Part 2, Design & Set Up the Environment

Introduction
The two most critical components of any building are its blueprints and its foundation. The result of not having a well thought out plan is uncoordinated construction, missed deadlines, cost overruns, and a building that doesn’t meet the needs of its owners and occupants. Even worse are the safety risks that come from either poor planning and a shoddily constructed foundation.
It is much the same with web applications — success hinges in part on having a plan based on end-user use cases, as well as a frontend and backend infrastructure architected to support the applications ability to meet its primary objective. Namely, satisfying the users need.
Part 1, Learning the Lay of the Land proposed developing the Climate Explorer application as a means to explore using MongoDB as an intermediate staging area to capture, cleanse, and organize large volumes of data before loading it into an operational database, like PostgreSQL. This article will define the requirements and constraints of the frontend and backend environments needed to support this project and to describe their components.
The Climate Explorer repo resides in the feature/05-article-part2 branch on GitHub.
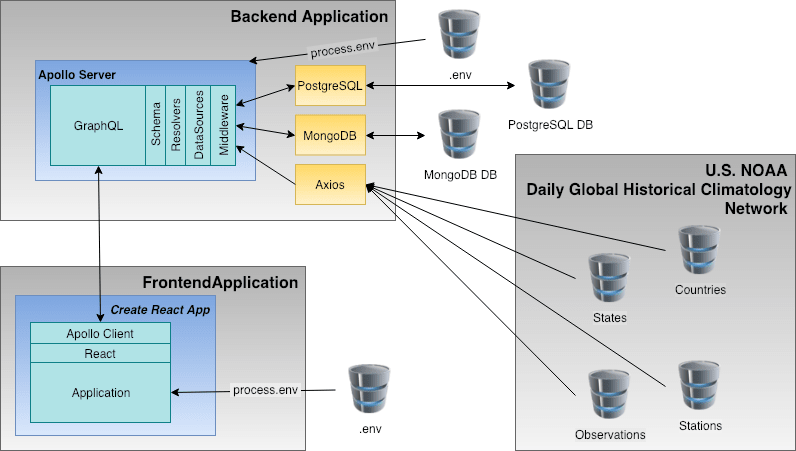
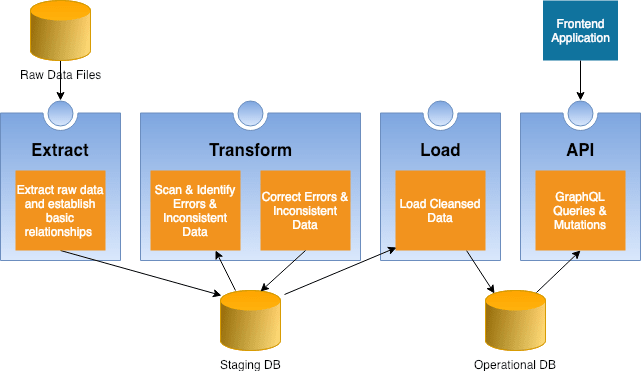
As shown in Figure 2 the source code and supporting files for the frontend are maintained in the client subdirectory, while the server subdirectory contains the backend files.

Frontend Architecture
As you would expect, the frontend’s responsibility is to provide the user with a means of accessing and manipulating the climate data maintained in the backend. The frontend also exposes administrative functions to initiate and monitor the data extraction, transformation, and loading (ETL) process.

