files whose versions are tracked by git. These specific files keep references for exact versions of your dataset that are stored in cloud (like S3, Gdrive, etc. In short, DVC acts as a middleman that serves you to integrate git and cloud for dataset versioning.
As like dataset versioning, it also helps for experiment versioning using .dvc, .yaml and other config files. You can built pipelines that make your data flow through several processes to yield a value for your research, business or hobby. Using DVC, you can define such a pipeline and maintain it seamlessly. You can redefine your complete pipeline or fix some parts. What ever the case, DVC makes life easier for your team.
No need more descriptions or promises. Let's jump into it with an introductory tutorial. Note that, the dataset used in this tutorial is a small one that can be stored in git. DVC is actually developed for larger datasets but a smaller one is used here to save loading and computation time. Beside these costs, the procedure is exactly same for larger datasets with the steps and tools defined below.
2. Let's start
This tutorial is a partial reproduction of a previous data science project that was depended on notebooks during the development. Here, a simple pipeline is built for the work flow that starts with getting the data and ends with evaluating 2 simple model alternatives (deployment is not involved). Since the tutorial is on versioning, the codes for data preparation, model training and model performance evaluation are just transferred from corresponding notebooks of the previous project to the src folder of the new project as .py files. Hence the tree was lean as below at the beginning.
.
├── README.md
└── src
├── config.py
├── evaluate.py
├── prepare.py
└── train.py
Next step is to deploy pipenv for dependence management:
x@y:~/DVC_tutorial$ pipenv install
x@y:~/DVC_tutorial$ pipenv shell
(DVC_tutorial) x@y:~/DVC_tutorial$ pipenv install \
dvc[gdrive] pandas numpy sklearn openpyxl
Note that installing DVC on Linux is as easy as
pip install dvc. However,dvc[gdrive]is used here to install specific DVC version. This can work with Gdrive properly since it will be used for storing the versions of data during the tutorial. To see other installation alternatives, see DVC website.
Then git and DVC are initiated with git init and dvc init commands. At this point we have the following files and folders:
(DVC_tutorial) x@y:~/DVC_tutorial$ ls -a
.dvc .dvcignore .git Pipfile Pipfile.lock README.md src
3. Versioning Data
The original dataset of the project is stored in a UCI repository. Create the data folder and pull the data file (in .xlsx format) with specific DVC command:
(DVC_tutorial) x@y:~/DVC_tutorial$ mkdir data && cd data
(DVC_tutorial) x@y:~/DVC_tutorial/data$ dvc get-url https://archive.ics.uci.edu/ml/machine-learning-databases/00242/ENB2012_data.xlsx
Then "add" the data file to DVC with dvc add ENB2012_data.xlsx command. This yields the corresponding .dvc file for tracking it. This is the file that git will be tracking; not the original dataset. Using this file, DVC acts a tool that matches a dataset in a local or remote storage (Gdrive, S3, etc.) with the code base of the project stored on git.
Next step is pushing the data to the cloud that is Gdrive for this tutorial. Initially, create a folder manually on Gdrive web interface and get the label:
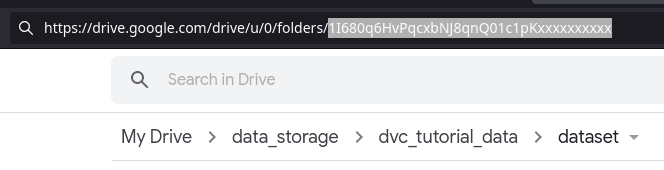
Once you get the label, declare it to DVC as remote storage location and commit it as below:
(DVC_tutorial) x@y:~/DVC_tutorial/data$ dvc remote add -d raw_storage gdrive://1I680q6HvPqcxbNJ8qnQ01c1pKxxxxxxxxxx
Setting 'raw_storage' as a default remote.
