
You're working on a new project, still in the high-level design. you write down the requirements: what am I trying to solve?
You figure it out, outline the main items. you consider what tools are you gonna use (which programing language, or technologies).
You perform couple more steps, before you dive in coding.
This was a fast-forward start of a new project. You now need to think on the structure of your data (classes, interfaces, etc.)
One thing you have to consider at this stage is serialization. How do you persist your data, either it be to a local filesystem or over the network? (You can't just send objects over the wire, yet :))
Protocol Buffers are a method of serializing structured data. It is useful in developing programs to communicate with each other over a wire or for storing data. (Wikipedia)
In this article I'll explore what is it and how to use it with Python.
What is it
Google's documentation definition of protobuffers is:
Protocol buffers are a flexible, efficient, automated mechanism for serializing structured data – think XML, but smaller, faster, and simpler. You define how you want your data to be structured once, then you can use special generated source code to easily write and read your structured data to and from a variety of data streams and using a variety of languages. You can even update your data structure without breaking deployed programs that are compiled against the "old" format.
TL;DR
You define your "messages" (data structures) in .proto files and gain the ability to interchange data between different services written in different languages. It is smaller, and faster than JSON/XML. It is also much easier to maintain.
How to use it
The first step when working with protobuffers is to define the structure for the data.
protobuffers is structured as messages, where each message is a small logical record of information containing a series of name-value pairs called fields.
Next, you use the protobuffers compiler (protoc) to generate the source code in the language you need (from the .proto file).
These provide accessors for the data, as well as methods to serialize/parse the data structure to/from a binary format.
Let's look on an example. I'm going to use Python interpreter to inspect the Python objects created by protobuffers.
Also, I show an example of how to compile the same .proto to Go source code.

Preparation
Before we start, you need to install Google Protobuffers on your OS. Below are the instructions for Mac OS, you can find instructions to other OS in the documentation:
- Download the package & unpack the tar.gz file
- cd into the directory and run
./autogen.sh && ./configure && make- If the compilation fails, install the required dependancies with brew:
brew install autoconf && brew install automake && brew install libtool
- If the compilation fails, install the required dependancies with brew:
- After step 2 succeeds, run the following:
- make check
- sudo make install
- which protoc && protoc --version
The last step validates protoc is installed and located in your PATH, then prints its version.
We also need the relevant plugins for Python and Go, so we can compile output source code files in these languages.
- For Python:
pip3 install protobuf - For Golang:
- Verify GOPATH is set, and GOPATH/bin is in PATH env variable
go get -u github.com/golang/protobuf/protoc-gen-go
The .proto file I'm gonna use is simple with the code snippet below. I then gonna make source do for Python and Go out of it.
This is my data-structure; Let's explore.
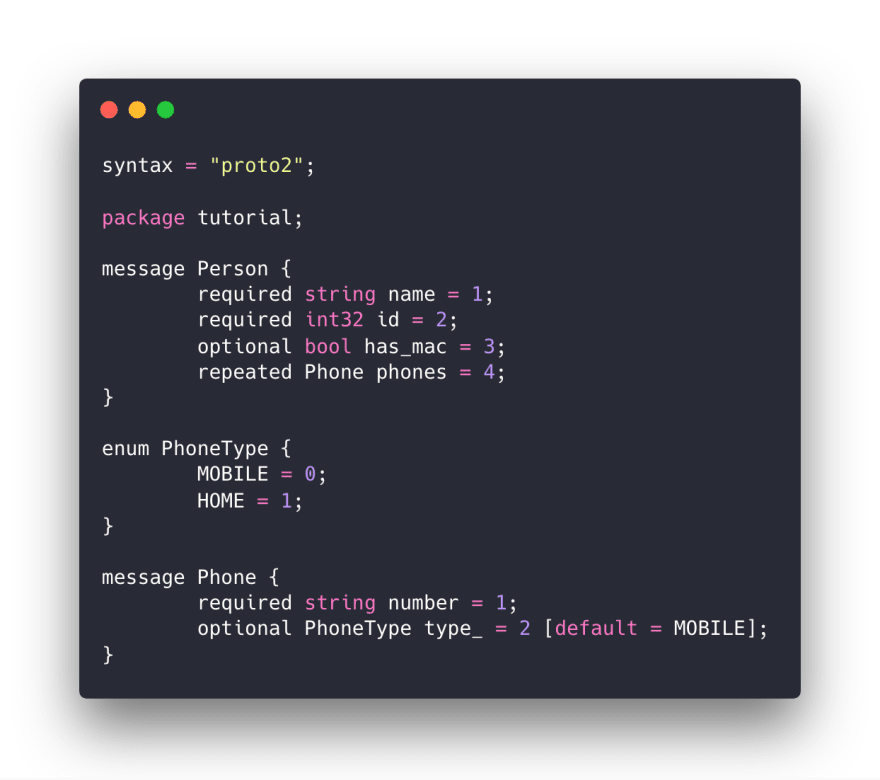
The file is self-explantory, you can read more about its structure at Google Protobuff Documentation.
Let's see how do we use it.
To generate a Python file, you need to execute protoc -I=$SRC_DIR --python_out=$DST_DIR $SRC_DIR/Person.proto
It generates a file named Person_pb2.py which we are going to use. The file is pretty large, so I won't put it here but I encourage you to try it
yourself and inspect the file. (The above .proto file generates 165 lines of python code!)
Exploration
Show me some code!
