
Webscraping
is a concept that has existed since the inception of the internet. It is known by many other names, (web based) data extraction, data harvesting, web crawling and many more. A webscraper is a program that's sole purpose is to do exactly those things, target a website (or websites) and crawl through it's HTML elements to extract data that we want to see. It's not unreasonable to see this explanation and think to yourself:
So...like...browsing the web? Through a program? What's so great about that?
Well there are so many great things about it but the main idea behind it is automation! As human beings not only do we experience life, often without a lot of time to browse the web for everything we want or need, but we experience fatigue in repetitive tasks. For example, imagine for a moment you spend 8-12 hours a day working, with minimal time to take care of things in your personal life. You do everything you can but are left with practically no time to browse the web for products you want or maybe even need in order to help your workflow. Luckily for you, you know a little bit of python and are a pro at googling, so enter in your little automated webscraper to save the day.
Stepping back from the example for a moment, there are pros and cons to be had with webscraping that are important to understand before delving into an example.
Pros:
- Saves time and headache by automating any data you want to find on the web.
- Can be completely automated, in that we can set our webscraper up to grab data by the second, minute, hour, day etc..
- Depending on the reason for data collection, this can give you a huge edge over others if for instance you're searching for a product that is not frequently in stock.
Cons:
- Dynamic websites make for a hard time with webscrapers.
- A webscraper is essentially a bot, something that is not exactly liked by many sites you may try to scrape data from.
That being said, I'll be using a static test website created by Webscraper.io, the link to the specific test site can be found here. Feel free to visit the test site and inspect the HTML to see for yourself the elements we'll target for this webscraper. This is the first step to building any webscraper as this is how we will tell it where to grab data from.
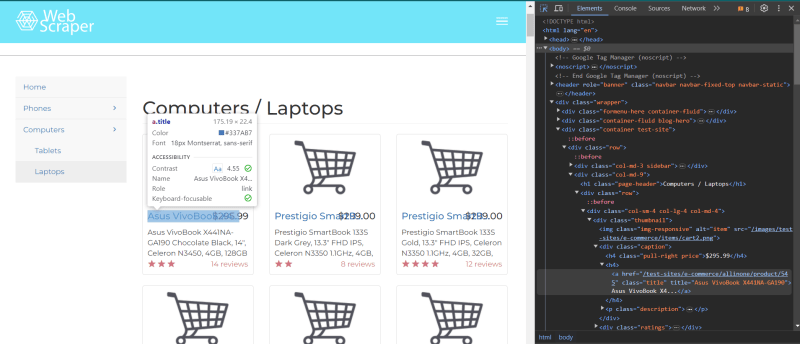
Using our element selector tool, we test the waters to see what the title of the first product looks like in the html, and we see it's an "a" tag with a class of "title". This is a great start to figuring out what pieces of information we want, but it still isn't good enough. We want to zoom out and find the div storing all of the products on the page, not just the specific one we initially targeted.

This is perfect! We see now that the div storing all of the product information on the test page is stored under a class of "col-md-9". This is the div we will want to isolate to break down all the data inside it and get what we're looking for! Looking over to our code editor, I'm creating this webscraper using python as well as 3 different libraries. To start we'll be using the requests library for our HTTP requests and the BeautifulSoup library for the actual scraping of data. For the sake of read time, pseudocode is included to explain what is happening in the code.

Now that we've completed the setup, we can target the div that stores all the product data using BeautifulSoup's find function. Once it's stored, we can use find_all to grab all the instances of title classes, price classes, description classes and ratings classes.

Since we've scraped all the data we're looking for, its time to print it to see what it looks like!


Voila! We now have a printed table in our terminal containing each of those things in a nice legible list. You can do all sorts of things from here, changing the products you scrape to be only of a certain rating, titles containing a certain brand, the possibilities are endless! Although now we have all this data we wanted, the terminal isn't exactly the prettiest place to view all of it. Here is where our third library comes in, Pandas. Pandas is a data analysis library for python that we can use to extrapolate our data into a more legible format.

Lastly, all we need to do is export our data frame that we created with pandas to a csv file for readability.
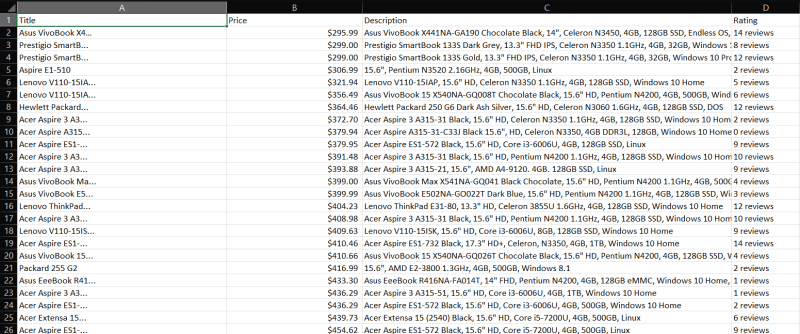
We now have access to a nice spreadsheet of 117 rows with the 4 columns of Title, Price, Description and Ratings, with barely any code! The same process can be applied to almost any static website, but the real challenge comes with dynamic websites. There are other methods to scrape such websites but that'll be covered in an upcoming blog where I'll be using Selenium in tandem with some of the same tech used in this blog.

Top comments (0)