
Julia est un langage de programmation de haut niveau, performant et dynamique pour le calcul scientifique, avec une syntaxe familière aux utilisateurs d’autres environnements de développement similaires (Matlab, R, Scilab, Python, etc…).
Il fournit un compilateur sophistiqué, un système de types dynamiques, une exécution parallèle distribuée, des appels directs de fonctions C, Fortran et Python. Ce langage est en développement au MIT depuis 2009, et la première version publique date de 2012.

Le langage Julia peut maintenant s’intégrer avec Kubernetes via l’utilisation d’une librairie cliente Kuber.jl :
Je commence par la création d’un Scale Set pour cette expérience d’instances avec notamment la nouvelle gamme Edsv4 dans Azure :
- New Azure Virtual Machines for general purpose and memory intensive workloads now in preview | Azure updates | Microsoft Azure
- Edv4 and Edsv4-series - Azure Virtual Machines
Les séries Edv4 et Edsv4 fonctionnent sur les processeurs Intel® Xeon® Platinum 8272CL (Cascade Lake) dans une configuration hyper-threading.
Elles sont idéales pour des applications gourmandes en mémoire et disposent jusqu’à 504 GiB de RAM, de la technologie Intel® Turbo Boost 2.0, de la technologie Intel® Hyper-Threading et de la technologie Intel® Advanced Vector Extensions 512 (Intel® AVX-512). Elles prennent également en charge la technologie Intel® Deep Learning Boost. Ces nouvelles tailles de VM auront un stockage local 50% plus important, ainsi que de meilleures IOPS de disque local pour la lecture et l’écriture par rapport aux anciennes tailles Ev3/Esv3 avec les VM Gen2.

Utilisation de Terraform pour la création de ce Scale Set avec des Spot Instances via ce fichier HCL :
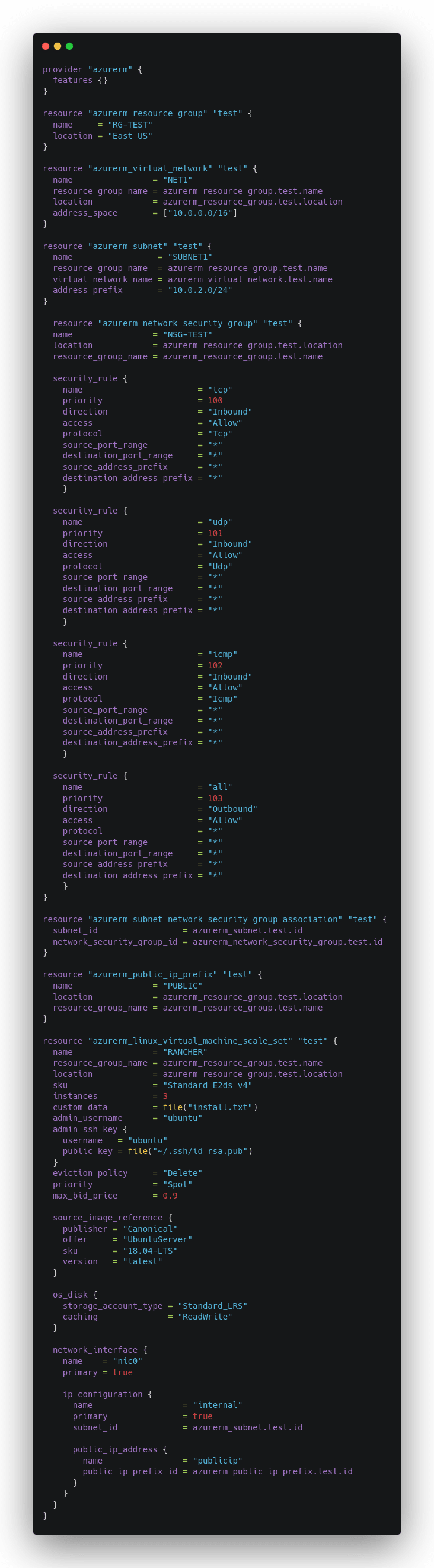
avec ce fichier d’installation de Docker via cloud-init :

à convertir en Base64 :
J’initialise :

puis simulation :

et lancement :

