Recently on Twitter, I was asked by @thegraycat on whether I knew of any resources to manage pipelines in version control. I sent across several top of mind thoughts over Twitter, but it got me thinking that there may be others with the same question and it could make a good blog post. So here we are, as I talk through some of my considerations for pipelines as code.
 thegraycat@thegraycat
thegraycat@thegraycat @reddobowen Hey, Chris. You might be able to point me in the right direction - are there any good resources on how manage your #azuredevops pipelines in git for versioning etc? Cheers.15:11 PM - 02 May 2021
@reddobowen Hey, Chris. You might be able to point me in the right direction - are there any good resources on how manage your #azuredevops pipelines in git for versioning etc? Cheers.15:11 PM - 02 May 2021


Coincidentally, I'll also be releasing a Cloud Drop tomorrow on the topic as well.
Firstly, what are pipelines as code? Pipelines as code are quite literally as the name implies. Rather than creating your build and deployment pipelines through a user interface, you would treat it exactly like your application or infrastructure code, creating and storing the pipeline code within your repository.
Many providers are now offering this functionality, including Azure DevOps, Circle CI, GitHub, Gitlab, Jenkins and others.
In this post, we'll be focusing on Azure DevOps' Azure Pipelines implementation.
Yes, source control your pipelines
Absolutely source control your pipelines. Why? You get the same benefits as when you source control your application code or infrastructure code. Not limited to, but including the ability to:
- Roll back your pipelines to a given commit version
- Use branch policies in your repository to enforce a review process
- Work in parallel across multiple branches without impacting other developers on the team
- Continue developing your pipeline code in a separate branch without impacting your production codebase
- Put your pipeline code through a Continuous Integration (CI) / Continuous Deployment (CD) process, which could include static code analysis.
Can you see the benefits over using a User Interface approach directly, and it being stored as part of the DevOps service/platform? There's plenty, and I'm sure there's more that I haven't listed here - so please continue the discussion over on Twitter.
With that, let's continue our journey with pipelines as code. First off, I start with a brand new Azure DevOps project in my Azure DevOps Organization.

We'll first need to have an initialised Git repository available before we can create a pipeline as code. For the purposes of this post, I'll be initialising the default Git repository in my Azure DevOps project.
Let's first navigate to the repository and initialise it with a README file.
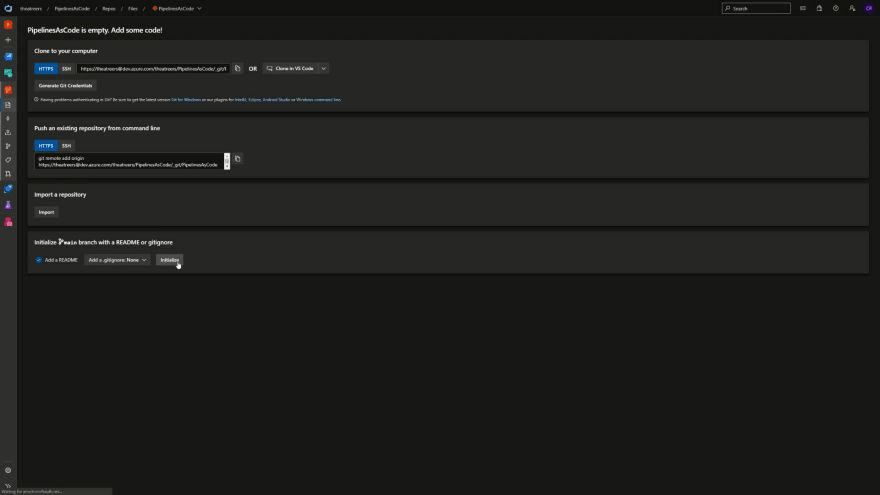
Now that's completed, let's go ahead and create a pipeline. To do that, we'll navigate to the Azure Pipelines tab, and select pipelines. Go ahead and click the New Pipeline button to begin the process.
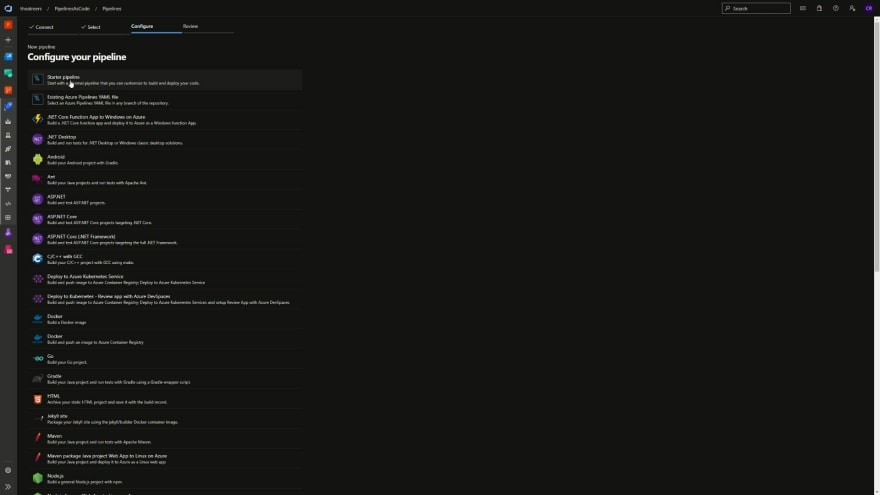
In the first stage of the pipeline creation process, you'll see that we're not just limited to storing the code in Azure Repos. We can also store the code in Bitbucket Cloud, GitHub and GitHub Enterprise server as well. We'll select Azure Repos Git, and the repository that we initialised a few moments ago.

