
Photo credit: @bosco_shots
Or, how to produce and consume Kafka records using Avro serialization in Java.
So far we’ve seen how to produce and consume simple String records using Java and console tools. In this post, I would like to show you how to send and read Avro messages from Java using the kafka-clients library.
If you’re new to Avro, I have written a full post about why you should consider Avro serialization for Kafka messages, so check it out to learn more.
Running a Kafka cluster locally
To test the producers and consumers, let’s run a Kafka cluster locally, consisting of one broker, one zookeeper and a Schema Registry.
To simplify our job, we will run these servers as Docker containers, using docker-compose.
Don’t have docker-compose? Check: how to install docker-compose
I’ve prepared a docker-compose file which you can grab from Coding Harbour’s GitHub:
git clone https://github.com/codingharbour/kafka-docker-compose.git
Once you have the project, navigate to a folder called single-node-avro-kafka and start the Kafka cluster:
docker-compose up -d
The output should look something like this:
$ docker-compose up -d
Starting sn-zookeeper ... done
Starting sn-kafka ... done
Starting sn-schema-registry ... done
Your local Kafka cluster is now ready to be used. By running docker-compose ps , we can see that the Kafka broker is available on port 9092, while the Schema Registry runs on port 8081. Make a note of that, because we’ll need it soon.
$ docker-compose ps
Name Command State Ports
----------------------------------------------------------------------------------------------------
sn-kafka /etc/confluent/docker/run Up 0.0.0.0:9092->9092/tcp
sn-schema-registry /etc/confluent/docker/run Up 0.0.0.0:8081->8081/tcp
sn-zookeeper /etc/confluent/docker/run Up 0.0.0.0:2181->2181/tcp, 2888/tcp, 3888/tcp
Defining the Avro Schema
Let’s create a schema for the messages we’ll be sending through Kafka. We’ll call our message: SimpleMessage, and it will have two fields:
- content – a string field, holding the message we want to send and
- date_time – human-readable date-time showing when the message was sent
Avro schemas are written in a JSON format, so our SimpleMessage schema will look like this:
{
"type": "record",
"name": "SimpleMessage",
"namespace": "com.codingharbour.avro",
"fields": [
{"name": "content", "type":"string", "doc": "Message content"},
{"name": "date_time", "type":"string", "doc": "Datetime when the message was generated"}
]
}
The schema consists of a couple of elements:
- Type – Describes a data type of the entire schema. Type ‘record’ means that the schema describes a complex data type, which includes other fields.
- Name – The name of the schema. In our case “SimpleMessage”
- Namespace – Namespace of the schema that qualifies the name. In our case, the namespace is “com.codingharbour.avro”
- List of fields – One or more fields that are in this complex data type
Each field in a schema is a JSON object with multiple attributes:
- name – name of the field
- type – data type of the field. Avro supports primitive types like int, string, bytes etc, and complex types like record, enum, etc
- doc – Documentation for the given field
- default – the default value for the field, used by the consumer to populate the value when the field is missing from the message.
For more info on Avro data types and schema check the Avro spec.
Schema Registry
As I’ve mentioned in the previous post, every Avro message contains the schema used to serialize it. But sending thousands or millions of messages per second with the same schema is a huge waste of bandwidth and storage space. That’s where the Schema Registry, KafkaAvroSerializer and KafkaAvroDeserializer come into play.
Instead of writing the schema to the message, KafkaAvroSerializer will write the schema to the Schema Registry and it will only write the schema id to the message. Then, when the Kafka record reaches the consumer, the consumer will use KafkaAvroDeserializer to fetch the schema from the Schema Registry based on the schema id from the message. Once the schema is fetched, the KafkaAvroDeserializer can deserialize the message.
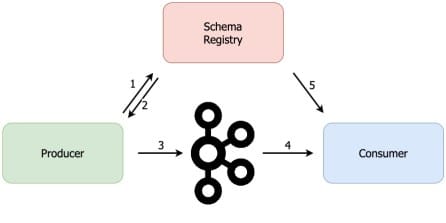
This is why, when using KafkaAvro(De)Serializer in a producer or a consumer, we need to provide the URL of the schema registry. Remember that our Schema Registry runs on port 8081.
Here’s a snippet from our producer:
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, KafkaAvroSerializer.class);
properties.put(KafkaAvroSerializerConfig.SCHEMA_REGISTRY_URL_CONFIG, "http://localhost:8081");
If we don’t specify the URL, the (de)serializer will complain when we try to send/read a message.
