Avro is an open-source binary serialization format. But why use it with Kafka? Why not send JSON or XML messages? What benefits does it give us? This is what we’ll be exploring today.
Serialization
It’s important to understand that records in a topic are just arrays of bytes. Kafka broker doesn’t care about the type of data we’re sending. To make those byte arrays useful in our applications, producers and consumers must know how to interpret them. Are we sending CSV data or JSON or XML? Producers and consumers use (de)serialization to transform data to byte arrays and back. Yet, that’s only the beginning.
Schema
Whenever we use data as an integration mechanism, the schema of the data becomes very important, because it becomes the contract between producers and consumers. The teams behind producers and consumers need to agree on the following:
- Which fields are in a record
- Which fields are optional and which are mandatory
- Where and how should this be documented
- Which default values should a consumer use for the fields that are missing from the record
- How should changes to the schema be handled
Data format
Now, you could use JSON with a JSON schema or use XML with an XSD schema to describe the message format. But there’s one downside with these: messages in these formats often use more space to convey the same information due to the nature of JSON and XML.
So is there a better way?
Yes. You could use Apache Avro. Avro is a data serialization format that is developed under the Apache umbrella and is suggested to be used for Kafka messages by the creators of Apache Kafka themselves. Why?
By serializing your data in Avro format, you get the following benefits:
- Avro relies on a schema. This means every field is properly described and documented
- Avro data format is a compact binary format, so it takes less space both on a wire and on a disk
- It has support for a variety of programming languages
- in Avro, every message contains the schema used to serialize it. That means that when you’re reading messages, you always know how to deserialize them, even if the schema has changed
Yet, there’s one thing that makes Avro not ideal for usage in Kafka, at least not out-of-the-box, because…
Every Avro message contains the schema used to serialize the message
Think about this for a moment: if you plan on sending millions of messages a day to Kafka, it’s a terrible waste of bandwidth and storage space to send the same schema information over and over again.
So, the way to overcome this is to…
Separate the schema from the message
That’s where a Schema Registry comes into play. Schema Registry is developed by Confluent, a company behind Apache Kafka, and it provides a RESTful interface for storing and receiving Avro schemas.
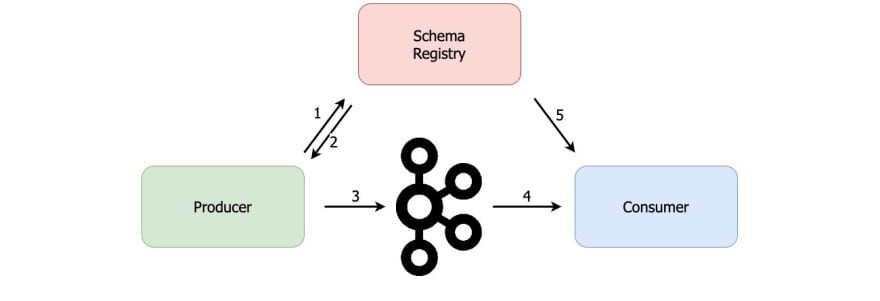
Instead of sending the schema inside a Kafka record, a producer starts by checking whether schema already exists in the Schema Registry. If not, it will write the schema there (step 1 below). Then the producer will obtain the id of the schema (step 2) and send that id inside the record (step 3), saving a lot of space this way. The consumer will read the message (step 4) and then contact the Schema Registry with the schema id from the record to get the full schema (step 5) and cache it locally.
Ok, that seems nice. But that’s not the only place where Schema Registry helps. Let’s see what happens when you want to…
Evolve the schema
Imagine yourself in a situation where, 2 years after releasing the producer application, you decide to change the format of the message in a way that, in your opinion, doesn’t break the compatibility and thus should not affect the consumers. Now you have 2 options:
- you can either be a nice person, find all the consumers, check whether the suggested changes will affect them and if so, ask them to change
- or you can do the change and wait for the mob with torches, shovels, and rakes to come your way
Assuming you chose to avoid the option that would put your picture on every train station with a monetary reward under it, what is the probable outcome of the option number one?
Those who worked in a corporate environment know the answer: a lot of planning, budgeting, negotiating and sometimes even postponing because there are more pressing issues. Getting 10s or 100s of consumers to perform the upgrade before you can continue with the changes in the producer is a sure way to an asylum.
Apache Avro and Schema Registry are coming to the rescue once again. Schema Registry allows us to enforce the rules for validating a schema compatibility when the schema is modified. If a new message breaks the schema compatibility, a producer will reject to write the message.
This way your consumers are protected from e.g. someone suddenly changing the data type of the field from a long to a string or removing the mandatory field.
At the same time, it gives you clear guidelines about which changes to the schema are allowed. So no longer weeks or months of coordinating the change just to remove an optional field in a message.
Would you like to learn more about Kafka?
I have created a Kafka mini-course that you can get absolutely free. Sign up for it over at Coding Harbour.

Top comments (2)
Simple explanation. Easy to understand! Thanks Dejan! Keep blogging.
Well written article. Thanks!