Create React App
The frontend uses ReactJS for the implementation of the user interface and was generated using the Create React App. Also, since we wanted the UI/UX to follow the concepts and practices of good design the Material-UI React Components package is used to leverage Google’s Material Design, with a minimal amount of developer ramp-up time.
The objective for this stage of development is to create an application skeleton that later stages of the project will enhance based on new requirements. Due to this, the frontend has a minimal UI that contains only user authentication and an ‘Under Construction’ page. Any new functionality that surfaces will replace the ‘Under Construction’ page.
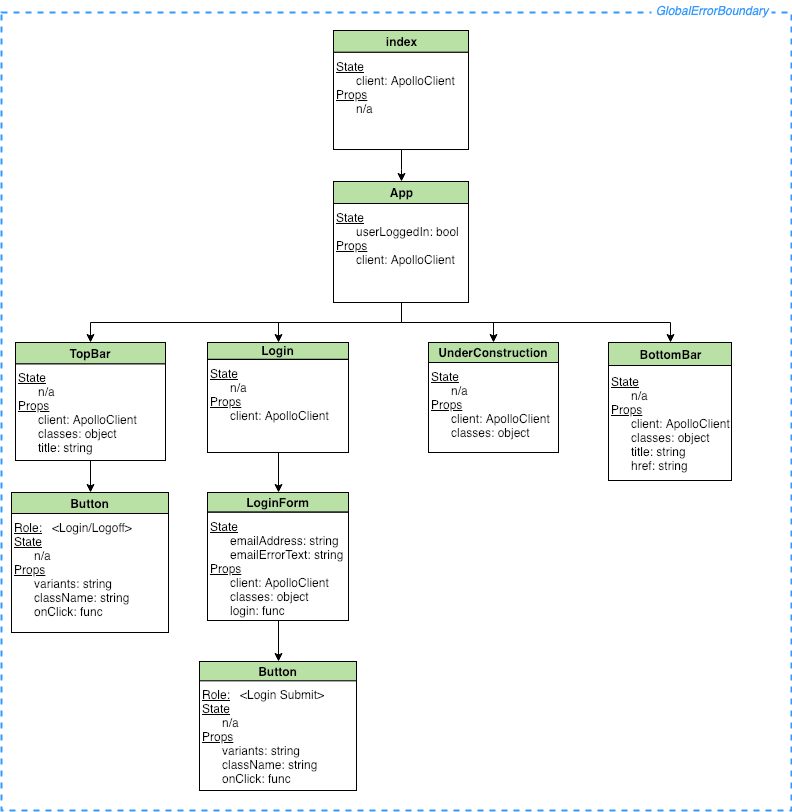
Figure 5 shows the frontend components currently implemented in the Climate Explorer. A simplistic approach to component state management is used since the use cases for climate data presentation haven’t yet been defined.
A global React Error Boundary is defined around all application components to trap and report on any errors that might occur. For more information about error boundaries checkout “Exploit React Error Boundaries to Improve UX.”
Server API
The frontend application does not persist data across sessions. Data resides in the two backend databases and is accessed and manipulated through an API built on top of Apollo GraphQL.
GraphQL is used instead of REST since it allows the frontend to choose which data attributes are needed, it is easy to understand, is supported by robust tools, and most importantly, is a proven solution. See “REST vs. GraphQL: A Critical Review” for more information about REST vs. GraphQL
GraphQL includes a set of React components which, compared to REST, makes the code easier to read and understand since it follows a declarative style based on the principles established by React. For example, the <Query> component in Figure 6 shows how to retrieve a Boolean that indicates if the backend server has completed user authentication.

This particular GraphQL query is even more interesting since it uses Apollo to operate on local state rather than on server-based data. Manipulating local state in this manner eliminates a potentially costly trip to the server and simplifies the code by removing the need to pass application state as props to other components.
Backend Architecture
The backend server has two responsibilities — performing ETL operations to populate the operational database and providing an API for frontend application access to operational data. The backend components supporting these responsibilities are:
- MongoDB database used as a staging area for the ETL process
- PostgreSQL database that contains operational data
- API based on the Apollo GraphQL Server.
Similar to the frontend, the goal for this stage of the project is to establish a skeleton that functionality will be added to later in the project. Because of this tooling you might expect in a backend, like webpack and Express, have been omitted until we know they are required.

