
What is this actually for:
Full stop, CueMeet is an open-source platform to build meeting bots. After COVID hit, everyone and their mother has been trying to build zoom/google meet/microsoft teams meeting bots for different applications. Whether it was the meeting assistant companies like Otter, Fireflies or Rally building meeting bots to augment their user research platform, meeting bot infrastructure became a critical piece of software for the next generation of SaaS companies.
Ok, but don’t the meeting bot providers have something:
So, since meeting bot infrastructure is critical – you would think that there is a lot of software out there that basically offers this infra out of the box to build into your application. After all, zoom has their own meeting SDK to facilitate building meeting bots and Microsoft teams has something similar. However, these services are complete dogshit. Here is an example of this. The zoom developer forum is just filled with posts of people trying to bang their head trying to figure this out (don’t get us started on Microsoft teams or google meet). It's pretty clear that these meeting providers just don’t fucking care to support this growing demand.
Pardon me for the technical jargon and complicated language but I like getting my point across
Enter Recall
Then along came Amanda Zhu, the supposed Robin Hood!
The knight in shining armor. She poured hours across all the Zoom forum posts trying to help people build bots. And being the entrepreneurial spirit she was, she built out Recall. A unified API for meeting bots across all platforms. It was a genius idea. No longer did a developer have to develop separate services for each meeting provider. You hit one endpoint and you could easily access them all. She provided it as paid software where we had to pay a nominal monthly fee (about $50 bucks a month and a few cents a minute). And, it wasn’t free – BUT, she was providing a ton of value so it was probably worth it. While it would have been nice if they had open-sourced, they still provided a solution that was worth paying for.

We don’t do free trials. If you’re not willing to put down a deposit… | Amanda Zhu | 133 comments
We don’t do free trials. If you’re not willing to put down a deposit, you’re not serious. We thought free trials would help close more deals. They… | 133 comments on LinkedIn
 linkedin.com
linkedin.com
Recall Starts to Scalp
Ok, this might be too aggressive of a statement. In fairness, I respect Amanda for everything she has done and how she is building. She has recognized an extreme gap in the market and is basically the only player that provides a solution of a universal meeting bot SDK. In accordance with that, she is charging $1000/mo base + $1 per MINUTE ($60 per HOUR) recorded. To put things into context, her per HOUR unit cost that she incurs on her for each meeting bot is likely somewhere between $0.01 to $0.03 (again this is per HOUR). There is an additional cost which is the transcription service itself. It’s highly likely Recall is using a service like Assembly or Deepgram for this which ranges from $0.12 per hour to $0.75 per hour of audio. All up her unit costs for each bot are between $0.22 per hour and $0.88 per hour.
That means the margin she extracts is over 98% - 99%. The $1000/mo base is something that has been evolving for her too. It used to be $50/mo, then it became $150/mo, and now it is $1000/mo. Here is what I thought she could be trying to hedge against with that pricing. There are basically two other cost centers per meeting. The first is asset storage into s3 or some type of CDN. For this – think of things like the meeting transcripts, the audio/video streams, meetings metadata, etc. The second is probably the additional infrastructure that she is using to serve the APIs and SDKs themselves.
The servers are hard to quantify but they likely are pretty negligible since the horizontal scaling of servers doesn’t have to be linear with usage with load balancers and the nature of the traffic itself. On the flip side, s3 does charge at most $0.23 per GB stored. If she is storing video data, this can start to add up. 1 TB can store about 500 hours of 1080p videos which at the unit price described is about $25. That could get super costly if everything was incrementally accumulated over time. But here’s the thing, Recall doesn’t even store the videos permanently. They delete the data after 7 days. This means their overall s3 costs across all customers is probably not more than $100 to $1000 a month. This means that if Amanda has 700 customers like she claims (she says 700+ but I’ll assume 700 as the minimum), the unit cost per customer is about $0.15 to $15. This cost actually goes down per customer since the auto-deletion after 7 days means that the cost grows less than linear relative to the number of customers she is getting. This means that on that $1000/mo, Amanda and Recall are once again getting 98% - 99%+ margins on this part of the revenue as well.
