
The story of how a small prompt idea snowballed into a real agentic LangGraph runtime and I didn’t even speak Python three months ago.
This is the first post in the series, the "why/how did you even end up building this" part. The next posts will be technical deep dives into specific topics (project architecture, RAG with Drupal, contracts/guardrails, ambiguity detection, etc).
TL;DR
- I attended AW-MLEA (Machine Learning Engineering on AWS) which ignited my professional enthusiasm.
- I needed a real project to learn. Luckily, the course gave an easy-looking idea: an "ML success criteria framework". I named it SageCompass.
- What I thought would be "a small practice thing" quickly turned into something that taught me how to think with these technologies.
- After a few months I found myself rebuilding parts of the runtime again and again, mostly because the code kept exposing what was unclear or brittle.
- This series is me documenting the path and the architecture lessons as they formed (no prior training or experience in Python, ML, or agentic systems so things weren't obvious from day one).
- Current implementation is here: https://github.com/cleverhoods/sagecompass
It was late October, 2025.
I was waiting excitedly for my long, 4-day weekend after a long, 6-day working week (... yeah, in Hungary you have to "work off" the extra holiday). I was so looking forward to it, that I completely forgot that I'd signed up for AW-MLEA (Machine Learning Engineering on AWS) training. The training started on Wednesday. My long weekend started on Thursday. The training was 3 days long.
... great.
Little did I know that my previous weekend was my last free one for the forthcoming months.
The training kicked off, and just a few hours in, I was hooked.
Finally! High-grade, educational information about Machine Learning! How it learns, what's the difference between ML training approaches, what challenges are there for ML solutions, what is a Model, what type of Models are there and what are the main differences between them, what kind of dimensions responsible AI encompasses, what kind of biases are there, how does an ML success criteria framework look like and so on and on.
... and we haven't even arrived at lunch and already had 2 coffee breaks.
This went on for 2 (and a half) more days. With similar intensity and information density. It was only manageable thanks to the great learning material and the great guidance (a shout-out to Thomas Fruin, the exceptional presenter of this course).
... and just like that, it was over. The course was completed and I was left with a burning enthusiasm to utilize the freshly learned concepts.
I could've played around with sandbox environments (very limited instances of the SageMaker Studio with Jupyter notebooks) but that wasn't what I was looking for.
I'm adamant about learning new concepts: the easiest way to learn is by doing. Implement a real project. Don't just poke at sandboxes.
All I needed was an example project, and I already had my eyes on something I was introduced to on the very first day: an ML success criteria framework.

It got the name SageCompass because it's supposed to help me determine whether the input is actually an ML problem.
How SageCompass evolved
The original idea was simple: take the ML success criteria framework, turn it into a guided intake flow, and provide structured, detailed answer to the core question:
"Is this even an ML problem?"
And if it is, make sure the answer includes measurable business values:
- Business Goals
- KPIs
- Data baselines and readiness
- Risk assessment
- Minimal pilot implementation plan with a kill criteria if things go in the wrong direction.
At the time I thought: "I'll build a small example project, practice some concepts on the business values and move on."

Instead it turned into a loop: build -> surprise -> restructure -> repeat. Over and over again.
v1-3: The Prompt era
Originally I did not plan to build an agentic platform. Not even a system. Just one well structured prompt, with deterministic rules, and a structured output.
The original prompt quickly turned to several specific prompts as I've kept hitting ChatGPT's upper prompt length limit.
Behavioral expectations, process and task rules, policies, limitations, etc., all got into dedicated markdown files.
A single prompt turned into a small prompt system.
Eventually I ended up with 9 different prompt segment files + the main instructions:

