As you know, a naming convention is a set of rules for choosing the character sequence to be used for identifiers which denote variables, types, functions, classes, objects and other entities in source code and documentation.
The most important reason for using a naming convention is to reduce the effort needed to read and understand source code; also many companies have also established their own set of conventions.

In this medium post, I want to share with you a set of simple and straightforward rules to write better, beautiful, effective and most readable CPP code in both Windows and Linux environment distinctly with a minor code modification because Linux and Windows has a different set of naming convention.
In this framework, I provide a set of rules for the following entities (I will complete it in the future):
- Local variable
- Global variable
- Functions
- Classes
- Methods
- Fields
- Structure
- Arguments
- Objects
- Namespaces
- Templates
I called this coding convention Milad CPP Syntex (MCS) for future referring to them and also giving this chance to myself to working on it for the CPP committee and community.
Variables
Based on my experience, specifying variables with the first character of their type and their storage classes is the best way to express them at the source code level.
In the following example, this naming convention for variables has shown in Windows (Visual Studio) and Linux (NeoVim):
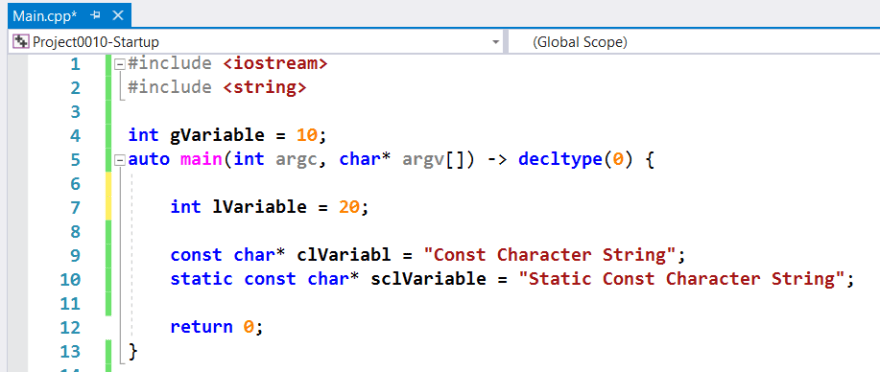
Because Microsoft uses the Camel notation for naming its native APIs and variables of Windows OS, we should use this notation too. In Linux, in contrast to Windows, we have a different approach to name entities.
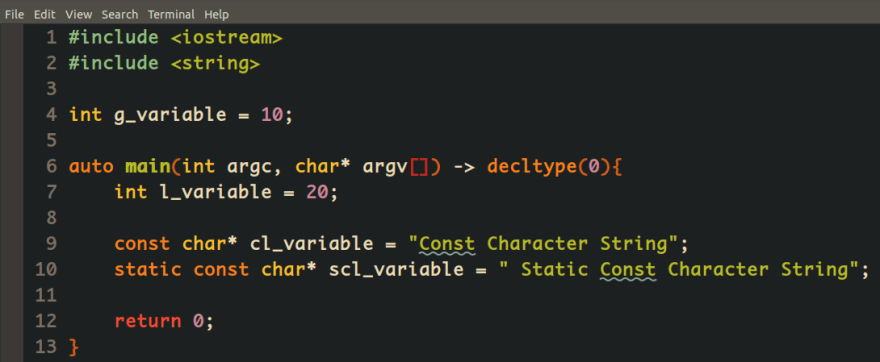
Linux is using a lowercase sequence of characters with the underline for naming variables or functions or other entities, so we should define our variables and other entities based on that naming convention for the sake of the compatibility with the environment itself. The above code is based on that standard which Linux is following.
Free Standing Functions
When we are programming with the Procedural Paradigm in Modern CPP, functions, and structures are the most important entities for us.
Naming functions and structure with a descriptive and self-contained name are so crucial for writing and also reading the CPP code in both Windows and Linux OS.
However, since Windows kernel interfaces (APIs or COM Interfaces) like WriteConsole is named with Camel style and also an Uppercase character at the beginning of their definitions, and also C functions defined with a lowercase character and short descriptive like wcslen, we should use similar convention with Windows Interfaces for our user-defined free-standing functions.
