
Contents: intro, imports, what will be scraped, process, code, links, outro.
Intro
This blog post is a continuation of the DuckDuckGo web scraping series. Here you'll see how to scrape Related Search Results using Python with selenium library. An alternative API solution will be shown.
This blog post assumes that you know the basics of selenium
Imports
from selenium import webdriver
What will be scraped

Process
For some reason request-html can't locate elements at the bottom of the page when using xpath or css selectors, and scrolldown= parameter didn't help either.
This time selenium was used since it is the easiest way to get the data but at the same time, not the fastest.
Selecting CSS selector to grab query and a link and running the script.
Note №1: running selenium in headless mode didn't return any results, or I was doing something wrong.
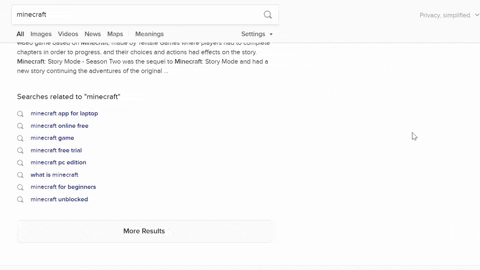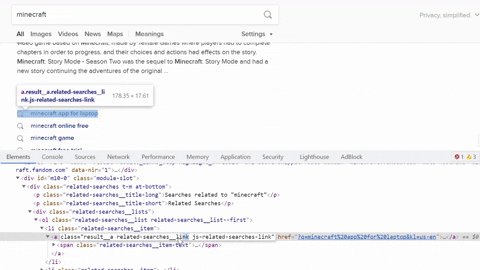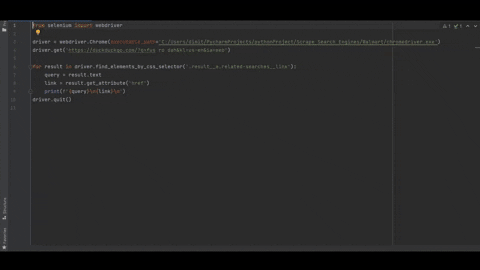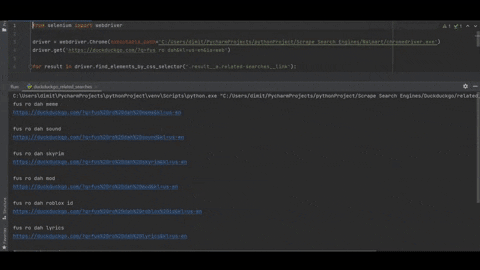
Note №2: the data could be extracted from the tag without <code>selenium</code> use, but it will be a much more time-consuming process.</em></p> <h3> <a name="code" href="#code" class="anchor"> </a> Code </h3> <p></p> <div class="highlight"><pre class="highlight python"><code><span class="kn">from</span> <span class="nn">selenium</span> <span class="kn">import</span> <span class="n">webdriver</span> <span class="n">driver</span> <span class="o">=</span> <span class="n">webdriver</span><span class="p">.</span><span class="n">Chrome</span><span class="p">(</span><span class="n">executable_path</span><span class="o">=</span><span class="s">'/path/to/chromedriver.exe'</span><span class="p">)</span> <span class="n">driver</span><span class="p">.</span><span class="n">get</span><span class="p">(</span><span class="s">'https://duckduckgo.com/?q=fus ro dah&kl=us-en&ia=web'</span><span class="p">)</span> <span class="k">for</span> <span class="n">result</span> <span class="ow">in</span> <span class="n">driver</span><span class="p">.</span><span class="n">find_elements_by_css_selector</span><span class="p">(</span><span class="s">'.result__a.related-searches__link'</span><span class="p">):</span> <span class="n">query</span> <span class="o">=</span> <span class="n">result</span><span class="p">.</span><span class="n">text</span> <span class="n">link</span> <span class="o">=</span> <span class="n">result</span><span class="p">.</span><span class="n">get_attribute</span><span class="p">(</span><span class="s">'href'</span><span class="p">)</span> <span class="k">print</span><span class="p">(</span><span class="sa">f</span><span class="s">'</span><span class="si">{</span><span class="n">query</span><span class="si">}</span><span class="se">\n</span><span class="si">{</span><span class="n">link</span><span class="si">}</span><span class="se">\n</span><span class="s">'</span><span class="p">)</span> <span class="n">driver</span><span class="p">.