At this stage the project was only "prompt engineering with ambition" with wow factor. Whilst the prompts and the outputs reflected what I had just learned about models and how they process information, maintaining and extending them was a nightmare. I had to be on guard all the time when I changed something and had to be sure that change is followed up everywhere. The solution was rough and definitely not production-useful.
I needed some help validating the direction, so I asked our AI Director (Sebastiaan den Boer) for a sanity check, and his first reaction was: "This sounds like a LangChain project."
My first reaction to that was: "Sounds like a what now?"
So I set out to learn what LangChain is and how to implement my project with it.
v4: My first ever Python project
LangChain offers 2 types of implementation: JavaScript and Python. I always wanted to learn Python and during the training we heavily relied on Jupyter notebooks so I felt that NOW is the right time to get this off my bucket list.
For this phase I set one simple goal: a running Python environment with at least one Agent.
My expectations for the project were the same as with any other projects:
- it should be encapsulated
- it should provide its own runtime
In the first iterations, I tried to implement the Python local development environment with DDEV (which is a great, project-level Docker environment manager/orchestrator, using it for years now for Drupal projects).
When you have a hammer, everything is a nail.
It worked well enough to create a super basic LangChain implementation, that would read and validate LLM provider (OpenAI and Perplexity) configurations, log what's happening in the system, read my humongous prompt and communicate with Gradio UI.
Wow! That was easy!
I was able to quickly create a base Python class for all the future Agents and to create the very first agent: Problem Framing. It was the first phase in the SageCompass Process Model (v3), from my reasoning-flow.md. Its singular job was to reframe the user input into a rich business format so I could set expectations for the input data before I ran the whole shebang.
All dandy. I hit the phase goals, so I gave myself permission to ignore the mysteriously slow response time in the UI when I ran a query.
At least until I add more agents and this thing starts fighting back.
v5: Journey to a multi-agent workflow
At the end of v4 I had exactly what I wanted: a working Python runtime and my first Agent.
I also had something else: a UI that was oddly slow.
So I did the obvious thing: ignored the problem and started drafting more Agents anyway.
I took the rest of the SageCompass Process Model (v3), from my reasoning-flow.md and split it into Agents.
| Agent | Responsibility | Output |
|---|---|---|
| Problem Framing | Reframe input into a structured brief | brief |
| Business Goal | Produce SMART business goal(s) | goals[] |
| KPI | Define KPI set with thresholds | kpis[] |
| Eligibility | Decide AI/ML eligibility (yes/no + why) | eligibility{decision, reasons} |
| Solution Design | Propose candidate approaches (high level) | approaches[] |
| Cost Estimation | Estimate cost/effort envelope | cost_envelope |
| Decision | Issue summary with final recommendation | recommendation |
My approach was simple:
- every Agent should be responsible for one thing
- every Agent should have the same folder structure
- every Agent should be built similarly
This was enabled by the base Python class implementation from v4. Each Agent expected to extend that class.
Learned some Python, yay
Put it all together and this is what the workflow looked like.