Again, deep respect for mastering the unit economics and then capitalizing on the market demand. Amanda and Recall are basically a monopoly. And being the stellar hustling entrepreneur that she is, she is trying to get as much money as possible. And she is further securing that by NOT OPEN SOURCING her software. Basically, she is brilliantly executing on the monopolistic buyer surplus from those good old supply and demand graphs from ECON 101:
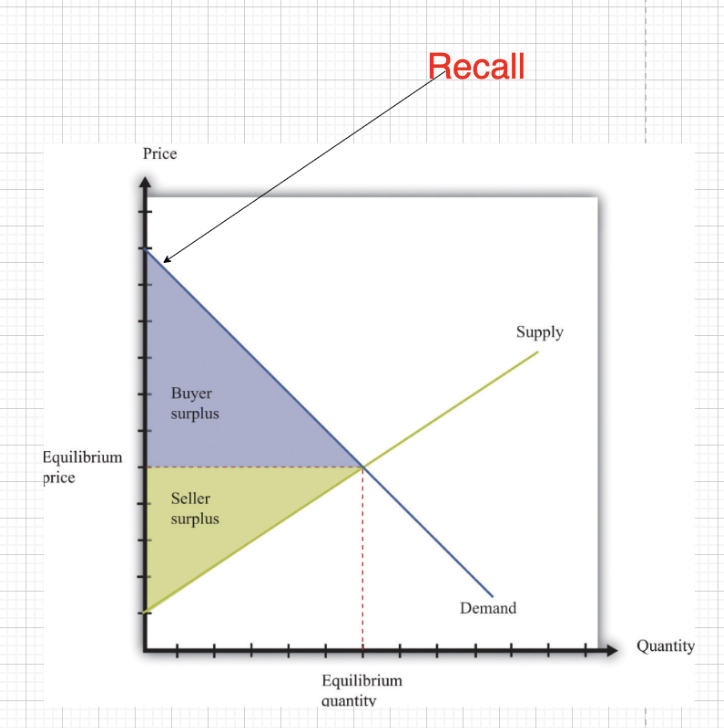
"Ok…but what about the lower equilibrium price??"
Yeah, this is valid. After all Jeff Bezos once said, _“Your margin is my opportunity.” If Recall is making so much margin, why aren’t other people and companies trying to do this?
Let’s start with some basic data to try and answer this. We went on GitHub and searched the following terms:
- Zoom Meeting Bot → 150 results – Search Query
- Google Meeting Bot → 64 results – Search Query
- Teams Meeting Bot → 17 results – Search Query
Basically, there are, at best, ~250 repositories out there doing something with regard to meeting bots. Relative to each of these repos, we have gone through EVERY. SINGLE. ONE. of them. And none of them outside of 1, are even remotely production deployable. Additionally, all of these are specific to one kind of bot so to even try to use any, you would need to hack multiple together (assuming you could even make this prod capable).
And this is the crux of the problem:
Meeting bot infrastructure is "REALLY. FUCKING. HARD. to build."
Here are a few reasons why:
The Zoom SDK is so confusing and the documentation is so sparse, you basically have to create dozens of different hacks to work
Google Meet has no native SDK, so you have to use Puppeteer or some other web driver to step into the meeting.Microsoft Teams has the same problem as Zoom – tons of hacks have to be written to get the base-level functionality to work
Even if you get the application logic from above to work, you still need to deploy it out either into a cloud environment or on bare metal (if you are ultra-cracked) and get it to auto-scale based on usage (you better be a god at Kubernetes folks)
Then, you need to take the media streams and other kinds of metadata and process them asynchronously for things like transcript building
When you are generating transcripts and want to identify speakers → you’ll find this is super non-trivial because speaker diarization out of the box just takes audio and then generates some unique id →
You have to find a way to reconcile who exactly is the speaker which means you’ll need to do some other dumb hacks to get this to work
All of this stuff, as mentioned, is so hard that most companies don’t do it. To recall’s point (as they laid out on their website), if a company wanted to do this, you’d need to hire a team of developers for this,and I suppose in their estimation → that a company paying Recall $50K a year is still less than them paying 2-3 developers $300K to $500K collectively
And since there is nothing open-sourced yet that does something similar (yet), Recall will continue to be the monopoly in this space.
Tell me there is another way!!
There is in fact another way. That’s why we started the CueMeet project.
The idea is basically to create an open-source universal API for meeting bot infrastructure. Or put shortly, we want to be the open-sourced version of recall. All the hard stuff we described above, we’ve gone ahead and just done all of that ground up. We’ve modularized the code base. And now, we want to make it open to the world so they can spin it up super easily for themselves.