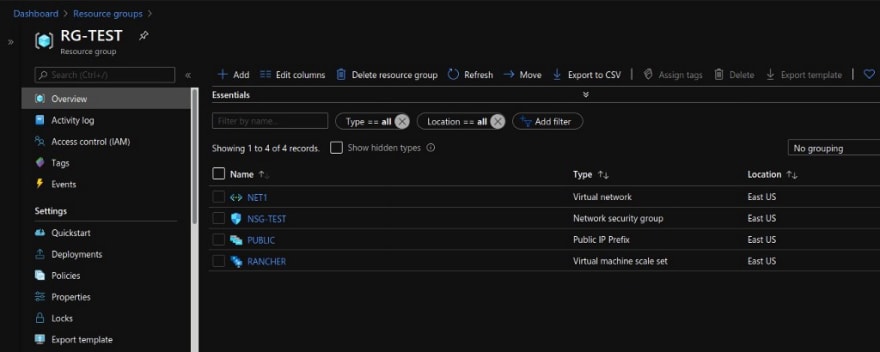
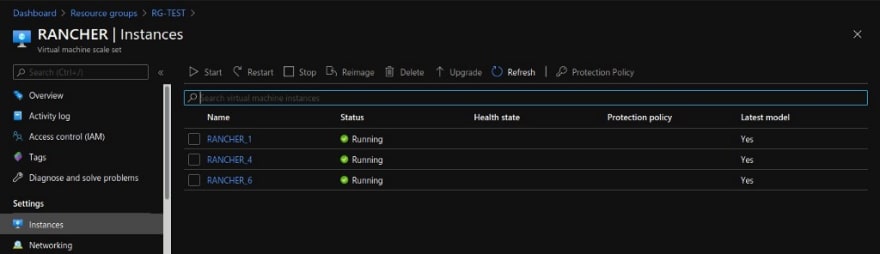
Le Scale Set est actif dans Azure :
J’utilise la dernière version de RKE pour créer mon cluster Kubernetes avec ces Spot Instances dans Azure :

J’utilise ce fichier YAML pour initialiser ce cluster :


Le cluster Kubernetes est actif :



Je peux localement récupérer la dernière version du langage Julia :

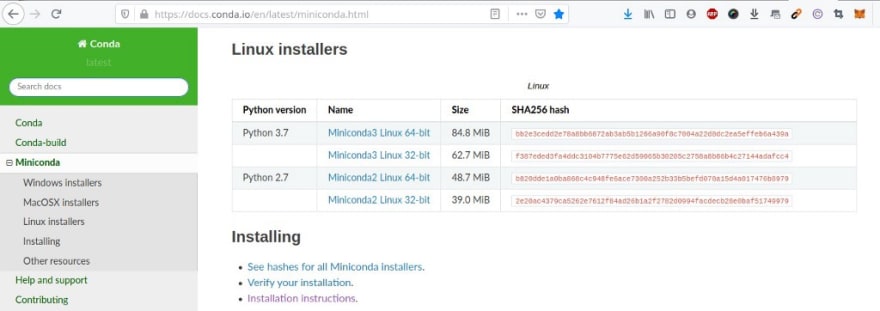
ainsi que Miniconda :
Miniconda - Conda documentation
Après installation de Miniconda, récupération de Jupyter Lab :
J’utilise Julia pour récupérer le noyau pour le futur notebook Jupyter via iJulia :

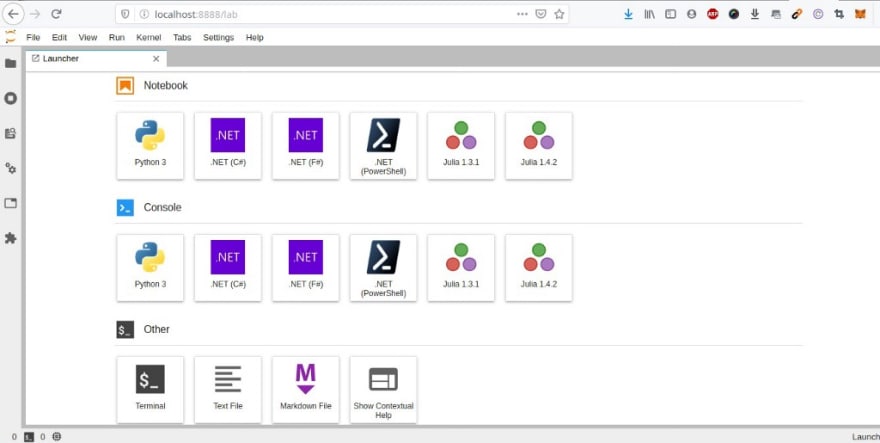
Lancement d’un notebook Jupyter avec la présence de la dernière version du langage Julia :

