TLDR; MongoDB Atlas M20-M40 on Azure, GCP and AWS perform pretty similarly, with slightly varying levels of performance (shorter durations) and stability (outliers, variability) across the different cluster/storage sizes:
- M20: AWS > Azure > GCP (sometimes Azure and AWS have higher variability)
- M30: AWS > Azure > GCP (higher variability for GCP)
- M40: AWS > Azure ~> GCP (higher variability for GCP and AWS).
Introduction
The intention of this post is to compare the real-life performance of MongoDB M20-M40 running on Azure, GCP and AWS. Read further if you want to get the condensed results of otherwise a multi-day/week exercise1.
The trigger for the load tests were survarious disk-related performance issues on Azure and repeated statements that MongoDB on AWS and GCP is running much better.
Important Notes:
- This post is discussing only small dedicated instances - M20-M40 with 128 and 256 GB storage only (no need for/experience with bigger ones yet)
- The Reader should only pay attention to the relative aspect of the results, i.e. how different clouds compare to each other, or different instance/storage sizes improve the performance. The absolute request durations in milliseconds etc. are to be ignored, as they are only valid for the specific custom code under test.
- This is not a "scientific" or properly done benchmark (I am an amateur performance/load tester). If you see the approach is wrong or/and can be improved - please let me know in the comments what I can do better (appreciated).
- The architecture details of the software under test is out of scope for this article (I may or may not write another one on that). Same for the load test automation tooling, which is basically implemented using Azure DevOps Pipelines and a substantial number of bash scripts.
- Even though many load tests with different requests per second were performed, only the result of a subset of the tests - 50 requests per second - will be used in this article, as these are enough to illustrate the differences in performance of MongoDB Atlas on Azure/GCP/AWS.
Setup
The software under test is a set of 5 microservices responsible for synchronously2 processing a business operation/transaction 3. The overall interaction between the services looks like this (anonymized):