We’ve even dockerized the entire system so you just have to run a few commands to get this stuff running in your environment (we’ve also gone ahead to partner with some initial users who have graciously created video tutorials on how to do the setup). We’ve even built a system architectural diagram of all the components internally. To put it simply, with CueMeet, you can go from no meeting bot infra to serving meeting links to your own hosted API in under 30 minutes.
> Ok, but when is the rug pull going to happen?
Never, CueMeet will always be open sourced and that will always be free. We MAY decide to launch a hosted version (but it’s unlikely since we believe that this should be as cost effective as possible). That being said, if there is enough demand, we’ll entertain the idea. But again, we’d need a lot of people telling us they want a battery-included version of this. And if we do go that route, we will charge something exponentially less. Moreover, we would never ask anyone to pay more than $20 to $30 as a monthly charge for storage and things like that. We’re pretty cool not shooting for 99.99% margins – we just want to power everyone’s meeting bot infrastructure 🙂. No matter what, the open source version will always be a carbon copy of what we decide to host – so you are always using the latest and greatest of what we provide.
And no matter what, the open source version will always be a carbon copy of what we decide to host – so you are always using the latest and greatest of what we provide.
We would rather have Recall dramatically slash their prices. They have a good product (well actually, it’s great). But they are entering the scalping territory. And we need a counterbalance. Our hope is that this is the counterbalance. An amazing outcome for us is any of the following:
Tons of recall customers and potential Recall customers and former Recall customers use our repo and spin it up locally and stop using Recall, thus motivating them to dramatically lower their prices.
Other Recall competitors spinning up forking our repo as a base and putting extreme pressure thus bringing the cost of meeting bot infra down generally.
Having an army of open-source contributors adding to the CueMeet ecosystem makes it better for everybody.
How does CueCard Labs fit into all of this?
Yeah, this is critical. At our core, CueCard is an AI Sales enablement company. High level – we want to make it super easy for reps to sell by giving them a bunch of AI assistants to automate the manual work that reps have to do. One part of that was recording meetings and doing stuff with that. When we were trying to build this functionality – we actually tried to use Recall. And when we did, Amanda literally told us we weren’t big enough to use her tool. That we needed to go and get more money first (what a shitty response btw). She, and thereby Recall, cares more about the price tag on my head as opposed to the use case and mission of what we’re trying to do. We don’t want any company or person to have to go through that. That’s why, after we built our own meeting bot SDK ground up, we wanted to just share it with the world in a carte blanche way.
And that’s also one of the benefits too. We have no vested interest in monetizing this. We just really believe this technology should exist for everyone in a cheap way. We thankfully are able to make money in other ways. That allows us to support this project with such extreme aggression and in a way that’s just better for the world. In many ways, what Facebook/Meta was able to do with Pytorch and React, we want to do with CueMeet. And granted we are small – but that’s why we want to build a community around this – CueCard doesn’t have to be the only entity contributing to this.
Why are you all so altruistic?
I know in the world of virtual signaling, this might come off as hard to believe. However, we fundamentally believe it is a good thing for the world for this type of infrastructure to be as cheap as possible. Why? Covid kicked off a trend that we believe isn’t going to die soon. It moved a large portion of human interaction into the virtual meeting space (by 2022 close to 75% of all meetings were held virtually and the trend is only growing). Because of that, we believe meeting data is, perhaps, going to become one of the most valuable input data sources for training LLMs. LLMs have basically been trained on most of the available text on the internet. The next horizon is going to be human interaction data.
Eventually, for LLMs and ML models to get better, they need to have an easy pipe to this data. But they won’t if the cost to serve the infra to get this data is too high. That’s why we need more competition in the space, and we need some service that makes the process of getting this data really cheap. So, to address those needs, we built CueMeet and designed it in the open source. Open source always wins. This meeting bot infrastructure is going to become a bridge between LLMs and human interaction data. And if anything, we’d love more than anything if the world looked back on CueMeet like they did with Postgres, or Assembly, or general SQL: that is – transformative technology that moved the world forward.
To all of you who made it this far. Congratulations, you are part of the new generation empowering the open-source community.
Fork CueMeet. Customize CueMeet. Extend CueMeet.
The choice is yours, let us help you.

Top comments (0)