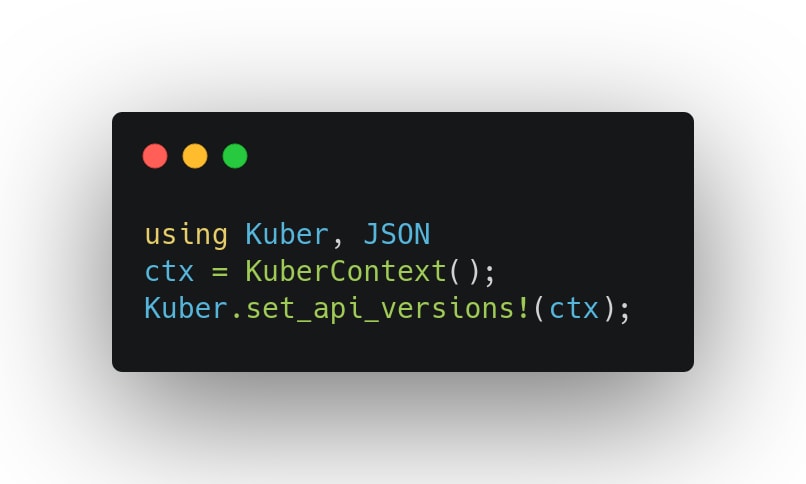
La librairie Kuber.jl a été installée et j’active le proxy localement avec le client Kubectl :

et test d’une mise à l’échelle horizontale avec la langage Julia dans le cluster Kubernetes :
Création d’un Replica Set avec de Workers avec Julia :
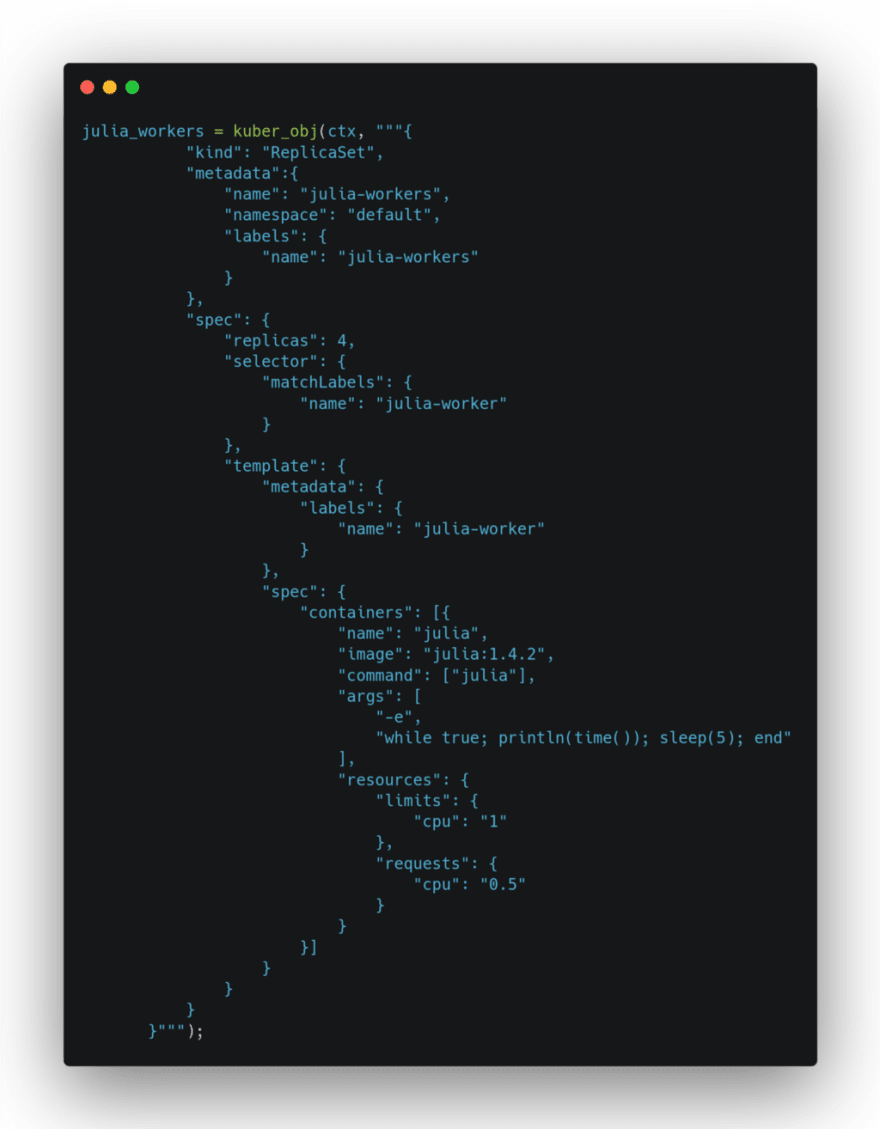