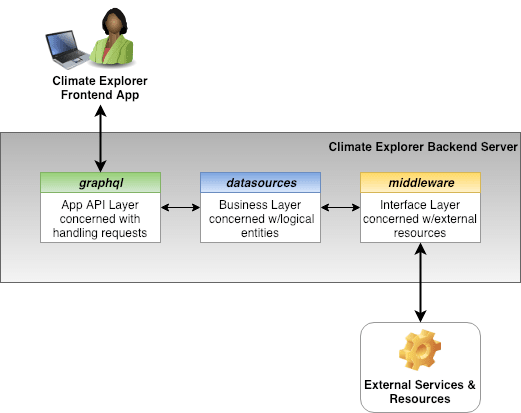
The graphql subdirectory contains the queries, mutations, and resolvers that implement the various API features. GraphQL resolvers use modules residing in the datasources subdirectory to execute specific business operations against climate data. Finally, modules located in the middleware subdirectory interface with external services and resources like databases and services to access and maintain physical data.
MongoDB
The staging area for the incoming raw data uses MongoDB due to its efficiency, support of unstructured data, and query capabilities. MongoDB is a better choice for staging than SQL since loading large volumes of raw data into a SQL database requires the raw data to be error-free and relationships between entities to be consistent. Since SQL must enforce ACID principles, it is understandably intolerant of these types of issues since relationships are based on data values.
Many developers find that object-relational mapping (ORM) packages like Mongoose make development easier and faster by providing a schema-based approach to data modeling and management. This project uses only native MongoDB based on the following two assumptions:
- Loading and transforming raw data will require only basic MongoDB functionality.
- The volume of documents to be processed coupled with the additional code path for Mongoose will have a measurable impact on CPU consumption.
Not using an ORM like Mongoose doesn’t imply there are any problems or concerns with either its functionality or quality. It is merely a design decision and one that can be revised based on circumstances.
For more information about Mongoose see “An Overview of MongoDB & Mongoose.”
PostgreSQL
Climate Explorer uses PostgreSQL for its permanent operational database. A SQL database management system (DBMS) is preferred over a NoSQL DBMS to provide consumers of climate data with a fast, yet highly structured data model. Since Climate Explorer is a demonstration platform for ETL, the requirement that operational data be highly structure is an artificial requirement.
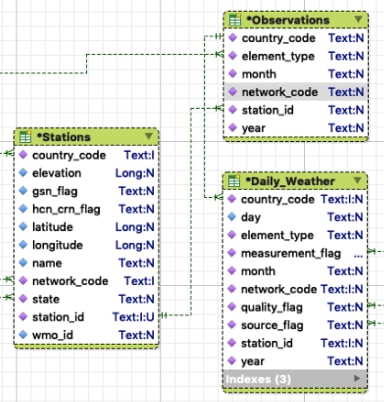
As previously discussed, SQL DBMSes require consistent data since relationships between entities are established using shared data values. For example, a climate observation is related to the station it was taken at by a unique station identifier.
For this relationship to exist a row in the Stations table must have a station id matching the one in the related rows of the Observations table. The shared station id establishes a 1-to-many relationship between a weather station and its observations.
At this time an ORM isn’t used to load data into the operational database for the same reason the application doesn’t use one for MongoDB access. However, as new use cases are identified, they may create the requirement that the API should use an ORM for operational access to data maintained in PostgreSQL.
Retrospective — Failing Forward
Making mistakes is nothing to be ashamed of so long as you learn from them and you strive not to repeat them. Many times the most permanent lessons come from mistakes.
It’s no different with this project. Rather than retreating from mistakes (i.e., that I have made) they will be embraced as “teachable moments.”
Apollo “Alpha”
Leveraging the local state management of the Apollo Client was something I wanted to explore in this project. Unfortunately, I didn’t follow the Apollo Tutorial closely enough and wasted 2+ days attempting to get it to work correctly.
The root cause of this issue was that stable releases of the Apollo packages were installed rather than the alpha release of Apollo Client 3.0 because the following statement was overlooked in the tutorial:
“apollo-client@alpha: A complete data management solution with an intelligent cache. In this tutorial, we will be using the Apollo Client 3.0 preview since it includes local state management capabilities and sets your cache up for you.”
To resolve this issue the local state management feature in the stable release of apollo-link-state was used, rather than the approach implemented in the alpha release of apollo-client. Although the method provided by the alpha release is more straightforward, using it instead of the stable release could expose Climate Explorer to undesirable side effects.
Lesson Learned : Read the documentation, then read it again, and then read it yet again
CEButton Component
Early in the development of the frontend, the determination was made that multiple spots in the UI required buttons for user input. Not wanting to duplicate code, a CEButton component was created to encapsulate the Button component in the Material-UI package.
Unfortunately, this approach was too abstract and CEButton became overly complicated, requiring too many props and too many conditional statements. The solution was to substitute Button for CEButton, which simplified the code making it easier to understand and also more adaptable.
Lesson Learned : Programming principles like DRY are useful, but rote use of a technique isn’t an acceptable substitute for understanding its use cases.
MongoDB find param (users vs. user)
Initial testing of the findOne function in the MongoAPI module wasn’t retrieving the users document even though the document and its data were verified using MongoDB Compass. After several wasted hours and many console.log statements it was determined that the calling function was passing ‘user’ instead of ‘users’ in the collectionName parameter.
Lesson Learned : Check for the obvious and write stronger error handling functions.
Wrapping It Up

Climate Explorer now has an architecture, a frontend, and a backend that will hopefully support its goal of demonstrating ETL processes. The objective of this article has not only been to describe how the environment has been constructed, but also to share the factors influencing important decisions.
It’s important to keep in mind that as the project progresses, we’ll discover new information, gain experience in technologies that we aren’t yet experts at, and make mistakes. Because of this, it is not just important but critical to pay attention to the second Agile Principle.
“Welcome changing requirements, even late in development. Agile processes harness change for the customer’s competitive advantage.”
Up Next — Part 3, Designing the Databases

Top comments (0)