Note that all database operations are single-document ones where the document size is less than 1 KB, and fall into 3 categories:
1) find a single document by UUID id (primary key)
2) insert a single document
3) replace a single document
The load test infrastructure involves the following tools:
- Azure DevOps Pipelines - for running bash scripts in sequence, responsible for both setup, running the load tests and tear down of the load test environment (both Azure and GCP)
- NBomber - a load test client, generating in this case 50 requests per second using InjectPerSec(rate = 50, during = seconds 600) Load Simulation
- "Client" Kubernetes cluster (AKS, GKE or EKS) with just 1 node (4 vCPUs, 8Gb RAM) for hosting the Azure DevOps self-hosted pool with 1 agent running NBomber
- "Server" Kubernetes cluster (AKS, GKE or EKS) with 2 nodes (2 vCPUs, 16 GB RAM) for running the microservices (3/5 microservices configured with 2 replicas, 2/5 with 1 replica only). Traefik is running as well in the "server" cluster to act as an (HTTPs) API Gateway.
- Both K8s clusters are in the same region, Vnet/VPC Network, different subnets, however the client clusters uses HTTPs with the public DNS hostname of the server for making the calls (so certain traversal of the network infrastructure of the cloud provider takes place, however we are speaking about single-digit ms here).
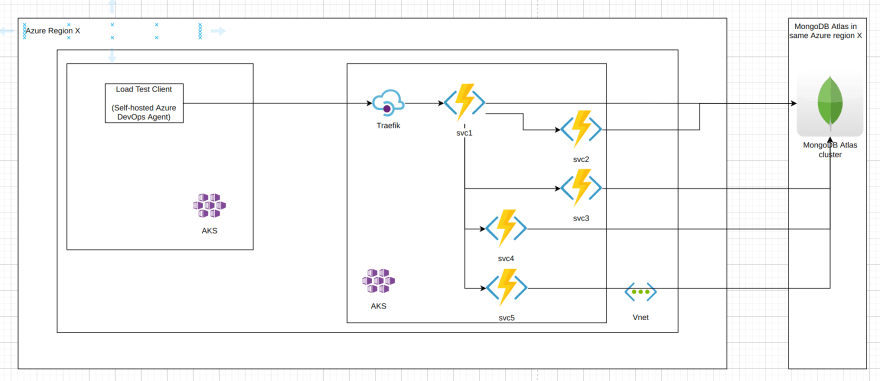
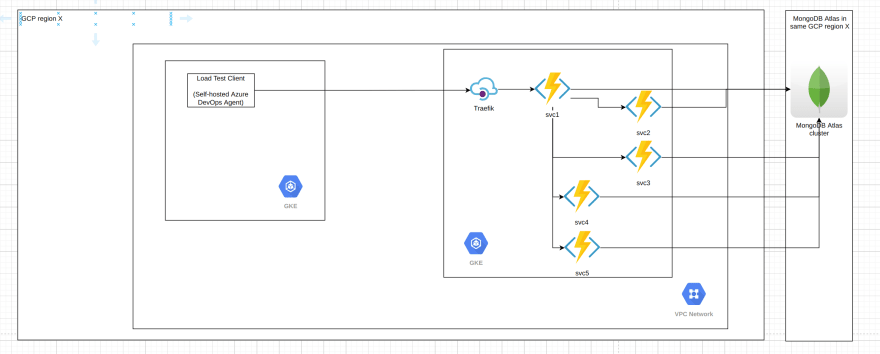
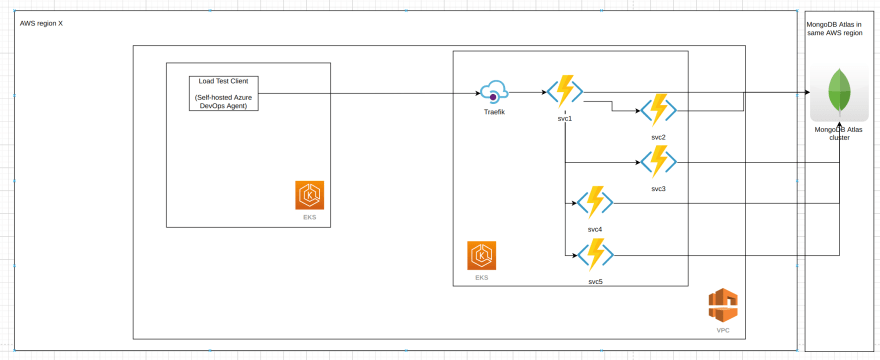
The MongoDB instances used are summarized in the following table:
TABLE MongoDB Instances, including IOPS and $$$
| Cloud | Instance Type | Storage Size (GB) | vCPUs | RAM | IOPS | $$$/h | $$$/month |
|---|---|---|---|---|---|---|---|
| Azure | M20 | 128 | 24 | 4 | 500 | 0.34 | 245 |
| GCP | M20 | 128 | 1 | 3.75 | 76805 | 0.33 | 238 |
| AWS | M20 | 128 | 24 | 4 | 2000 | 0.30 | 238 |
| Azure | M20 | 256 | 24 | 4 | 1100 | 0.45 | 324 |
| GCP | M20 | 256 | 1 | 3.75 | 150005 | 0.45 | 324 |
| AWS | M20 | 256 | 24 | 4 | 2000 | 0.38 | 274 |
| Azure | M30 | 128 | 2 | 8 | 500 | 0.80 | 576 |
| GCP | M30 | 128 | 2 | 7.5 | 76805 | 0.60 | 432 |
| AWS | M30 | 128 | 2 | 8 | 30006 | 0.67 | 482 |
| Azure | M30 | 256 | 2 | 8 | 1100 | 0.91 | 655 |
| GCP | M30 | 256 | 2 | 7.5 | 150005 | 0.72 | 518 |
| AWS | M30 | 256 | 2 | 8 | 30006 | 0.75 | 540 |
| Azure | M40 | 128 | 4 | 16 | 500 | 1.46 | 1051 |
| GCP | M40 | 128 | 4 | 15 | 76805 | 1.06 | 763 |
| AWS | M40 | 128 | 4 | 16 | 30006 | 1.23 | 886 |
Worth noting:
- Azure M20 has 2 CPUs vs 1 vCPU for GCP M20, however in case of Azure the vCPU are burstable, whereas in GCP the single vCPU can be utilized to 100% all the time.
- There is a huge difference in IOPS (on paper) with GCP offering 14-30x more IOPS than Azure for the same storage size!
- With bigger instance sizes Azure becomes noticeably more expensive.
The following sections will present the load testing results from different perspectives.
Azure vs GCP vs AWS Performance M20 with 128Gb disk
50 rps, 5 minutes duration, 3 executions