Les workers sont actifs :

Je modifie le nombre de Workers :

et ils augmentent en nombre :

J’en réduis alors le nombre :


Je peux enfin les supprimer :

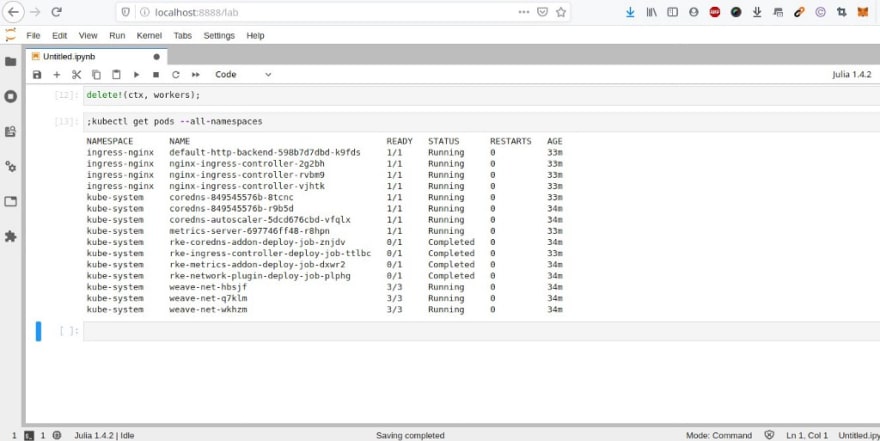
Je peux aussi effectuer une mise à l’échelle verticale :


en créant d’autres workers :
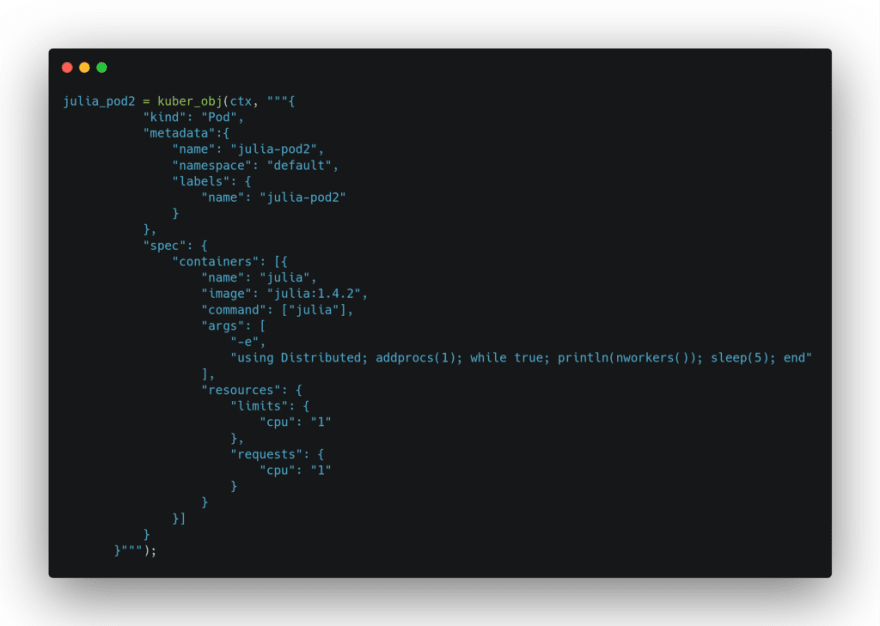

et en vérifiant leurs activités respectives :