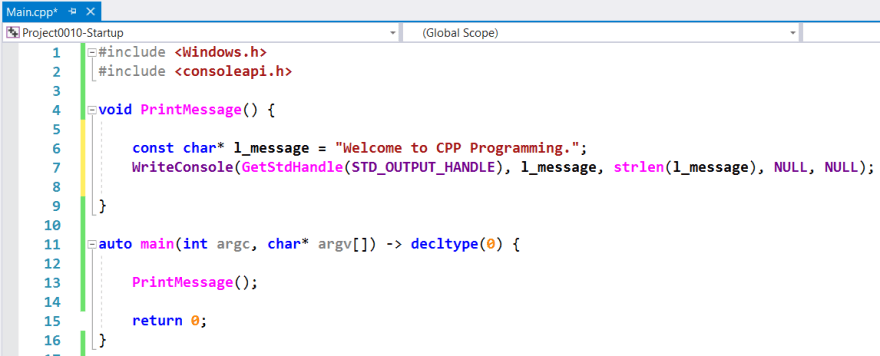
So the best way to define a free-standing function in Windows is using the Camel notation with Uppercase character at the beginning like PrintMessage in the above example.
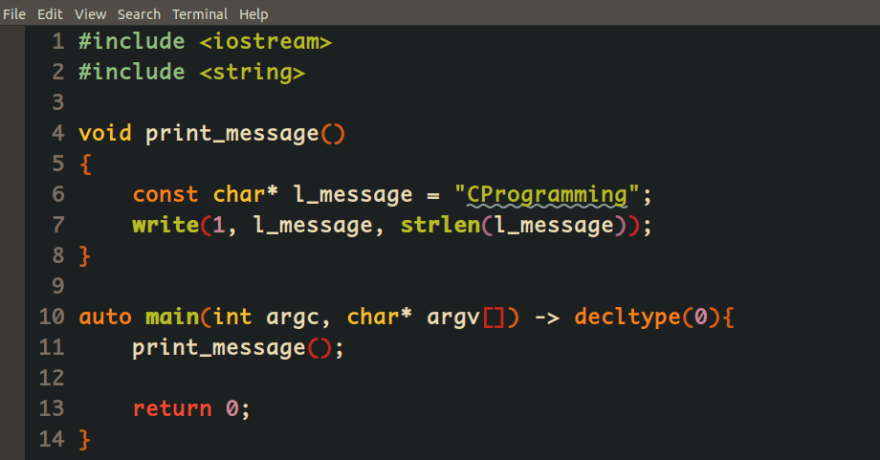
In contrast to Windows, It is better we define user-defined functions in Linux with lowercase character and separated each word with an underline because everything in Linux from POSIX and SUS interfaces to C/C++ libraries is based on lowercase characters, underscore separation and short names.
Functions (and Methods) Arguments
As you know, there is a subtle difference between the arguments variable and other types of variables. So we should make some distinction between arguments and other variables in our source code.
It doesn’t matter in what environment we are writing cpp code, we should specify arguments with a prefix like arg_ or arg or other prefixes to make them as clear as possible like the following example.

Same with Windows, we should follow this rule in Linux too. It makes our code self-descriptive, self-contained and also beautiful. Now we can simply read the code and interpret it without any confusion with other types of entities.
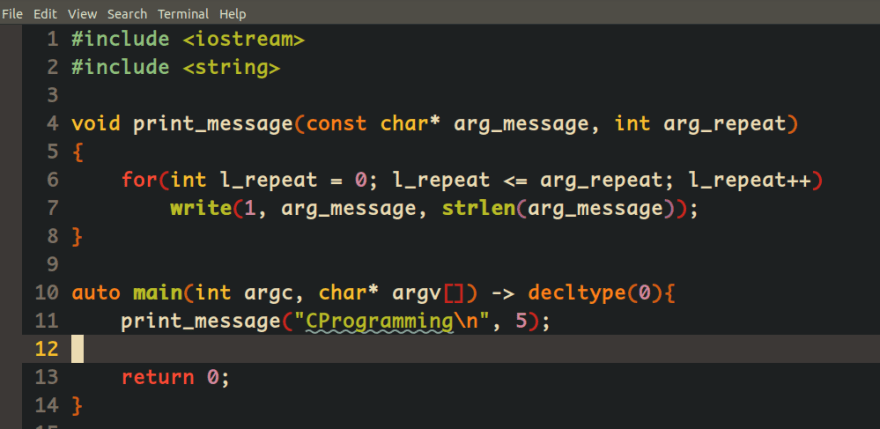
Structure and Classes
There is a set of the difference between Classes and Structures in CPP language but the concept of them is similar to each other (At least from Object-Oriented Programming perspective).
