
Photo credit: Dennis Kummer
There are a few things as important in Apache Kafka as topics. It’s something that you’ll encounter immediately when you try to follow any tutorial on how to use Kafka. So let’s see…
What is a topic in Apache Kafka?
Messages in Kafka are organized in topics. A topic is a named logical channel between a producer and consumers of messages. The name is usually used to describe the data a topic contains.
An example of a topic might be a topic containing readings from all the temperature sensors within a building called ‘temperature_readings’ or a topic containing GPS locations of vehicles from the company’s car park called ‘vehicle_location’.
A producer writes messages to the topic and a consumer reads them from the topic. This way we are decoupling them since the producer can write messages to the topic without waiting for the consumer. The consumer can then consume messages at its own pace. This is known as the publish-subscribe pattern.
Kafka Record
Messages are called records in Kafka lingo. Each record consists of a key and a value, where the key is not mandatory.
The key of the record is used for record partitioning, but we’ll get to that soon.
A value of the record will contain the data you want to send to the consumer(s). In the case of our temperature_readings topic, a value might be a JSON object containing e.g. sensor id, temperature value, and timestamp of the reading. In the case of our vehicle_location topic, the value might be a binary object containing e.g. vehicle id, current latitude and longitude and a time when the location was sent.
Retention of records
One thing that separates Kafka from other messaging systems is the fact that the records are not removed from the topic once they are consumed. This allows multiple consumers to consume the same record and it also allows the same consumer to read the records again (and again).
“So when are records removed from the topic then?” you might ask. They are removed after a certain period of time. By default, Kafka will retain records in the topic for 7 days. Retention can be configured per topic.
Partition
A topic will have one or more partitions. Partition is a very simple data structure. It is the append-only sequence of records, totally ordered by the time when they were appended.

Let’s unpack that a bit. If we say that the partition starts on the left-hand side, then new records will always be added to the right of the last record. In the example above a new record would be added after the 4th record. This allows consumers to read the records in the same order as they were produced (in our case, from left to right).
Append-only means that records can not be modified once they are written.
An idea of a structured commit log is not far from an application log. A new line is always appended at the end of the file and once a line is written to the log it cannot be changed.
Once the record is written to a partition it is assigned an offset – a sequential id that shows the position of the record in the partition and uniquely identifies that record within the partition.
When we put it all together, the topic looks something like this:
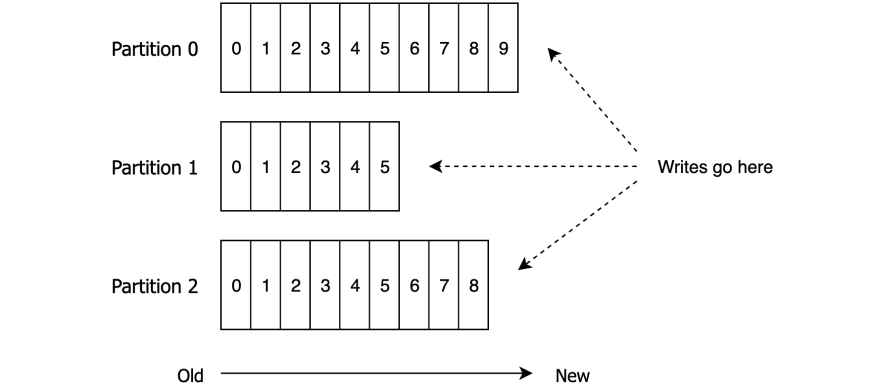
There are a few things to remember here:
- Records are always added to the end of the partition. This means that, within the same partition, records with a lower offset are older
- The offset (and the order of records) only has a meaning within a partition
- Messages sent by a producer to a particular topic partition will be appended in the order they are sent
- A consumer instance sees records in the order they are stored in the partition
- The records with the same key will always end up in the same partition (more on this in the next section)
The link between a record and a partition
As I mentioned in the part about the Kafka record, the key is used for partitioning. By default, Kafka producer relies on the key of the record to decide to which partition to write the record. For two records with the same key, the producer will always choose the same partition.
Why is this important?
Sometimes we need to deliver records to consumers in the same order as they were produced. When a customer purchases e.g. an ebook from your webshop and then cancels that purchase, you want these events to arrive in the order they were created. If you receive the cancellation event before the purchase event, the cancellation would be rejected as invalid (since the purchase doesn’t yet exist in the system) and then the system will register a purchase, delivering the product to the customer (and losing you money).
So to fix this problem and ensure the ordering, you could use a customer id as the key of these Kafka records. This will ensure that all purchase events for a given customer end up in the same partition.