Je peux comme précedemment supprimer ces workers :
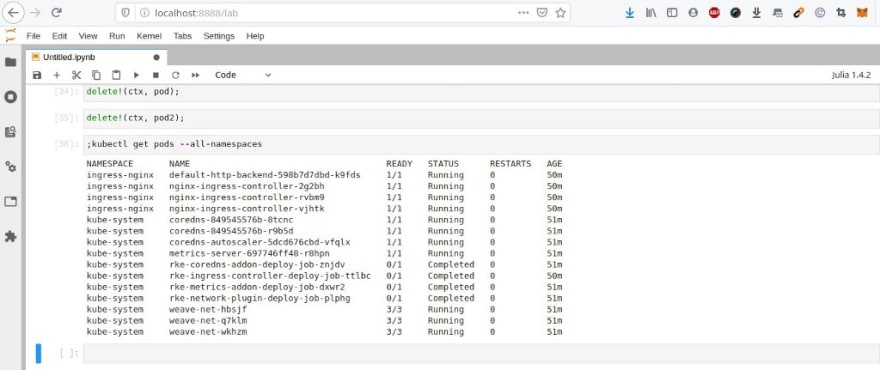
Kuber.jl peut être utilisé pour lancer classiquement des workloads dans le cluster Kubernetes : déploiement du sempiternel démonstrateur FC …
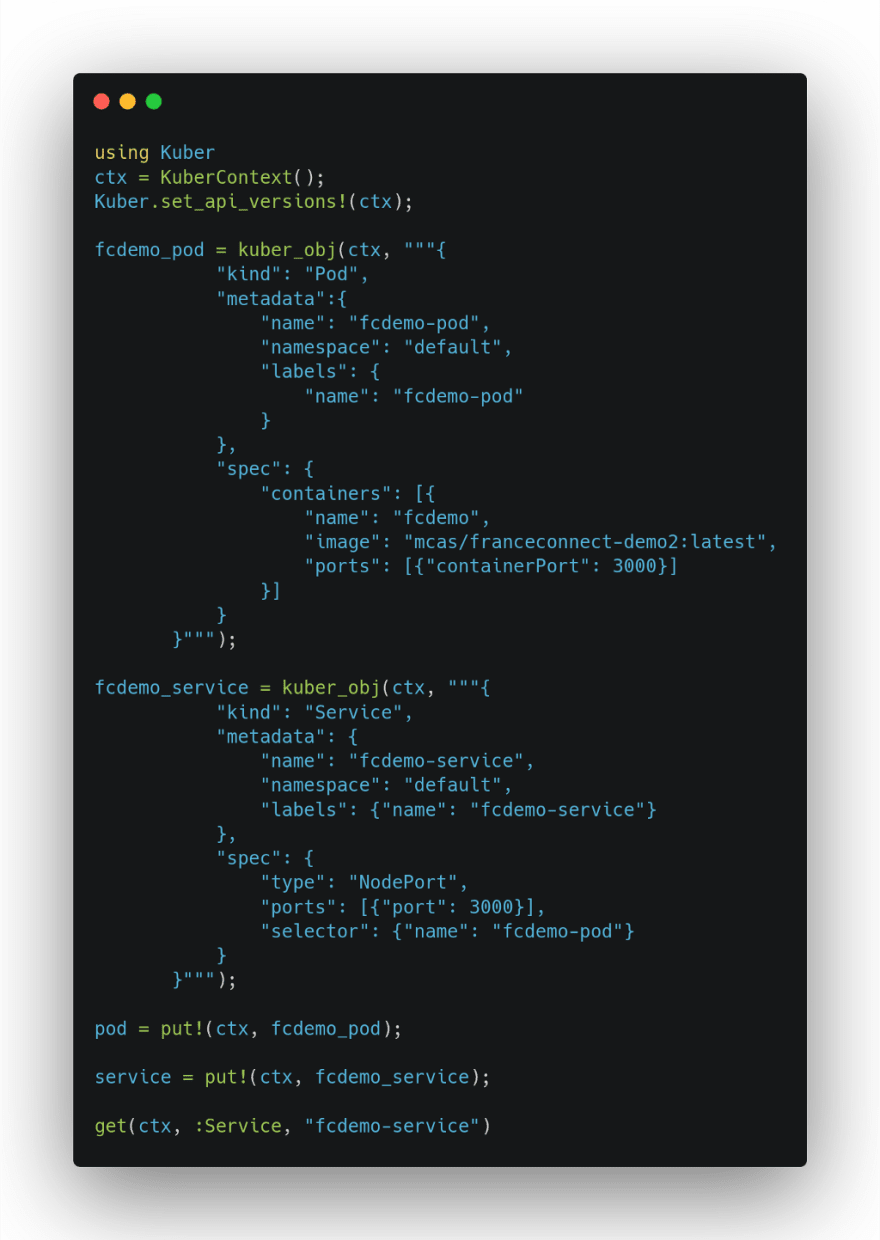