Ok, the next thing is to see how an Avro schema gets translated into a Java object.
Avro record in Java
Note : do not confuse an Avro record with a Kafka record. Each Avro schema describes one or more Avro records. An Avro record is a complex data type in Avro, consisting of other fields, with their own data types (primitive or complex). Kafka record, on the other hand, consists of a key and a value and each of them can have separate serialization. Meaning, e.g. that Kafka key may be one Avro record, while a Kafka value is another Avro record (if we choose to use Avro serialization for both the key and the value).
When it comes to representing an Avro record in Java, Avro library provides two interfaces: GenericRecord or SpecificRecord. Let’s see what the difference is and when to use which.
An instance of a GenericRecord allows us to access the schema fields either by index or by name, as seen below:
GenericRecord record = ... ; //obtain a generic record
//accessing the field by name
record.put("date_time", "2020-01-01 12:45:00")
String dateTime = (String) record.get("date_time");
//accessing the field by index
record.put(0, "this is message number 1");
String content = (String) record.get(0);
Using a GenericRecord is ideal when a schema is not known in advance or when you want to handle multiple schemas with the same code (e.g. in a Kafka Connector). The drawback of GenericRecord is the lack of type-safety. GenericRecord’s put and get methods work with Object.
SpecificRecord is an interface from the Avro library that allows us to use an Avro record as a POJO. This is done by generating a Java class (or classes) from the schema, by using avro-maven-plugin. The generated class will implement the SpecificRecord interface, as seen below.
/* Class generated by avro-maven-plugin*/
public class SimpleMessage extends org.apache.avro.specific.SpecificRecordBase
implements org.apache.avro.specific.SpecificRecord {
//content removed for brevity
}
//using the SpecificRecord by using the actual implementation
SimpleMessage simpleMessage = new SimpleMessage();
simpleMessage.setContent("Hello world");
The drawback of SpecificRecord is that you need to generate a class for each schema you plan to use, in advance. Which again means you need the Avro schema in advance, to be able to generate the Java class.
Producing Avro messages using GenericRecord
First, we prepare the properties the producer needs. We specify our brokers, serializers for the key and the value, as well as the URL for the Schema Registry. Then we instantiate the Kafka producer:
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, KafkaAvroSerializer.class);
properties.put(KafkaAvroSerializerConfig.SCHEMA_REGISTRY_URL_CONFIG, "http://localhost:8081");
Producer<String, GenericRecord> producer = new KafkaProducer<>(properties);
As you see, we are using String serializer for the keys and Avro for values. Notice that the producer expects _GenericRecord_s as the value of the Kafka record.
The next step is to create an instance of an Avro record based on our schema:
//avro schema
String simpleMessageSchema =
"{" +
" \"type\": \"record\"," +
" \"name\": \"SimpleMessage\"," +
" \"namespace\": \"com.codingharbour.avro\"," +
" \"fields\": [" +
" {\"name\": \"content\", \"type\": \"string\", \"doc\": \"Message content\"}," +
" {\"name\": \"date_time\", \"type\": \"string\", \"doc\": \"Datetime when the message\"}" +
" ]" +
"}";
//parse the schema
Schema.Parser parser = new Schema.Parser();
Schema schema = parser.parse(simpleMessageSchema);
//prepare the avro record
GenericRecord avroRecord = new GenericData.Record(schema);
avroRecord.put("content", "Hello world");
avroRecord.put("date_time", Instant.now().toString());
Here, we specified the schema directly in the code. By parsing the schema we get a Schema object, which we use to instantiate a new GenericRecord. Finally, we set the record’s fields by name, using the put method.
The last thing to do is create a Kafka record with null key and Avro record in the value and write it to a topic called avro-topic:
//prepare the kafka record
ProducerRecord<String, GenericRecord> record = new ProducerRecord<>("avro-topic", null, avroRecord);
producer.send(record);
//ensures record is sent before closing the producer
producer.flush();
producer.close();
Producing Avro messages using SpecificRecord
Another way to produce the same record as above is to use the SpecificRecord interface. We will generate a Java cclass from the Avro schema using the avro-maven-plugin. We’ll add the plugin to our pom.xml:
<plugin>
<groupId>org.apache.avro</groupId>
<artifactId>avro-maven-plugin</artifactId>
<version>1.9.2</version>
<executions>
<execution>
<phase>generate-sources</phase>
<goals>
<goal>schema</goal>
</goals>
<configuration>
<sourceDirectory>${project.basedir}/src/main/avro/</sourceDirectory>
<outputDirectory>${project.basedir}/target/generated-sources/avro/</outputDirectory>
<stringType>String</stringType>
</configuration>
</execution>
</executions>
</plugin>
Avro plugin is configured above to generate classes based on schemas in the src/main/avro folder and to store the classes in the target/generated-sources/avro/.
