
Web scraping is one of the popular ways to gather data from online. If the data that is publicly available does not provide an API for data access, web scraping could be used to gather and analyze the data. In this article, let’s learn the basics by performing web scraping on a sample website.
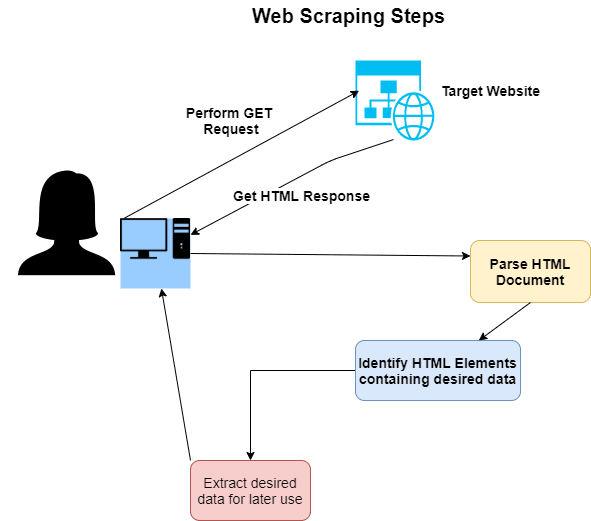
Steps involved in web scraping
- Identify the target website from which information is needed
- Send a GET request to the website
- Receive HTML page as response from the website
- Parse the HTML document to identify HTML elements containing desired data
- Extract the HTML elements containing data
- Cleanse HTML elements to only contain desired text
- Extract desired text and store it for later use
Libraries used for web scraping
Below libraries are used for sample web scraping. Install them in Python project’s virtual environment.
# used to perform GET request
pip install requests
# used to parse HTML
pip install lxml
# used to process html content and get the desired data
pip install beautifulsoup4
Sample scraping
We are going to use Quotes to Scrape website to try our scraping. Our task is to get quotes and authors from the site, and print them in a tuple format.
import requests
from bs4 import BeautifulSoup
# URL for web scraping
url = "http://quotes.toscrape.com/"
# Perform GET request
response = requests.get(url)
# Parse HTML from the response
soup = BeautifulSoup(response.text, 'lxml')
#Extract quotes and quthors html elements
quotes_html = soup.find_all('span', class_="text")
authors_html = soup.find_all('small', class_="author")
#Extract quotes into a list
quotes = list()
for quote in quotes_html:
quotes.append(quote.text)
#Extract authors into a list
authors = list()
for author in authors_html:
authors.append(author.text)
# Make a quote / author tuple for printing
for t in zip(quotes, authors):
print(t)
Final thoughts
Web scraping is one of the fundamentals skills to learn. But one needs to be responsible and abide by the legal terms before starting to use any website for web scraping on a regular basis.

Top comments (4)
Nice guide!, I wonder why everyone uses
quotes.toscrape.com, good to remember about the legal stuff.Feel free to try Faster Than Requests with multi-thread URL-to-SQLite builtin web scraper. :)
Concise and nice informative graphic! 🙌 Quick note: I think one important aspect of web scraping that isn't always mentioned is that you need to first inspect the site you want to scrape.
IMO, the basic web scraping process goes like this:
If anyone wants a longer article on the topic that explains this process and goes into detail while scraping a job board step-by-step, check out my article on Real Python: Beautiful Soup: Build a Web Scraper with Python. Hope this helps someone as a next step if they are interested in this topic : )
Great guide
Thanks!