
I got a bit bored during the COVID-19 lockdown here in Nigeria, so I decided to play around with data scraping using Python and Selenium.
The first question I needed to answer was what data I would like to scrape, and what I would be doing with the scraped data.
I decided to build a system that scrapes COVID-19 data from NCDC website, and sends me an SMS notification once there's an increase in cases within the country.
In this series, I'll be sharing how I built this simple system, hopefully, it would help someone build something larger and better.
Setting Up
We'll be using Selenium Python library, and a browser driver (either Chrome or Firefox driver).
- Install Selenium
pip install selenium
- Download and Install Browser Driver
You can download either of the drivers from the links below:
Let's Go!
Now that we have installed our library and browser driver, it's time to get into the code.
Create your .py file and write:
from selenium import Chrome
from selenium.webdriver.common.by import By
# Make an instance of the chrome driver
driver = webdriver.Chrome()
# Initiate the browser and visit the link
driver.get('https://covid19.ncdc.gov.ng/')
In the code above we are importing Chrome driver from selenium and also importing 'By' private method from selenium web driver for selecting how we would like to locate elements. Also, we are initiating the browser using Chrome driver and using it to visit the page to be scraped.
If you prefer to use Firefox driver, your code would look like this:
from selenium import Firefox
from selenium.webdriver.common.by import By
# Make an instance of the firefox driver
driver = webdriver.Firefox()
# Initiate the browser and visit the link
driver.get('https://covid19.ncdc.gov.ng/')
The next step would be to locate the element where these data are, it's important to study and inspect how the DOM of the website to be scraped is rendered. For our NCDC Covid-19 the data we want is located within a table with id custom3.
table = driver.find_elements(By.XPATH, "//table[@id='custom3']/tbody/tr")
print(table[1].text)
Here we are finding elements by XPATH, there are so many other methods of finding elements and you can find the available methods on the Selenium Python Documentation. We find the table tag with id of custom3, then go into the tbody and finally the tr tag, this is possible using XPATH. We then print the second content to see what we have, before we proceed.
On our terminal we will change directory to our project root folder run:
python your_file_name.py
We will get this as a result:
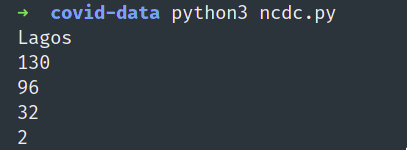
We can see we have been able to get some data from the page, we will proceed to get the header of the table.
header_tag = table[0].find_elements_by_tag_name('th')
headers = list(map(lambda header: header.text, header_tag))
print (headers)
The code above finds the table header(th)tags within the first row and adds them to a header list. Running the script will print a list of the headers:

Finally, we will get the data for all the states:
results = []
for item in table:
data = item.find_elements_by_tag_name('td')
sd = list(map(lambda item: item.text, data))
results.append(sd)
#Always remember to quit the browser driver when you are done
driver.quit()
results = list(filter(None, results))
print(results)
Here we created an empty list called results, iterated through the table row element and searched for element by tag name 'td'. Within each table row, we have our data for each state. Then we finally filtered out empty rows and printed the results.
Voila!!! We have the COVID-19 data across different states in Nigeria.

Now that we have our data ready, in the next part of this series we will be saving the data to some kind of database for easy retrieval and tracking of changes.
Our entire code so far looks like this:
from selenium import webdriver
from selenium.webdriver.common.by import By
import itertools
import csv
driver = webdriver.Chrome()
# Start the browser and visit the link
driver.get('https://covid19.ncdc.gov.ng/')
table = driver.find_elements(By.XPATH, "//table[@id='custom3']/tbody/tr")
header_tag = table[0].find_elements_by_tag_name('th')
headers = list(map(lambda item: item.text, header_tag))
results = []
for item in table:
data = item.find_elements_by_tag_name('td')
sd = list(map(lambda item: item.text, data))
results.append(sd)
#Always remember to quit the browser driver when you are done
driver.quit()
results = list(filter(None, results))
print(results)
I hope I've been able to share my process well enough in this first part, feel free to contribute if you feel something is missing, or there are better ways to have done certain things. I look forward to your contribution(s). Catch ya in the next part.

Top comments (0)