(DVC_tutorial) x@y:~/DVC_tutorial/data$ git commit ../.dvc/config -m "Remote data storage is added with name: dataset"
(DVC_tutorial) x@y:~/DVC_tutorial/data$ dvc push
Once you pushed it, Gdrive will ask you a simple-to-follow authentication procedure to get a verification code. Entering it, upload will start and you will get a folder with a random name on your Gdrive:
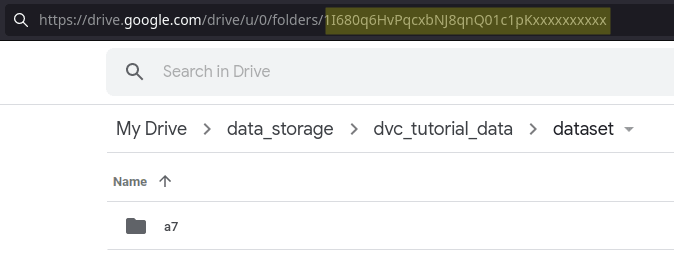
3.1 Building and storing another version of the dataset
Imagine a case that you have to keep the raw data but it is not useful as it is. You would need to transform it as needed and only keep new version on your local. As an example, let's say we need a .csv file instead of .xlsx. Simply convert it using python with the name of "dataset.csv:
(DVC_tutorial) x@y:~/DVC_tutorial/data$ python3
>>> import pandas as pd
>>> pd.read_excel("ENB2012_data.xlsx").to_csv("dataset.csv", index=None, header=True)
(DVC_tutorial) x@y:~/DVC_tutorial/data$ ls
dataset.csv ENB2012_data.xlsx ENB2012_data.xlsx.dvc
Then repeat the DVC and git steps:
(DVC_tutorial) x@y:~/DVC_tutorial/data$ dvc add dataset.csv
(DVC_tutorial) x@y:~/DVC_tutorial/data$ git add dataset.csv.dvc
(DVC_tutorial) x@y:~/DVC_tutorial/data$ git commit -m "Converted data is integrated with DVC"
(DVC_tutorial) x@y:~/DVC_tutorial/data$ dvc push
and get a second folder on Gdrive for the converted data:
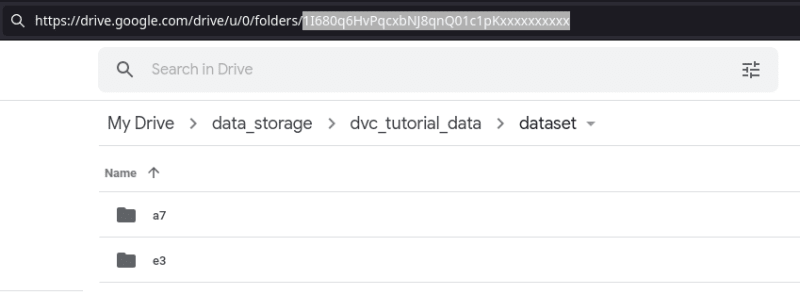
Now you can remove the raw data (keep the .dvc file) from your local to save disk space. However, as you progress in you EDA, still you may need to update your dataset. Once again you can create a new version of your dataset and only keep it in your local environment. Previous versions will be on remote storage and you can reach them as needed.
Just as a fictious scenario, say that last 100 lines of the .csv file is irrelevant for your purposes and you planned to progress by removing them:
(DVC_tutorial) x@y:~/DVC_tutorial/data$ cat dataset.csv | wc -l
769
(DVC_tutorial) x@y:~/DVC_tutorial/data$ head -n -100 dataset.csv > tmp.txt && mv tmp.txt dataset.csv
(DVC_tutorial) x@y:~/DVC_tutorial/data$ cat dataset.csv | wc -l
669
Having a new version of the dataset, you also need to store it in remote repository. Again using dvc add, git add (for .dvc file), git commit and dvc push command sequence as above. Once completed, you will have another folder on your Gdrive page.
3.2 Switching among dataset versions
Of course, DVC not only help to store different versions of your dataset. It also makes it possible to switch among them. Let's see our git logs:
(DVC_tutorial) x@y:~/DVC_tutorial/data$ git log --oneline
ca1258b (HEAD -> master) dataset is pre-processed
ea6973a Converted data is integrated with DVC
4025c49 Remote data storage is added with name: dataset
a20ad92 Raw data is pulled and integrated with DVC
6bff3fb (origin/master) initiation
Say it we regret to erase last 100 lines and would like to use them again. The only thing we need to do is to checkout to corresponding state of .dvc file:
(DVC_tutorial) x@y:~/DVC_tutorial/data$ cat dataset.csv | wc -l
669
(DVC_tutorial) x@y:~/DVC_tutorial/data$ git checkout ea6973a dataset.csv.dvc
(DVC_tutorial) x@y:~/DVC_tutorial/data$ dvc checkout
(DVC_tutorial) x@y:~/DVC_tutorial/data$ cat dataset.csv | wc -l
769
As the examples above show, DVC help us to surf between different versions of our dataset with git based tracking of .dvc files. You can see on your Github page that dataset.csv file is not there but instead only the corresponding .dvc files are available.