On the next page, you'll see that we have options to configure the pipeline. Not only can we create a starter pipeline, or use an existing Azure Pipelines YAML file, but we can also create a pipeline file based upon several samples pipeline configurations. For the purposes of this post, we'll be creating a starter pipeline. Hopefully this gives a bit of insight on how you can get started quickly defining an initial pipeline depending upon your scenario.
Now, we'll see the pipeline editor. We're not going to make any changes at this stage. Instead, we're going to hit the dropdown option on the Save and Run button, and just click save. You'll notice that we have to commit the changes to a specific branch in a Git repository. For now, we'll store this in the main branch.

What about our branching strategy and pull requests?
The problem with this approach is that it doesn't honour any existing branching strategies that we may want to follow. Committing directly to main isn't typically considered a recommended practice, as that's usually our production codebase. To ensure that our production code is protected, we can use branch policies to ensure that specific requirements are fulfilled before a commit is allowed to a given branch. For example, we could ensure a peer review is required prior to committing any code, a specific build has successfully completed, or that our commits must have a work item associated for traceability purposes.
Head over to the Azure Repos section of your Azure DevOps project, and select branches. Hover over the main branch, and select the ellipsis, allowing you to configure branch policies for that branch.
For the purposes of the blog post, I configured the following policies:
- Require a minimum number of reviewers to 1
- Allow requestor to approve their own changes

In a real-world scenario, I would likely not allow a requestor to approve their own changes, and would have minimum number of reviewers set to at least 2 (depending on the size of the project team). I'd likely also have Build Validation configured with a set of unit tests, and check for comment resolution as well. This ensures that there's a certain level of rigor before any code is allowed in our production codebase.
With that in place, once we navigate across to the Azure Pipeline and attempt to save a change directly to the main branch, we'll encounter a failure because of the branch policy.