Nevertheless, when we are writing cpp code with OOP or Procedural paradigm, we need classes and structures respectively.
So we should have a well-defined convention to define them because they are the most important entities from object-oriented and procedural paradigm programming and also software engineering/development with modern cpp.
In order to define Classes and Structure blueprints, we should use UpperCase and Camel based definitions like the following example:
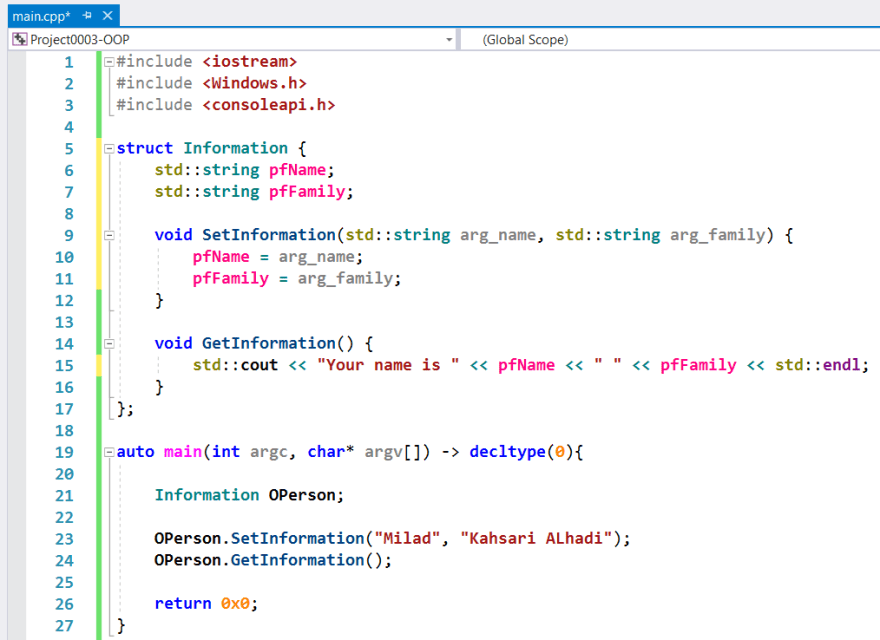
Also, you should consider the method definitions in the structure blueprint example. In similar to the free-standing functions, we should define methods (Functions in the classes or structures) also with Uppercase character at their beginning and Camel notation.
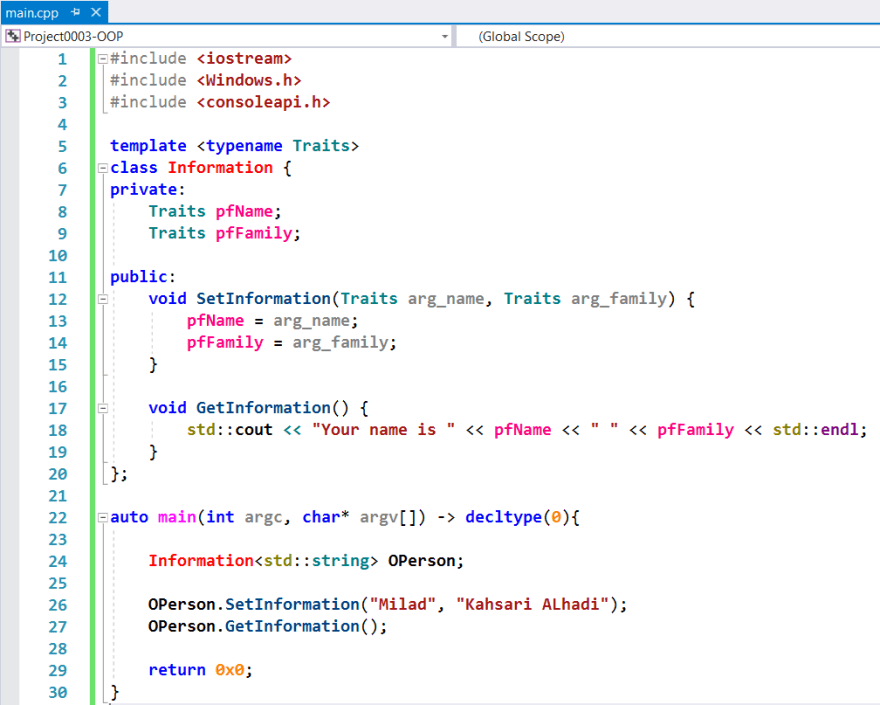
It is also recommended to define the object instance of the Information blueprint with a capital O character in Windows and o_ in Linux. In the following example, I define a class with the same concept of the above structure.
