
The Goal
It’s best to achieve the desired result with as little a codebase as possible.
The fewer entities there are in a codebase, the easier and cheaper it is to familiarize oneself with it, support it and build upon.
However, as a project and its team grow, so does the risk of accidentally introducing identical or similar pieces of code. Even more so with iterations of automatic code generation.
DRY is a project I built to identify such similar pieces (okay, fine, and to play with Haskell).
Considered Approaches
It isn’t a trivial task to show deterministically that two (potentially different) pieces of code are identical, meaning they always produce the same output for the same input. In fact one has to make a proof for such a claim or its negation.
Another approach is based on heuristics. This is the path chosen for DRY. Such an approach has its downsides: one can easily create two functions that can fool any given set of metrics, and still prove the functions to be identical. Yet when building a project, the mentioned vulnerability can usually be safely ignored. Because of all the best practices, naming conventions, style guides, automatic syntactic tests and so forth it is likely that identical functions will have identical names, arity, statements, their count and depth. Thus I decided to give this approach a try.
Metrics
A set of metrics is calculated for each unique pair of functions. Every metric is bound to the range of [0; 1]. Here are the metrics themselves.
Levenshtein Distance between the names of two functions. More precisely,
1 / (1 + LD)where LD is Levenshtein Distance.Functions’ Arity Difference: one if both have zero arity, otherwise a division of a lesser value over the greater one.
Functions’ Statements Difference: the same statements are counted on each depth level and considered separately from the statements of different kinds, unique statements are also accounted for. The deeper the less important the difference is. The more unique statements any of the two functions has, the less similar the functions are (and vice versa).
Functions’ Statements Total Count Difference, counted in the fashion similar to that of arity: one if both have zero statements, otherwise a division of a lesser value over the greater one.
Finally, for every pair of functions the above scores are multiplied by a vector of weights. Then the average of the values is calculated, and that’s the similarity score of a given function pair.
One might wonder, why would we need the fourth metric (total statements count difference) if there already is the third one (accounting for the difference in statements count, grouped by statement type and depth level). If the functions’ bodies consist of similar statements, the fourth metric is perhaps excessive. However if they consist of different statements, there still might or might not be similarity in the amount of statements used to define them. The fourth metric accounts for that.
The final metric (as the four above) is bound to [0; 1] where 1 is the same and 0 is completely different.
Results
I executed DRY against a number of repos, and created this visualization with Python:
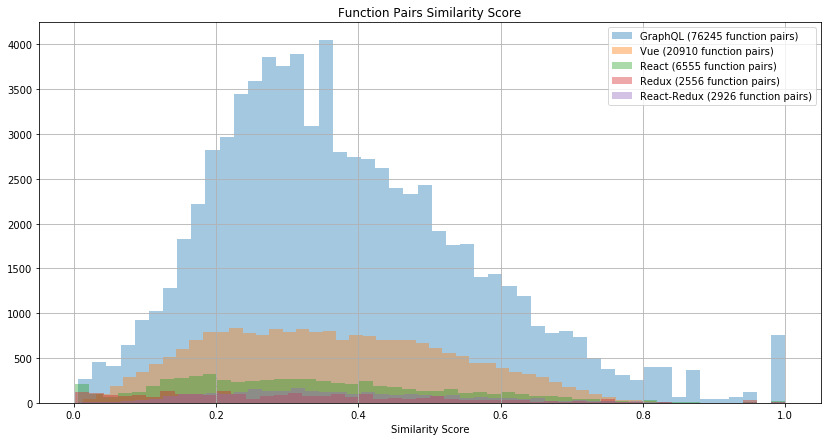

Interestingly, most similar functions are the ones with similar total count of statements. This is merely the consequence of how the score is calculated (see the weights vector). What’s also worth noting is that there are functions with hundreds of statements. For instance, here is Vue’s createPatchFunction with 3831 statements.
Vue is a project big enough to illustrate the whole spectrum of possibilities. Let’s take a look at exactly the same functions first, there is quite a number of them.
First here is createOnceHandler for one platform and for another.
Then genData for class and style. This is a peculiar case. According to the metrics, these functions are absolutely the same (with a score of 1.0). In practice however they are not: string templates differ a bit, so do object property names. It is technically possible to account for such kinds of differences. Whether it makes practical sense is another question.
There are other similar instances of genData, such as this one. In total six unique pairs of genDatas were found. This gives us four distinct genData functions similar to each other (since the pairs are unique and order within a pair is insignificant).
One more example of a pair of similar functions is generate. I would assume this one has to do with server-side rendering, while this one is for the client’s side.
Alright, how about almost similar functions. The following pair of functions has the similarity score of 0.952695949955943 and statement counts are 105 and 100 respectively: transformNode and transformNode. Notice how in the latter case it is tested whether staticClass evaluates to true, while staticStyle is not tested, even though the way they are retrieved is the same: using getAndRemoveAttr.
There is the total of 167,331 unique pairs for the repo, with the pair of the least similar functions having the score of 0.002267573696145. I invite the reader to see for themselves what these functions are.
Conclusion
As it is shown above, DRY can be used not only to identify similar functions in order to abstract them away and thus alleviate any repetition in the codebase, but also to spot inconsistency which may help discover a bug. Hopefully you find the tool useful. Please feel free to try it, point out any issues and potential ways to improve it.
Thank you for reading!

Top comments (0)