Switching the branch to another branch allows us to save the changes. You can do that by selecting the Create a new branch for this commit option and enter a branch name of your choice.
Azure Pipelines - Environments, Templates, Jobs and more
Let's go ahead and evolve this basic pipeline into a multi-stage pipeline. Here is an example of a multi-stage pipeline YAML file:
# Starter pipeline
# Start with a minimal pipeline that you can customize to build and deploy your code.
# Add steps that build, run tests, deploy, and more:
# https://aka.ms/yaml
name: "My Pipeline as Code Pipeline"
variables:
myNewVariable: "MyNewValue"
trigger:
- main
stages:
- stage: "build"
displayName: "My Pipeline as Code Build Step"
dependsOn: []
variables:
myStageVariable: "MyNewStageValue"
jobs:
- job: "MyBuildJob"
dependsOn: []
pool:
name: "Azure Pipelines"
vmImage: "ubuntu-latest"
steps:
- task: CmdLine@2
inputs:
script: |
echo Step 1
- task: CmdLine@2
inputs:
script: |
echo Step 2
- job: "MyBuildJob2"
dependsOn: []
pool:
name: "Azure Pipelines"
vmImage: "ubuntu-latest"
steps:
- task: CmdLine@2
inputs:
script: |
echo Step 1
- task: CmdLine@2
inputs:
script: |
echo Step 2
- stage: "dev"
displayName: "My Pipeline as Code Dev Environment"
dependsOn: [build]
variables:
myNewVariable: "My Dev Value"
jobs:
- deployment: "MyDevEnvironment"
pool:
name: "Azure Pipelines"
vmImage: "ubuntu-latest"
environment: "MyNewDevEnvironment"
strategy:
runOnce:
deploy:
steps:
- template: templates/example-steps.yml
There are a few key points to call out here:
- We use the
stagesproperty, with multiple- stage: "value"elements to define each stage of our multi-stage pipeline. - A stage can have variables associated with it, if we want to have per stage (or environment) configurations set.
- We use the
dependsOnproperty to define the ordering of the stages.dependsOn: []is a way of explicitly saying there are no dependencies. You can also use the[]syntax to depend on multiple environments, e.g.dependsOn: [stage1, stage2, stage3]. - We can define multiple jobs within a stage. Jobs are the 'building block' for an Azure DevOps agent. Each job will be assigned to a new Azure DevOps agent. This is particularly worth noting if you're using the Hosted Azure DevOps agents, as this will mean you get a fresh agent for each job.
- Jobs can be used in some interesting scenarios. You can define multiple jobs manually if needed, and either run these in parallel or one after another.
- A particularly interesting use case for jobs is by using a matrix. By defining a job once and using a matrix, you can ensure the same job is executed with multiple configuration options. Consider the scenario where you need to test a build across multiple operating systems (Linux, MacOS and Windows), and multiple versions of a dependency (e.g. NodeJS).
- Notice that the dev stage has a different job type underneath the jobs property, called deployment.
- The deployment type allows a sub-property of
environmentto be defined. The environment is a logical mapping to an environment configured in Azure DevOps (more on that later!) - We define a
strategy. This exposes a number of 'lifecycle hooks' that may execute a different set of steps, depending upon the point in the lifecycle. There are a few different types of strategy that we can use. - runOnce - This is the simplest deployment strategy, and will execute the steps once.
- rolling - This strategy is only supported to Virtual Machine resources. This gradually replaces instances with a previous version of the application with the newer version.
- canary - Roll out changes to a small set of servers, specifying an incremental approach to route traffic to the estate.
- Below the strategy property, we can once again define the steps for that particular job. Notice that this time, we're not defining a series of tasks? Instead, we're using a
template. A template allows us to define a reusable set of steps and logic. Imagine a scenario where we're deploying across multiple Azure regions or multiple environments, and it requires the same tasks to be used consistently. This would be the perfect opportunity to use a template, especially as we can define parameters in the template to ensure reusability with a different configuration per environment.
- The deployment type allows a sub-property of
So with that, let's look into the template file -
parameters:
- name: yesNo # name of the parameter; required
type: boolean # data type of the parameter; required
default: false
steps:
- script: echo ${{ parameters.yesNo }}
Notice how the single parameter of yesNo is defined? It's a Boolean, and is set to a default of false. That means that we don't need to specify a value in the main YAML pipeline, but can override it if needed. This gives us the consistency we need across environments, but flexibility of configuration per environment.

Azure Pipelines - Environments (Approvals and Checks)
Okay, great - we have a multi-stage pipeline and are using a template to allow for future reusability and consistency when making new environments. But, we defined an environment earlier. What is that used for? Let's navigate to the Azure Pipelines section of our project, and click on Environments. Notice that the environment is already created? This environment is a logical concept, which gives us a couple of benefits -
- We can easily identify the deployments across several pipelines that have made their way into this environment.
- We can add a requirement for manual or automated approvals against an environment. This means that the deployment will not automatically proceed unless the requirements are fulfilled.
To demonstrate this, click on the environment that you defined and has been created for you. Select the ellipsis (three dots) and hit Approvals and checks. This is where you can add the manual or automated approvals. Add an approval, and configure the approval steps to your liking.