Interpretation:
- Azure M20 is clearly faster than GCP M20, and when it comes to mean durations at the same level as AWS M20.
- AWS M20 has very high 99 percentile and max durations though (=> a lot variability)
50 rps, 1 hour duration, 3 executions

Interpretation:
- AWS is faster than Azure M20 which is faster than GCP when it comes to average durations,
- AWS has better 99th percentiles as well
- Maximal durations for Azure are worse than GCP and AWS.
Azure vs GCP vs AWS Performance M20 with 256Gb disk
50 rps, 5 minutes duration, 3 executions
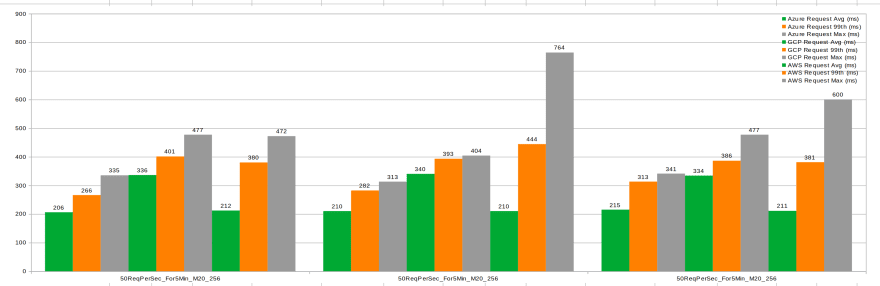
Interpretation:
- Azure and AWS are roughly at the same level, faster than GCP
- AWS shows max duration outliers in 2 out of the 3 executions
1 hour duration, 3 executions
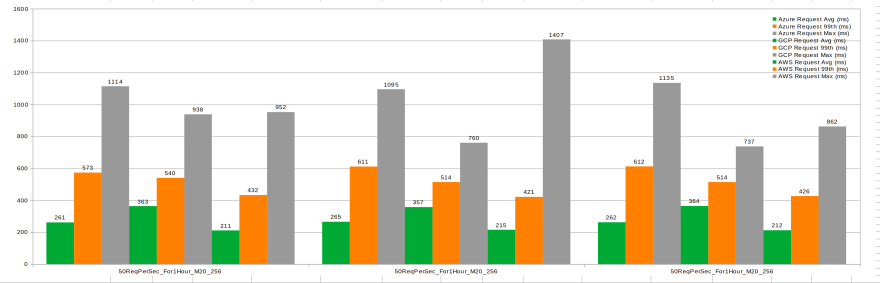
Interpretation:
- AWS M20 is faster than Azure which is faster than GCP when it comes to average durations and 99th percentile
- All 3 have a relatively high max request duration
Azure vs GCP vs AWS Performance M30 with 128Gb disk
50 rps, 5 minutes duration, 3 executions