Looks neat, isn't it? Let's run it!
drum rolls
more drum rolls
even more drum rolls
... wow. That took 7 minutes 32 seconds to run. Feature-first tunnel vision sure bites hard.
So I stopped pretending this was fine and started cleaning house. First move: I switched the project's packaging and workflow to uv and ditched the earlier setup. Then I found the real culprit: I was running another virtual Python environment inside Docker.
After fixing that, runtime dropped to ~1 minute per run.
Lesson learned: don't stack Python environments.
And while building the workflow, a sudden realization hit me:
If I'm building an augmented decision system that checks whether an idea needs ML at all... wouldn't that naturally translate to whether an idea needs AI at all?
If that's true, then the original "ML success criteria" flow doesn't disappear.
It becomes a reusable component I would have to build anyway.
The difference is: I'd end up with something way more useful.
So I took the longer road.
And that's where the prompt stopped being "the thing" and everything around it started becoming the thing.
v6: In for a penny, in for a pound - creating an agentic platform
I liked the idea.
How would it roughly look like? Gonna need RAG for sure.
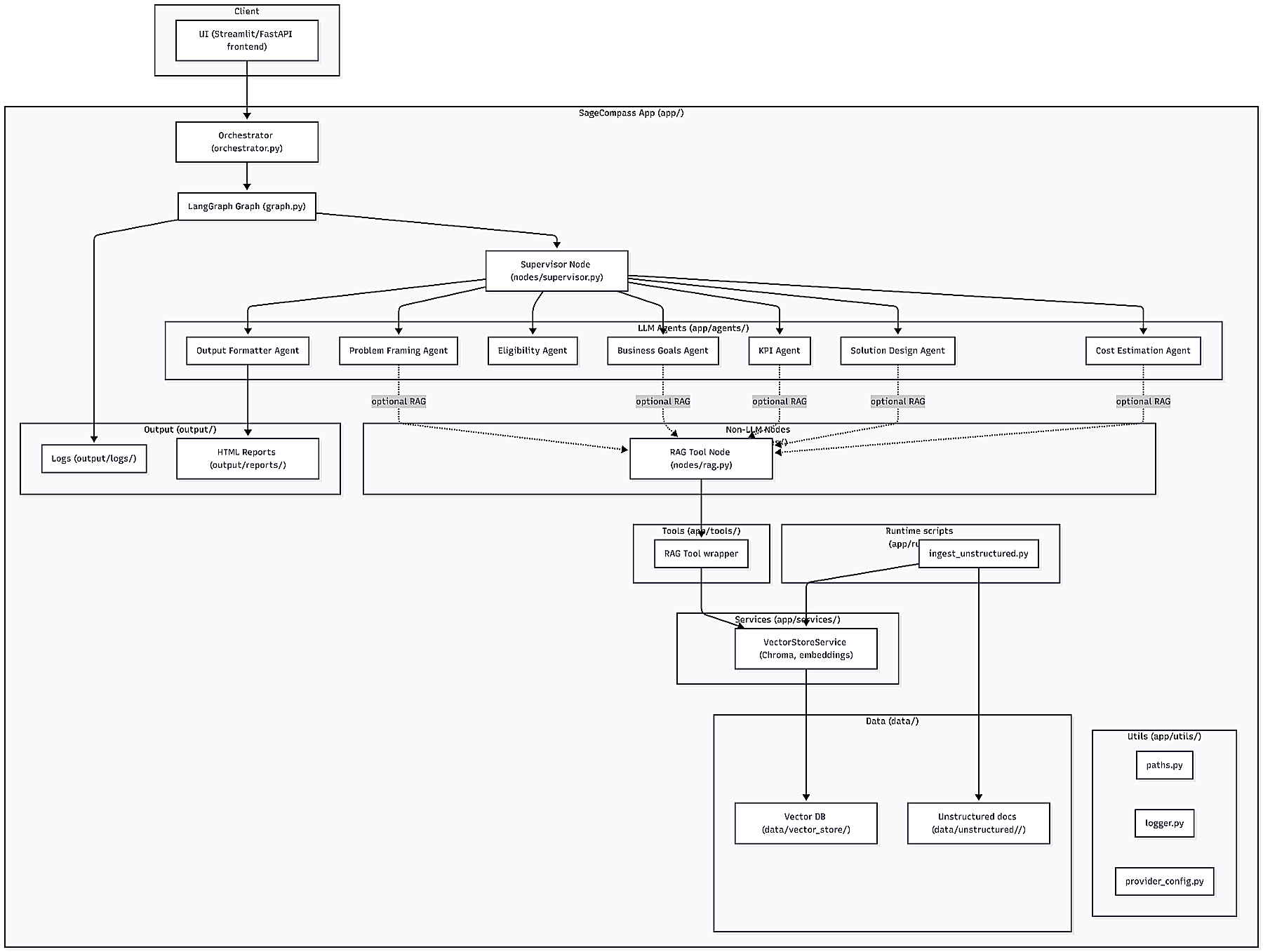
It also would be nice if data would come from a curated source, like a Drupal CMS for example.
And that's where SageCompass started forcing architectural decisions.
Drupal needed its own place. LangGraph needed its own place. And if I wanted to do this properly, the UI had to be separated from LangGraph (Gradio UI was still living under the same Python project).
So I reorganized the repo.
And that was when a core issue was immediately surfaced:
There were no rules.
For example: there was no project-wide rule for referencing file locations, because in the early prototype I could take shortcuts and everything still worked.
... Shortcuts are always the longer road in the long run.
And it wasn't just paths.
There were no solid architectural rules for Agents, Nodes, middleware, schemas.
No rules for state management. Prompt management. Tool management.
It was all still ... duct tape and hope.
It gave me back that late v3 feeling, where every change was a nightmare. Touch one thing, five other things break, and suddenly I'm debugging the project instead of building it.
So I decided to slow down and get into control.
The goal of v6 became crystal clear:
- make the existing implementation smaller
- lock down the architecture so I can add LangGraph components without surprises
- add quality assurances so the system behaves deterministically, even though it's an LLM-based augmented decision system
SageCompass v6 is currently here. It only has one of the v5 Agents (Problem Framing), but it has the stuff that makes a platform a platform:
| Rule/Contract | Description |
|---|---|
| Enforced architectural contracts | Platform contract map + tests that fail if you break it |
| Typed models and state | Pydantic everywhere, so the runtime has something solid to hold onto |
| Reusable subgraphs and nodes | Clear phase boundaries instead of “giant pipeline code” |
| Guardrails and deterministic tool policies | Allowlists, bounded behavior, no surprises |
| Ambiguity detection + bounded clarification loops | Scoped, retry-limited, no infinite “can you clarify?” spirals |
| Namespaced artifacts and context | Retrieval doesn’t just bloat the system prompt |
| Bigger test surface | Contract tests + integration coverage |
| Long-term memory | Context can persist without turning prompts into novels |
v6 is where platform behavior became enforceable: if you violate a boundary, tests fail; if a tool is not allowlisted, it cannot run; if ambiguity persists, clarification retries are capped.

What exists in the repository today
SageCompass repo: https://github.com/cleverhoods/sagecompass
Right now it contains:
- ambiguity detection subgraph
- problem framing subgraph
- main supervisor graph
- a RAG writer graph that takes information from Drupal
Other pieces exist as roadmap items, but they are yet to be implemented. I'd rather be explicit about that.
What to expect in this series
Each next post will take one architectural idea and tell its story from problem → messy attempts → final approach → lessons.
The next four posts are:
- Project architecture — repo shape, boundaries, and why "where things live" becomes a runtime feature
- RAG with Drupal — curated context without turning prompts into novels
- Contracts & guardrails — making safety and behavior testable instead of wishful
- Ambiguity detection — when "unclear input" becomes an orchestration problem, not a UX problem
Final words
If you're building agentic systems that need to behave reliably under ambiguity, or systems that integrate with real content sources like a CMS, follow along - next post is Project architecture (repo boundaries as a runtime feature).
Special thanks to Liudmyla Ravliuk and Erik Poolman for proofreading and mental sparring.
If you have fun with similar problems, find me on LinkedIn.
I'm always happy to compare notes.
Sources / credits
- Header comic: https://gunshowcomic.com/513
- SpaceX Raptor image: https://x.com/SpaceX/status/1819772716339339664/photo/1

Top comments (0)