At this point, we have the following tree for our local project folder:
.
├── data
│ ├── dataset.csv
│ ├── dataset.csv.dvc
│ └── ENB2012_data.xlsx.dvc
├── Pipfile
├── Pipfile.lock
├── README.md
└── src
├── config.py
├── evaluate.py
├── prepare.py
└── train.py
4. Building Pipelines
Having desired form(s) of the dataset, the next step is to iterate a sequence of steps (pipeline) to built and test model(s). DVC helps you automate this procedure as well. The procedure would involve any step from data wrangling to model performance visualization. While working with different pipelines, DVC help you to document and compare the alternatives in terms of parameters you picked.
You can build a pipeline with DVC using dvc run command or via dvc.yaml file. Actually, when you use the former, DVC itself produce the former. Let' try it.
The primitive pipeline we will built here involves 3 fundamental steps: preparation, training and evaluation. For each of those steps, there is a dedicated .py file under the src folder. Using those and proper declerations, it is a straight forward task to build a pipeline.
- Code for the preperation step of the pipeline:
(DVC_tutorial)x@y:~/DVC_tutorial/src$ dvc run\
> -n prepare \
> -d prepare.py -d ../data/dataset.csv \
> -o ../data/prepared
> python3 prepare.py ../data/dataset.csv
- Code for the training step of the pipeline:
(DVC_tutorial)x@y:~/DVC_tutorial/src$ dvc run \
> -n training -d train.py \
> -d ../data/prepared \
> -o ../assets \
> python3 train.py ../data/dataset.csv
- Code for the evaluation step of the pipeline:
(DVC_tutorial)x@y:~/DVC_tutorial/src$ dvc run \
> -n evaluating \
> -d evaluate.py -d ../data/prepared -d ../assets/models \
> -o ../assets/metrics \
> python3 evaluate.py ../data/prepared ../assets/metrics
Note that there is a common pattern for declaration of each step. You define
- a name for the procedure with
-nflag, - dependencies with
-dflag, - output location with
-oflag, - code to execute and its dependencies with
python3command.
After entering the commands above, you get the following dvc.yaml file that can also be used for modifying the pipeline (remember that you can initiate the pipeline just by this file and corresponding DVC commands as well).
(DVC_tutorial) x@y:~/DVC_tutorial$ cat src/dvc.yaml
stages:
prepare:
cmd: python3 prepare.py ../data/dataset.csv
deps:
- ../data/dataset.csv
- prepare.py
outs:
- ../data/prepared
training:
cmd: python3 train.py ../data/dataset.csv
deps:
- ../data/prepared
- train.py
outs:
- ../assets/models
evaluating:
cmd: python3 evaluate.py ../data/prepared ../assets/metrics
deps:
- ../assets/models
- ../data/prepared
- evaluate.py
outs:
- ../assets/metrics
Once you built the pipeline, you can modify any part and rebuild it very conveniently. Say it, you wish to change the model you use in train.py file. Initially it was a Random Forest model but you would like to try Extra Tree Regressor as well. You only need to modify corresponding part:
# Build the Random Forest model:
# model = RandomForestRegressor(
# n_estimators=150, max_depth=6, random_state=Config.RANDOM_SEED )
# Build Etra Tree Regression Model (alternative model):
model = ExtraTreesRegressor(random_state=155)
After modification, the only thing you have to do is to run dvc repro command. It will the run whole procedure for you. Also, DVC is smart enough to eliminate the steps that not affected by the change. In out example, for example, no need to re-run the preparation step.
With the given code and config file, the performance metric of each run is stored in assets/metrics/metrics.json file.
5. Conclusion
The article presents how DVC make iterations over your work flow so convenient. The tutorial is focused on versioning of the dataset and the pipeline (repository is here). However, DVC presents more tools for hyper-parameter tuning, plotting and experiment management that will be subject of an upcoming post.

Top comments (0)