If you check the src/main/avro folder, you will see the Avro schema for our SimpleMessage. It’s the same schema we used in the GenericRecord example above. When you execute mvn compile, the SimpleMessage class will be generated in the target folder.

Then we’ll define properties for the Kafka producer, same as in the GenericRecord example:
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, KafkaAvroSerializer.class);
properties.put("schema.registry.url", "http://localhost:8081");
Producer<String, SpecificRecord> producer = new KafkaProducer<>(properties);
The only difference compared to the GenericRecord example is the type for the value of the Kafka record, which is now SpecificRecord.
Next, we create the instance of the SimpleMessage:
//create the specific record
SimpleMessage simpleMessage = new SimpleMessage();
simpleMessage.setContent("Hello world");
simpleMessage.setDateTime(Instant.now().toString());
And lastly, we create a Kafka record and write it to the “avro-topic” topic:
ProducerRecord<String, SpecificRecord> record = new ProducerRecord<>("avro-topic", null, simpleMessage);
producer.send(record);
//ensures record is sent before closing the producer
producer.flush();
producer.close();
Note that both producers above have written to a topic called ‘avro-topic’. So we now have two records to consume. Let’s see how we can create the consumers.
Consuming Avro messages using GenericRecord
The consumer that uses GenericRecord, does not need a schema nor a Java class generated from the schema. All the data will be obtained by the deserializer from the schema registry.
First, we’ll create properties for the consumer and istantiate it:
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "generic-record-consumer-group");
properties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, KafkaAvroDeserializer.class);
properties.put(KafkaAvroDeserializerConfig.SCHEMA_REGISTRY_URL_CONFIG, "http://localhost:8081");
KafkaConsumer<String, GenericRecord> consumer = new KafkaConsumer<>(properties);
Then we’ll subscribe our consumer to the ‘avro-topic’ topic and start listening for records:
consumer.subscribe(Collections.singleton("avro-topic"));
//poll the record from the topic
while (true) {
ConsumerRecords<String, GenericRecord> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, GenericRecord> record : records) {
System.out.println("Message content: " + record.value().get("content"));
System.out.println("Message time: " + record.value().get("date_time"));
}
consumer.commitAsync();
}
Here we get the field values by name, using the Object get(String key) method of GenericRecord.
Consuming Avro messages using SpecificRecord
Last thing to show is how to consume Avro kafka record, which is automatically casted into proper Java class, generated from Avro schema.
As before, we’ll start with preparing properties for the consumer and instantiating it:
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "specific-record-consumer-group");
properties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, KafkaAvroDeserializer.class);
properties.put(KafkaAvroDeserializerConfig.SCHEMA_REGISTRY_URL_CONFIG, "http://localhost:8081");
properties.put(KafkaAvroDeserializerConfig.SPECIFIC_AVRO_READER_CONFIG, true); //ensures records are properly converted
KafkaConsumer<String, SimpleMessage> consumer = new KafkaConsumer<>(properties);
Everything is the same as with the previous consumer, except the third line from the bottom. Let’s look at it again:
properties.put(KafkaAvroDeserializerConfig.SPECIFIC_AVRO_READER_CONFIG, true);
This line is necessary if you want your Avro records to be properly converted into the excepted Java class (in our case, this is SimpleMessage).
Now, all we have to do is subscribe our consumer to the topic and start consuming:
consumer.subscribe(Collections.singleton("avro-topic"));
//poll the record from the topic
while (true) {
ConsumerRecords<String, SimpleMessage> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, SimpleMessage> record : records) {
System.out.println("Message content: " + record.value().getContent()); //1
System.out.println("Message time: " + record.value().getDateTime()); //2
}
consumer.commitAsync();
}
You see above lines marked 1 and 2 how the fields of SimpleMessage are accessed using proper getter methods.
There you have it, two ways to produce and two ways to consume Kafka Avro records. Hope this was helpful.
As always, the code from this blog post is available on CodingHarbour’s github repo
Would you like to learn more about Kafka?
I have created a Kafka mini-course that you can get absolutely free. Sign up for it over at Coding Harbour.

Top comments (1)
Hi @Dejan, great article, thanks for sharing.
I was looking for especially the following config but it's easy to follow for the ones who want to understand the whole setup.