Once you've completed that, navigate to your pipeline and trigger a new pipeline run. Wait for the pipeline to reach the stage which had your environment defined. In my example, that was dev. You should notice that the pipeline will now pause, awaiting a manual approval.
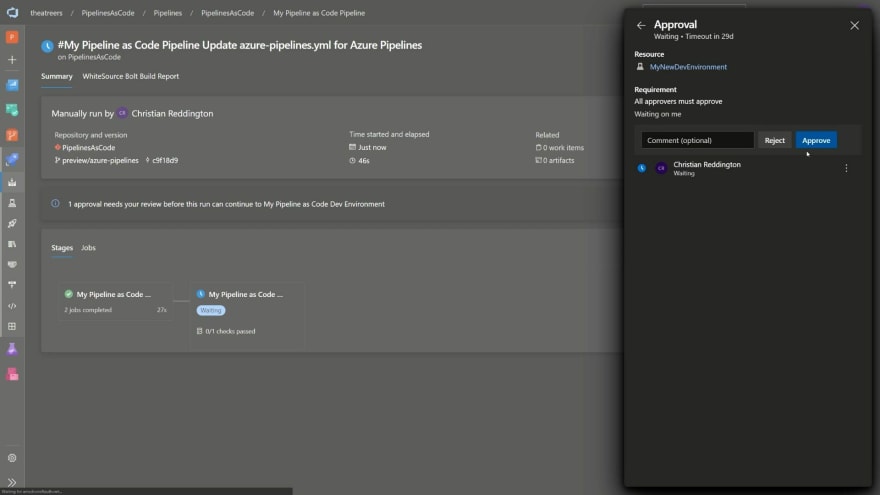
Looks good to me - Pull Request and Merge
Now, to complete the story - We need to merge our changes back into our production codebase. We may have created a pull request earlier on. If that's still open, go ahead and merge that one. Alternatively, head to the Azure Repos section of your Azure DevOps project, and click on Pull Requests. Create a new pull request if you don't have an existing one in place.

Progress through the pull request flow, providing your approval and merge the changes to main.

Finally, head back to Azure Pipelines. Notice that your pipeline has been triggered based upon a CI/CD trigger (i.e. the merge commit to our main branch).
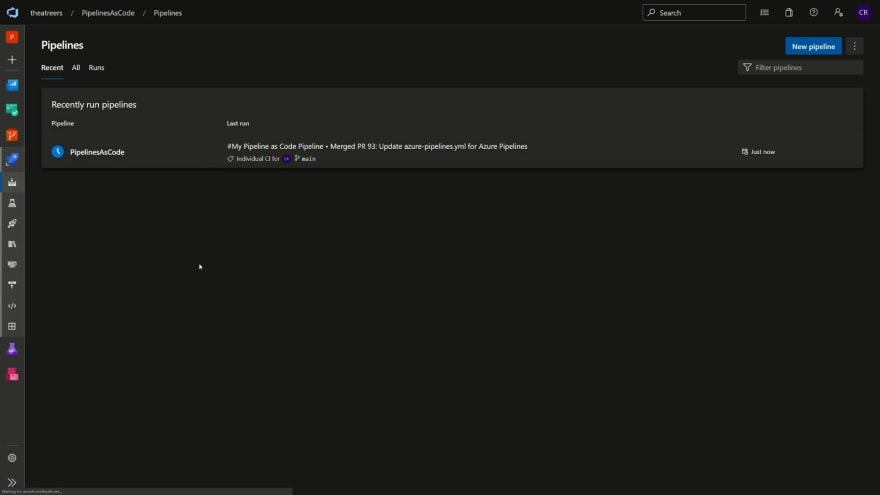
And that's it! That's an end-to-end view of using pipelines a code, branch policies, environments, pull requests and more. If you've version controlled your application code or infrastructure code previously, you should be able to draw parallels with some of the themes in this blog post (e.g. branch policies and pull requests to ensure quality in our production codebase, using a Continuous Integration (CI) or Continuous Deployment (CD) process to progress our pipeline changes, and the ability to work on the pipeline code in parallel while developers may be making changes in their own branches).
So, there we go! Don't forget to check my YouTube channel, as there will be a video coming out on the same topic tomorrow if you prefer learning through video content. I hope that this has been useful. As always, I'd love to continue the discussion over on Twitter, @reddobowen.
Until the next post, thank you for reading - and bye for now!

Top comments (0)