</span><span class="n">quit</span><span class="p">()</span> <span class="o">------------------</span> <span class="s">''' fus ro dah meme https://duckduckgo.com/?q=fus%20ro%20dah%20meme&kl=us-en fus ro dah sound https://duckduckgo.com/?q=fus%20ro%20dah%20sound&kl=us-en fus ro dah skyrim https://duckduckgo.com/?q=fus%20ro%20dah%20skyrim&kl=us-en ... '''</span> </code></pre></div> <p></p> <h3> <a name="using-duckduckgo-related-searches-api" href="#using-duckduckgo-related-searches-api" class="anchor"> </a> Using <a href="https://serpapi.com/duckduckgo-related-searches">DuckDuckGo Related Searches API</a> </h3> <p>SerpApi is a paid API with a free plan.</p> <p>The difference in using an API solution is that you'll get a faster response since there's no need to render the page. Additionally, iterating over structured <code>JSON</code> is a bit faster process rather than searching selectors from scratch or finding ways to avoid something.<br> </p> <div class="highlight"><pre class="highlight python"><code><span class="kn">import</span> <span class="nn">json</span> <span class="kn">from</span> <span class="nn">serpapi</span> <span class="kn">import</span> <span class="n">GoogleSearch</span> <span class="n">params</span> <span class="o">=</span> <span class="p">{</span> <span class="s">"api_key"</span><span class="p">:</span> <span class="s">"YOUR_API_KEY"</span><span class="p">,</span> <span class="s">"engine"</span><span class="p">:</span> <span class="s">"duckduckgo"</span><span class="p">,</span> <span class="s">"q"</span><span class="p">:</span> <span class="s">"fus ro dah"</span><span class="p">,</span> <span class="s">"kl"</span><span class="p">:</span> <span class="s">"us-en"</span> <span class="p">}</span> <span class="n">search</span> <span class="o">=</span> <span class="n">GoogleSearch</span><span class="p">(</span><span class="n">params</span><span class="p">)</span> <span class="n">results</span> <span class="o">=</span> <span class="n">search</span><span class="p">.</span><span class="n">get_dict</span><span class="p">()</span> <span class="k">for</span> <span class="n">result</span> <span class="ow">in</span> <span class="n">results</span><span class="p">[</span><span class="s">'related_searches'</span><span class="p">]:</span> <span class="k">print</span><span class="p">(</span><span class="n">json</span><span class="p">.</span><span class="n">dumps</span><span class="p">(</span><span class="n">result</span><span class="p">,</span> <span class="n">indent</span><span class="o">=</span><span class="mi">2</span><span class="p">))</span> </code></pre></div> <p></p> <p><img width="100%" style="width:100%" src="https://media.giphy.com/media/FDEwcpBrUe5sXMINWe/giphy.gif"></p> <h3> <a name="links" href="#links" class="anchor"> </a> Links </h3> <p><a href="https://replit.com/@DimitryZub1/DuckDuckGo-Scrape-Related-Searches-python#main.py">Code in the online IDE</a> • <a href="https://serpapi.com/duckduckgo-related-searches">DuckDuckGo Related Searches API</a> </p> <h3> <a name="outro" href="#outro" class="anchor"> </a> Outro </h3> <p>If you have any questions or something isn't working correctly or you want to write something else, feel free to drop a comment in the comment section or via Twitter at <a href="https://twitter.com/serp_api">@serp_api</a>.</p> <p>Yours, <br> Dimitry, and the rest of SerpApi Team.</p>

Top comments (0)