Interpretation:
- AWS M30 is significantly faster than Azure M30, which is faster than GCP M30
- For all 3 the maximal durations are more consistent (less variability) compared to M20 (especially for AWS)
50 rps, 1 hour duration, 3 executions
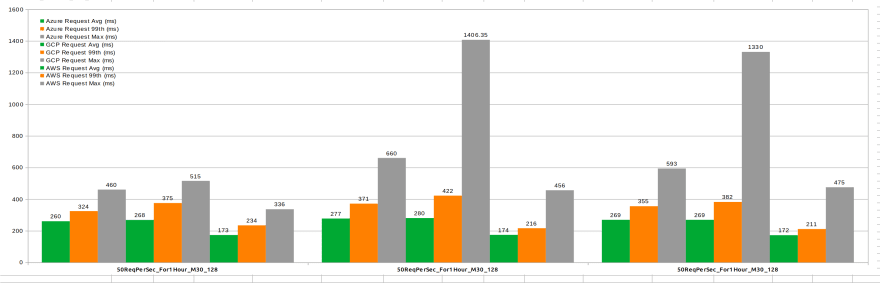
Interpretation:
- AWS is faster than Azure & GCP
- Azure M30 is at the same level as GCP when it comes to average durations, 99th percentiles are almost equal, but the maximal durations of GCP are the highest (could be also individual outliers only).
Azure vs GCP Performance M30 with 256Gb disk
50 rps, 1 hour duration, 3 executions
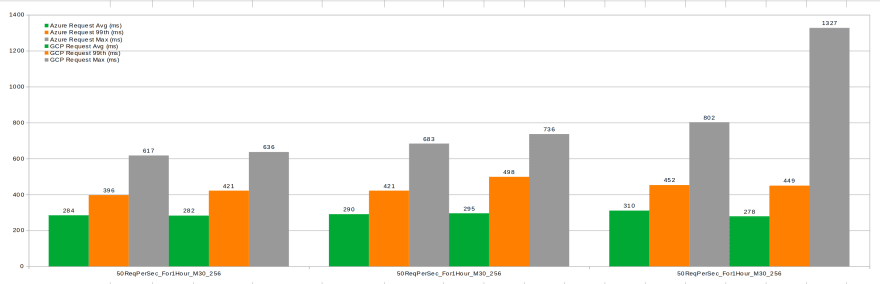
Interpretation:
- In the 1-hour test executions Azure M30 is at the same level as GCP when it comes to average durations, 99th percentiles are almost equal, with the maximal durations for Azure better than GCP's.
Azure vs GCP vs AWS Performance M40 with 128Gb disk
50 rps, 5 minutes duration, 3 executions
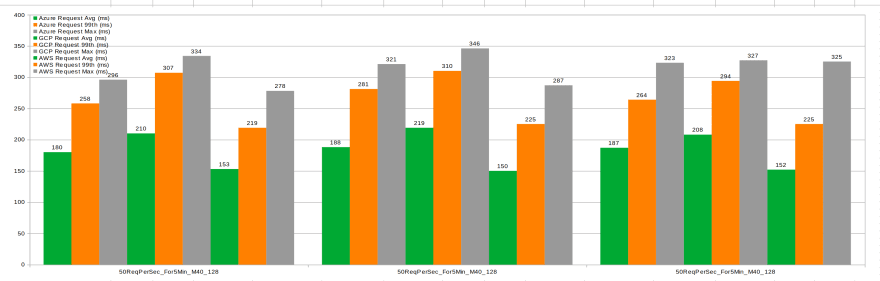
Interpretation:
- AWS M40 is slightly faster than Azure M40 and GCP M40 (however Azure M40 is substantially more expensive, see table above)
50 rps, 1 hour duration, 3 executions

Interpretation:
- AWS M40 is slightly faster than Azure M40 and GCP M40
- GCP and AWS have higher variability (the 3rd AWS test execution resulted even in 5 timeouts out of 180k requests ..)
Azure Performance Different Instance/Storage Sizes
50 rps, 5 minute duration
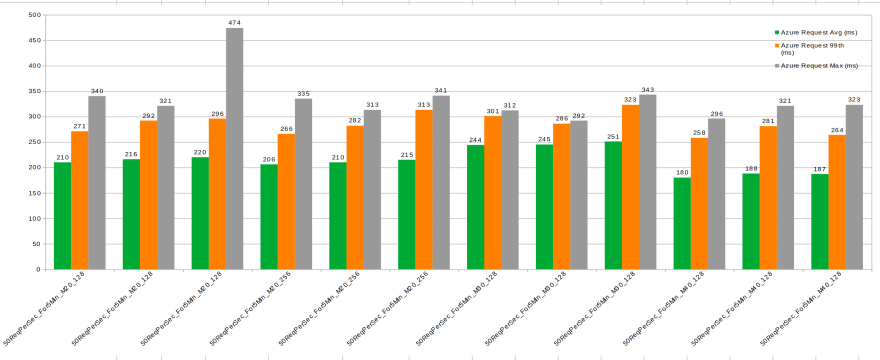
Interpretation:
- Average durations do not improve substantially with the increase of the instance/storage size (even increase from M20 -> M30??)
- 99 percentile and max durations are higher with M20/128 and more stable with M20/128, M30 and M40
50 rps, 1 hour duration

Interpretation:
- Average durations do not improve substantially with the increase of the instance/storage size
- 99 percentile and max durations improve significantly with the increase of the instance/storage size (variability decreases, less outliers)
GCP Performance Different Instance/Storage Sizes
50 rps, 5 minute duration

Interpretation:
- Averages improve slightly with the instance/storage size. 2. Same is valid for 99 percentile and max durations, which are pretty stable
50 rps, 1 hour duration

Interpretation:
- Averages improve slightly with the instance/storage size. 2. Same is not valid for 99 percentile and max durations ... there are strange peaks in case of M40/128 ...
AWS Performance Different Instance/Storage Sizes
50 rps, 5 minute duration