Python 3.7.0 (default, Sep 16 2018, 19:30:42)
[Clang 9.1.0 (clang-902.0.39.2)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>>
>>> import Person_pb2
>>> p = Person_pb2.Person()
# The imported model contains a class defined by our message
# Let's inspect what attributes are there on the object,
# Using the DESCRIPTOR of our object.
>>> p.DESCRIPTOR.fields_by_name.keys()
['name', 'id', 'has_mac', 'phones']
>>> p.name
''
>>> p.name = 'Gnosis'
>>> p.id = 4
>>> p.phones
[]
# Let's add phone elements to the list (the repeated type)
>>> pho = p.phones.add()
>>> pho.number = '1800-500-501'
>>> pho.type_ = Person_pb2.MOBILE
>>> pho
number: "1800-500-501"
type_: MOBILE
>>> p
name: "Gnosis"
phones {
number: "1800-500-501"
type_: MOBILE
}
# You can also create Phone objects without adding them to person
>>> phone = Person_pb2.Phone()
>>> phone.DESCRIPTOR.fields_by_name.keys()
['number', 'type_']
>>> phone.number = '1800-500-500'
>>> phone.type_ = Person_pb2.MOBILE
>>> phone
number: "1800-500-500"
type_: MOBILE
# Which we can later add it to our object using extend
>>> p.phones.extend([phone])
>>> p
..
phones {
number: "1800-500-501"
type_: MOBILE
}
phones {
number: "1800-500-500"
type_: MOBILE
}
# We can check if certain field is defined on our object
>>> p.HasField('name')
True
# Okay, let's see how we serialize this object
>>> p.SerializeToString()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
google.protobuf.message.EncodeError: Message tutorial.Person is missing required fields: id
# Ooops, we didn't set a required field. This causes serialization operation to fail.
>>> p.id = 4
>>> p.SerializeToString()
b'\n\x06Gnosis\x10\x04"\x10\n\x0c1800-500-500\x10\x00"\x10\n\x0c1800-500-500\x10\x00"\x10\n\x0c1800-500-500\x10\x00'
>>>
>>> b = p.SerializeToString()
>>> b
b'\n\x06Gnosis\x10\x04"\x10\n\x0c1800-500-500\x10\x00"\x10\n\x0c1800-500-500\x10\x00"\x10\n\x0c1800-500-500\x10\x00'
>>> type(b)
<class 'bytes'>
# We can save this binary to disk or send it on the wire to another service.
# Then we simply load it with a new object.
# We create a new object and use ParseFromString method to load it's data
>>> new_p = Person_pb2.Person()
>>> new_p.ParseFromString(b)
64
>>> new_p
name: "Gnosis"
id: 4
phones {
number: "1800-500-500"
type_: MOBILE
}
phones {
number: "1800-500-500"
type_: MOBILE
}
phones {
number: "1800-500-500"
type_: MOBILE
}
You get the sense. Each message becomes a class, and a repeated field defines a list.
The difference between required and optional is if the required field is not initalized, there will be
an informative exception when you serialize the object. This won't happen with optional fields.
I use the same .proto file to generate my source code in Go.
To generate the Go code, you execute protoc -I=. --go_out=. ./Person.proto (199 lines of code)
You'll need the golang protobuf plugin, and execute the command inside the directory where the .proto file
When and Why would you want to use it
Protobufs are not for everyone or for every project. It has some overhead, you need to learn and maintain another language. You also need to compile your code on every change you make to your data-structures.
The best use-case for protobufs is when there are two (or more) services that needs to communicate.
If the services are written in different languages, that's another plus in protobufs favour. Because services (computers) don't need the data to be in human-readable fashion; they work faster with bits (binary).
Imagine a scenario: two development teams need to share data between them (they use different programing languages, say Python and Go). Each team needs to define their own data structures and they need to be identical for the two application to communicate well.
Usually, this isn't a big deal when you you are in the design stage of the development process. The harder part is to keep the development of these data structures, and to keep everyone in the loop.
With protobuf, we have a better solution for this use-case.
You define your data in a .proto file once, in a separate, shared project.
Each team uses the project to generate their source code in their programing-language.
When you need to add more fields to the data, you extend them in the source .proto file and re-compile them.
Then, give a heads up to the other team they need to re-compile it too, and do the necessary updates to their source code.
Another cool feature of protobuf is the backward compatability support. Even if the other team use an older version, the service won't break down. It just won't support the new data. Isn't that fabolous? We get backward compatability for free.
Advantages
- Define your data structure once and generate the source code in any coding language you need (that supported)
- It is more maintainable, manage only one source code of your data-structure in .proto
- It is more size efficient than JSON / XML (It's binary, compared to strings)
- Fast serialization
- Type safety
- Backward compatability
Drawbacks
- Smaller community, and lack of knowledge. You can find more documentation, examples and blog posts over JSON or XML
- It is not human-readable
Conclusions
When you sit and design the requirements from your application, you look on the pros and cons of the options you've got on the table.
Considering the pros and cons, I think we can conclude that when a human or a browser is the consumer of the data, it is probably better to use JSON because it is human readable out of the box, and thus saves us time. No efforts needed to unmarshal data.
But, if you have two services that needs to communicate between them, protobuf has so many advantages that you should at least consider it as a solution.
I strongly recommend you try protobuf yourself. They have more advantages than I mentioned here. This was more of How-To post, exploring the data generated by the protobuf.
References for more info

Top comments (0)