Introduction
There are dozens of machine learning competition platforms out there, with thousands of hot challenges on them. These are excellent places to learn, build your data science portfolio, meet with smart people, and perhaps earn some money.
If you are interested in the subject, you have probably tried out some of them, like Kaggle, AIcrowd, DrivenData, and many others.
So, why did me and my friends decide to build another one?
Crowdsourcing and the development cycle
Let's take a look into how the development of a machine learning solution is done!
Just as for other software tools, the development workflow here is a cycle as well.
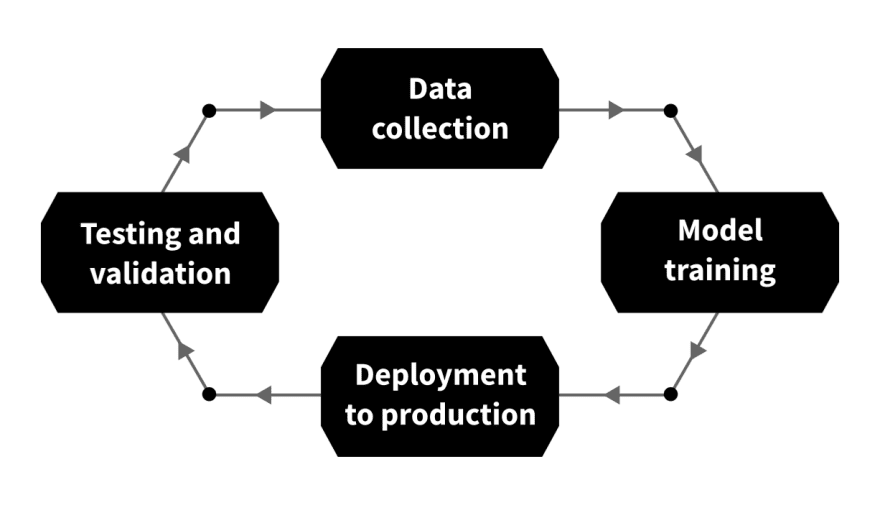
The main steps are the following.
- Data collection. Once the problem is formulated, data has to be collected to provide training and test sets. In some cases, the data is collected before the problem is even clear.
- Model training. This is the part that is most exciting for data scientists: coming up with the architecture of the solution and training a machine learning model. However, this takes up only a small percentage of the total workload.
- Deployment to production. If the model is ready, it has to be prepared for production use. This involves quality assurance, packaging it into an API, securely deploying it to production servers, etc.
- Testing and validation. When a model is used in production, new and unexpected problems might arise. Suppose you train a classifier that recognizes the brand and the model of a car, but a manufacturer issues a new model. The classifier no longer works correctly, so you have to go back to the beginning, collect more data, train a new model, and so on.
As we know it, a machine learning competition only covers a small part of this process: the model training. What happens before and after is unrelated to the competition and done by an internal team instead of thousands of participants. Effectively, crowdsourcing only covers a small portion of the work.

We want to change that.
Crowdsourcing for production
How can we involve the participants of a challenge in the entire process? There are several opportunities. For instance, I have participated in competitions where participants noticed problems with the training data labels right away, yet nothing changed for the entire duration. In others, participants have cheated their way to victory by downloading the private test dataset and overfitting the model on that.
At best, the result is a proof of concept; a baseline. At worst, it is useless.
We've come up with the idea that would make the entire process dynamic, involving competitors and challenge hosts in the development cycle.

Simply speaking, instead of rewarding the top 3-5 solutions at the end of a three-month period and conclude the competition, we would reward the best solutions every week and deploy them to production-like environments.
When issues arise, like mislabeled data, it can be fixed by the next round, and the solution can keep improving constantly.
On the other hand, we believe that this would be more rewarding for participants as well. If you are working hard on the competition, staying on top of the leaderboard for months but get outcompeted during the final hours, you receive no reward. We think this is unfair, and consistency should be rewarded. So, our idea is to issue the rewards every week.
In brief, our goals are
- to connect the machine learning community to the industry through exciting problems,
- to provide a more rewarding competition platform for developers,
- and to integrate crowdsourcing to the entire development life cycle.
What do you think?
We are asking for your feedback!
So far, we are at the beginning of our journey. We set up an early release version that you can test at https://telesto.ai. Currently, we are just testing out our platform with a competition to diagnose COVID-19 based on cell microscopy, but more is coming soon!
We want your feedback on our idea and the execution so far. We are building this platform for you, and we aim to provide the best experience out there!



Top comments (3)
This sounds like an intriguing approach.
as a complete beginner to machine learning is this website for me?
Hi! At the moment, we don't focus on educational content, we are working on building up the platform. However, in combination with other learning resources, machine learning competitions can supercharge the learning process, so I would recommend giving them a shot even as a complete beginner.