So, records with the same key end up in the same partitions. But note that one partition can contain records with more than one key, so you don’t need to go crazy with number of partitions :).
Above you can see an example of a topic with two partitions. The keys of the records are of type string, while the values of the records are of type integer. In this example, you’ll notice how all records with keys k1 and k3 are written to partition 0, while records with keys k2, k4 and k5 are sent to partition 1.
What happens when the record key is null?
As I mentioned before, it is not mandatory to specify a key when creating a Kafka record. If the key is null a producer will choose a partition in a round-robin fashion. So, if you don’t need ordering of records, you don’t need to put the key in a Kafka record.
Ok, but why do we need partitions?
Partition has several purposes in Kafka.
From Kafka broker’s point of view, partitions allow a single topic to be distributed over multiple servers. That way it is possible to store more data in a topic than what a single server could hold. If you imagine you needed to store 10TB of data in a topic and you have 3 brokers, one option would be to create a topic with one partition and store all 10TB on one broker. Another option would be to create a topic with 3 partitions and spread 10 TB of data over all the brokers.

From the consumer’s point of view, a partition is a unit of parallelism.
How’s that, now?
Here’s an example to explain this: Let’s say that a producer sends 2.000 records every second to the topic vehicle_location we mentioned earlier. Now, let’s say that we have a microservice consuming the data and it’s doing some heavy calculations on each message and can only process 1.000 messages per second.
In this scenario, our consumer will be constantly falling behind and would never be able to catch up with the producer. So, how do we solve this problem?
We could create a topic with 3 partitions. That way we would get around 700 messages per second on each partition. Then we would spin up 3 instances of our consumer microservice, where each instance reads from one partition.
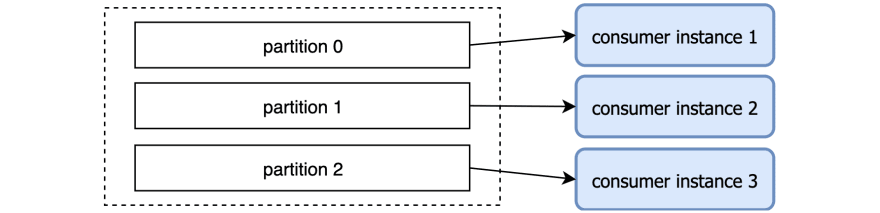
Now each consumer instance is processing 700 messages per seconds and all instances together are easily keeping up with the producer. That’s what we mean when we say that a partition is a unit of parallelism: The more partitions a topic has, the more processing can be done in parallel. How this is achieved is the subject of another post. For now, it’s enough to understand how partitions help.
Topic replication
Kafka is a distributed and fault-tolerant system. One of the ways this is achieved is by replicating data across brokers. When we create a topic one of the things we need to specify is a replication factor. This tells Kafka how many times it should replicate partitions across brokers to avoid data loss in case of outages. Note that the replication factor cannot be larger than the number of brokers, otherwise, you wouldn’t be really distributing the data as much as copying it to another place on the same hard-drive :)
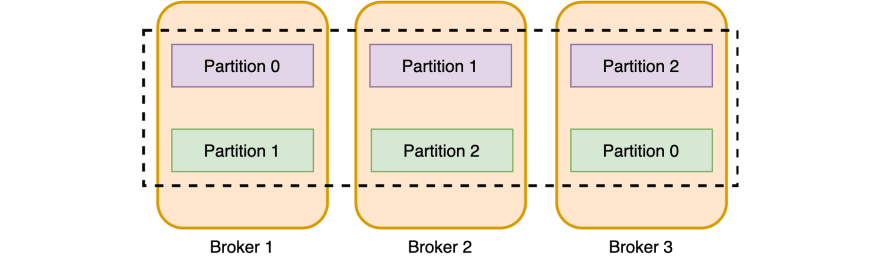
Here’s an example of a topic with three partitions and a replication factor of 2 (meaning that each partition is duplicated). This shows a possible distribution of partitions (in purple) and their replicas (in green) across brokers. Kafka will ensure the same partitions never end up on the same broker. This is needed to allow for server outages, without losing data.
Also, Kafka guarantees that “for a topic with replication factor N, it will tolerate up to N-1 server failures without losing any records committed to the log”. So in our example with a replication factor of 2, we could lose any single broker and we would still have all the partitions available for both writing and reading.
Partition leader and followers
For each partition, there will be one broker that is the leader for that partition. In our case, the broker with the purple partition is the leader for that partition. Other brokers will be followers (green partitions). So, in the case above, broker 1 is the leader for partition 0 and the follower for partition 1.
All writes and reads go towards a partition leader, while followers just copy the data over to be in-sync with the leader. A follower that is in sync with the leader is called an in-sync replica (ISR). If the leader for the partition is offline, one of the in-sync replicas will be selected as the new leader and all the producers and consumers will start talking to the new leader.
And there you have it, the basics of Kafka topics and partitions. Don’t worry if it takes some time to understand these concepts. Feel free to bookmark this post and return later to re-read it, as needed.
Would you like to learn more about Kafka?
I have created a Kafka mini-course that you can get absolutely free. Sign up for it over at Coding Harbour.

Top comments (0)