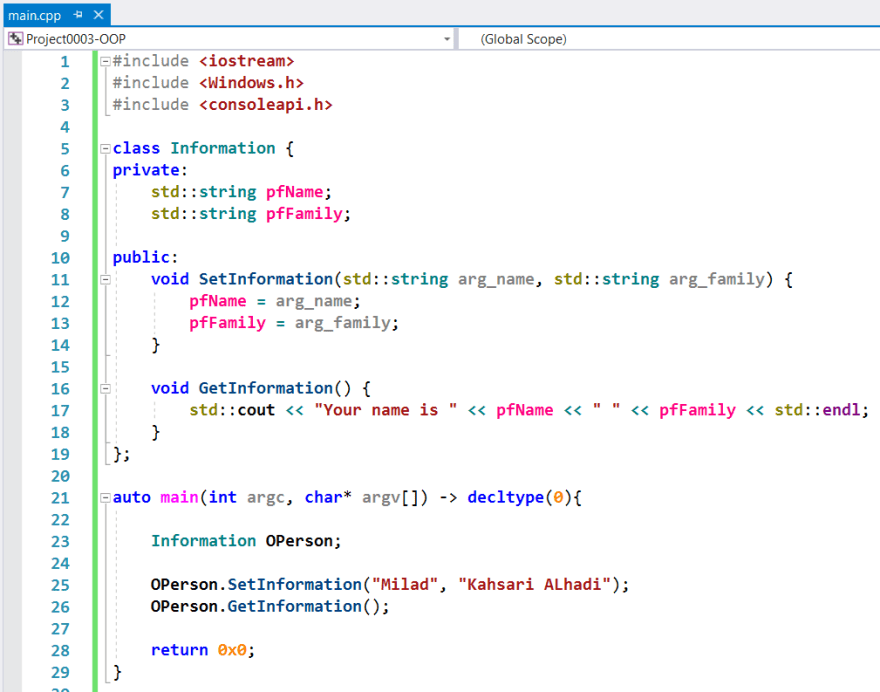
In Linux, we should define the above code with a small modification in the methods definitions and also object instance. It is recommended we follow the Linux naming convention everywhere. Because of that, it is better in Linux we define methods like other functions with lowercase and underline.