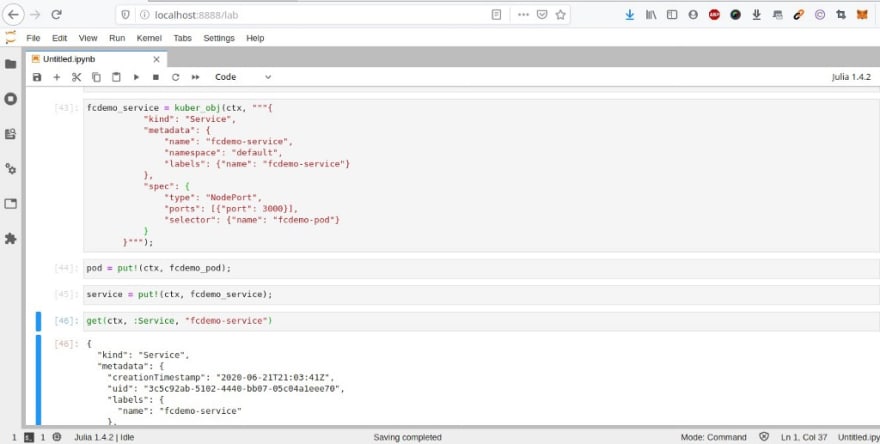
qui est actif via ce port TCP,

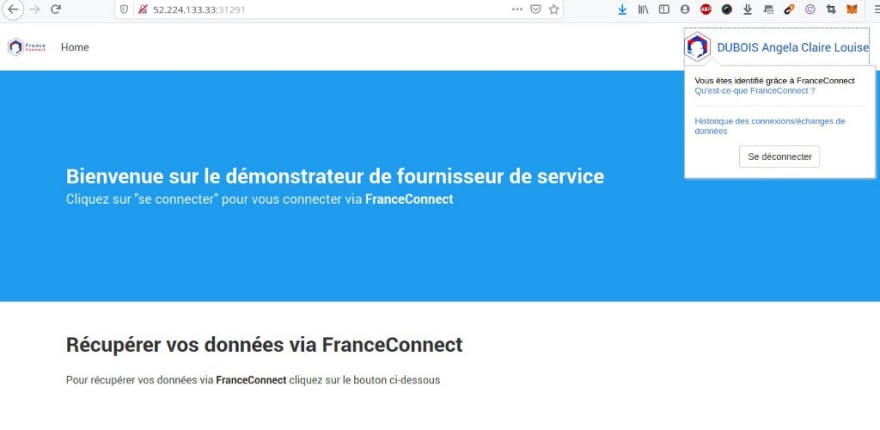
et via chacune des IP publiques des instances Spot :



Récapitulatif du notebook Jupyter ici :
Si l’on ne souhaite pas utiliser Kubernetes, on peut alors utiuliser ces Spot instances en mode distribuée comme dans cet exemple pour tester des équations différentielles stochastiques via DifferentialEquations.jl et ClusterManagers.jl :
Un langage à suivre pusqu’il appartient au Top 10 des langages les plus appréciés des développeurs …
Les 10 langages de programmation les plus aimés des développeurs
Pour aller plus loin :
À suivre !


Oldest comments (0)