Interpretation:
- Averages are better with M30, but almost no difference with M40 for this load
- High 99 percentile and max durations in case of M20, stable for M30 and M40
50 rps, 1 hour duration
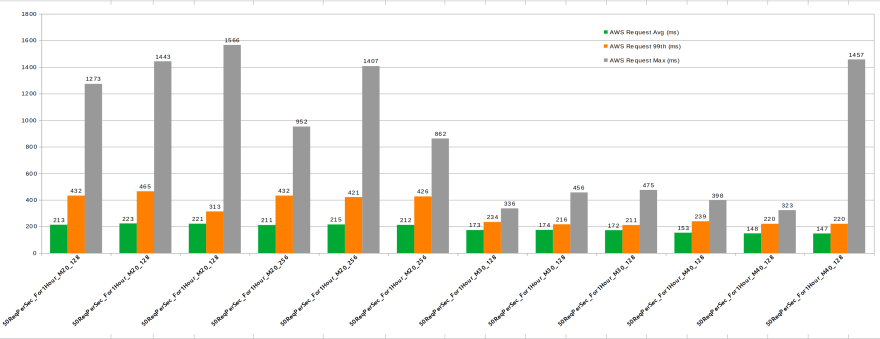
Interpretation:
- Averages are better with M30, but almost no difference with M40 for this load
- High 99 percentile and max durations in case of M20, stable for M30 and M40 (1 execution only has max duration outlier)
MongoDB Metrics Comparison
Max Disk Write Latency
M20, 128Gb, Azure:

M20, 128Gb, GCP:

M20, 128Gb, AWS:

Notes:
- Blue line is the Max Disk Write Latency
- Green line is Average Disk Write Latency
Interpretation:
- AWS has 10-20x lower Max Disk Write Latency (1-2ms stable, only 1-2 spikes within 1h up to 6ms ) compared to Azure (40-60ms, 1 spike within 1h up to 80 ms) and GCP (30-40ms, 2-3 spikes within 1h up to 50 ms). This is a gigantic difference!
Factors possibly affecting the results
There are a few hypotheses as to why the results could be incorrect:
- Hypothesis 1: Burstability of M20 on Azure might lead to good results in shorter test durations, and worse results in longer ones
- Hypothesis 2: There is another bottleneck in the load test infrastructure (K8s node utilization checked)
- Hypothesis 3: Even though all setups use Network Peering between the K8s Cluster and MongoDB Atlas cluster it could be (due to routing issues) that the messages take another less-efficient route.
Conclusion
Overall AWS has a better performance compared to Azure and GCP.
Strangely enough, even though the IOPS numbers for GCP are the highest, it seems to offer the lowest performance.
Azure for sure has its problems with variability/outliers7, but performs relatively well. Having in mind that Azure becomes considerably more expensive with bigger instance/storage sizes, it seems that AWS and GCP are the winner in the M30/M40 range.
The real interesting finding IMHO is the far superior Max Write Disk Latency of AWS ... wondering if MongoDB Atlas is using direct attached storage in AWS vs. network-attached storage in Azure/GCP ...
P.S. I would appreciate any comments pointing out an obvious mistake leading to wrong results!
-
Including the load test automation/setup itself ↩
-
Synchronous = Client calls via HTTPS/REST Service1, Service1 acts as an orchestrator and calls synchronously Service2, Service3 etc. and awaits (async) their responses. Some of the inter-microservice calls are done in sequence, and some in parallel. ↩
-
"Transaction" does not mean database transaction or distributed database transaction. No database transactions are used (no database was harmed ;) ↩
-
Burstable, which means from 2 x 100% = 200% only 40% are provisioned, but accumulated credits allow bursting up to the full 200% from time to time ↩
-
Half of the IOPS are read IOPS and half are write IOPS ↩
-
Non-provisioned, the provisioned IOPS on AWS are very expensive ↩
-
See this post about various disk-related performance issues on Azure ↩

Top comments (2)
This whole posts reads as though one is attempting to micro optimise in a distributed environment. Makes little to no sense.. Network and disk latency are not going anywhere. Am I missing something here?
Not really sure what you mean ..
The simple and straightforward goal I have is to find what is the best instance size/disk size for my load, and if migrating to GCP would be advantageous ...
Additionally, Mongo people keep telling me AWS and GCP are much better for MongoDB Atlas hosting, so wanted to experience it firsthand ;)