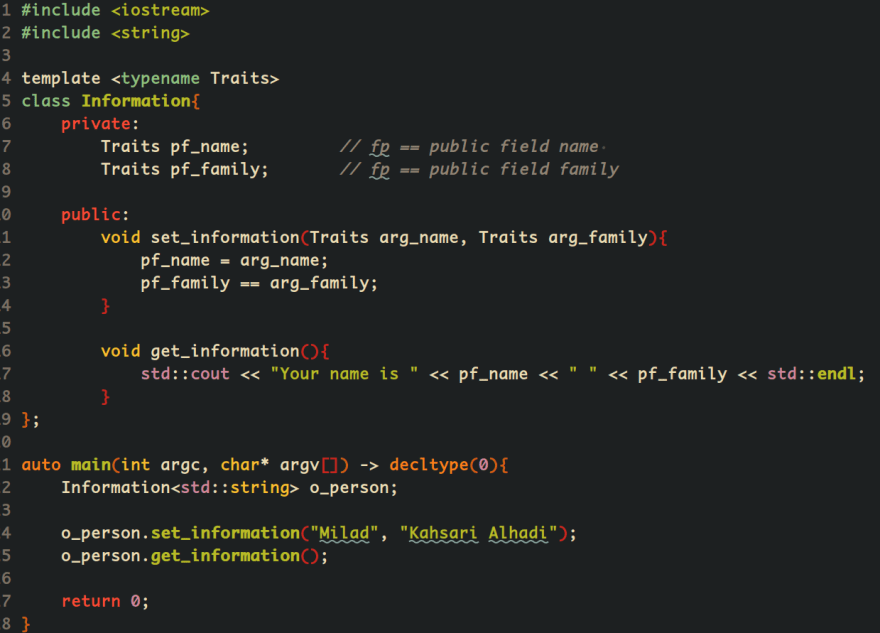
However, with this notation, we can understand which is not a simple user-defined entity now. Also, you should take care of one important concept in naming fields when you are writing code with C++. Unfortunately, some programmer uses double underscore at the beginning of the name of their fields member which makes undefined behavior at practice because compiler uses __ at the beginning of their identifier. So, we should not define fields member with double underscores because:
The use of two sequential underscore characters ( __ ) at the beginning of an identifier, or a single leading underscores followed by a capital letter, is reserved for C++ implementations in all scopes. You should avoid using one leading underscore followed by a lowercase letter for names with file scope because of possible conflicts with current or future reserved identifiers.
Nevertheless, it is better we define fields of a class with their type and accessibility. For example, in the above example, I define all fields with pf (public field) to make a difference between class fields with other entities.
Now, with simple observation, we can see the difference between each element in our source code. In addition, our code has now become more legible, also its simplicity has been greatly improved.
Templates
Templates are the foundation of generic programming, which involves writing code in a way that is independent of any particular type. A template is a blueprint or formula for creating a generic class or a function. The library containers like iterators and algorithms are examples of generic programming and have been developed using the template concept.
However, in most of the example code, documentation and … when someone going to define a template, it uses or something like that. But it decreases the reading of the source code. We should use meaningful words rather than just T or Tr or …
Also, in Linux, we should use the same naming convention of template for our code. It makes our code so meaningful as possible as when we are involved with metaprogramming.
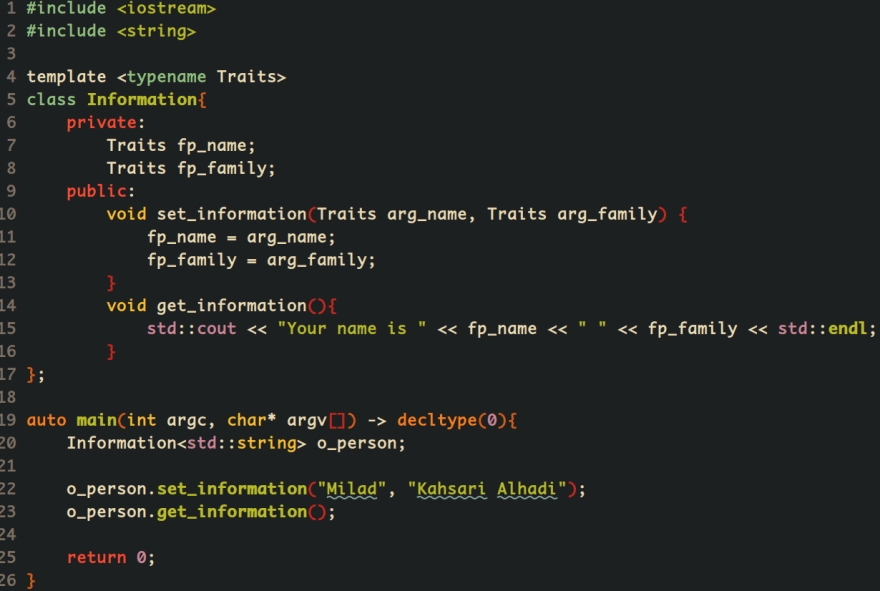
I used the above naming convention in my career since 2012. I think it is the most useful naming convention for professional and also a newbie to look at your code and comprehend it. If you have any comments, feel free and send it to me.

Top comments (0)