
This article was written by Scott Coulton, a Microsoft Developer Advocate, CNCF Ambassador, and Docker Captain. He has over 10 years of experience as a software engineer in the managed services and hosting space. His design strengths are in cloud computing, automation, and security space.
When you first start your Kubernetes journey, the first thing you need to learn is how to deploy an application. There are multiple resource types that you can use, including pods, deployments and services.
Today, we will first explain what each resource type does and then discuss when and why to use them in your apps.
We will discuss:
- Quick refresher on Kubernetes
- What are Pods?
- What are Services?
- What are Deployments?
- What to learn next
Quick refresher on Kubernetes
Kubernetes is an open-source container management platform for deploying and managing containerized workloads. When running containers in production, you'll have dozens, even thousands of containers. These containers need to be deployed, managed, and connected, which is hard to do manually. That's where Kubernetes comes in. Think of it like a container scheduler.
Kubernetes is designed to work alongside Docker, which is the containerization platform that packages your application and all dependencies together as a container.
Simplified: Docker is used to isolate, pack, and ship your application as containers. Kubernetes is the container scheduler for deploying and scaling your application.
With Kubernetes, we can:
- Deploy services and roll out new releases without downtime,
- Run on a private or public cloud
- Place and scale replicas of a service on the most appropriate server
- Validate the health of our services
- Mount volumes for stateful applications
Now that we have a refresher on Kubernetes let's jump into some of its resources and discuss when to use them. We'll begin with pods.
What are Pods?
A pod is the lowest, or more atomic unit of an application in Kubernetes. It's important to note that a pod is not equal to a container in the Docker world. A pod can be made up of multiple containers. If you have come from a pure Docker background, this can be hard to wrap your head around.
Think of this like a Kubernetes abstraction that represents a group of containers and shared resources for them. For example, a Pod could include a container with your Node.js app and another container that feeds data to the web server.
A pod is a way to represent a running process in a cluster.
If a pod can have more than one container, how does it work? There are some limits we need to be aware of. A pod has the following:
- A single IP address
- Share localhost
- A shared IPC space
- A shared network port range
- Shared volumes
The containers in a pod talk to each other via a local host, whereas pod-to-pod communication is done via services. As you can see from the illustration, the containers in a pod share an IP Address.

Pods are a great way for you to deploy an application, but there is some limitation to the pod resource type. A pod is a single entity, and if it fails, it cannot restart itself. This won’t suit most use cases, as we want our applications to be highly available. But Kubernetes has this issue solved, and we will look at how to tackle high availability further on in the post.
Nodes vs. Pods
In Kubernetes, a pod will always run on a node. Think of a node as a worker machine managed by the master. A node can have multiple pods, and the master automatically schedules the pods across a node.
Anatomy of a Pod
Pods are designed to run multiple processes that should act as a cohesive unit. Those processes are wrapped in containers. All the containers that form a pod run on the same machine and cannot be split across multiple nodes.
All the processes (or containers) inside a Pod share the same resources (such as storage), and they can communicate with each other through localhost. A volume is like a directory with shareable data. They can be accessed by all the containers and share the same data.
Replication controller
We just learned that pods are mortal. If they die, that is their end. But what if you want to have three versions of the same pod running for availability?
Enter the replication controller.
The main responsibility of the replication controller is to prevent failure. It sits above the pod resource type and controls it. Let’s look at an example.
Say I want to deploy 4 of pod x. I would create a replica set. A replica set has a defined number of pods that need to be running (in this case, 4). If one of the pods fails or dies, the replication controller will start a new pod for me, and again, I will still have 4 versions of pod x running.
This functionality handles this issue of pods. It's important to note, however, that the replication controller does not handle everything related to pods, namely, lifecycle. Say we want to upgrade the pods without downtime. A replication controller will not look after this.
Now that we've learned about pods, let's move on to the next Kubernetes resource: services.
What are Services?
If we want to have connectivity to our pods, we will need to create a service. In Kubernetes, a service is a network abstraction over a set of pods. Think of this as a group of pods running on a cluster. Kubernetes services are often used to power a microservice architecture.
Kubernetes gives pods their own IP addresses and a single DNS name for a set of Pods and can load-balance across them. They provide features for standardizing a cluster, such as:
- Load balancing
- Zero-downtime deployments
- Service discovery between applications
This allows for the traffic to be load balanced for failures. A service allows Kubernetes to set a single DNS record for the pods. As we mentioned earlier, each pod has a separate IP address. With the service resource type, you would usually define a selector like the example in C++ below:
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app: MyApp
In addition to this, kube-proxy also creates a virtual IP in the cluster to access the service. This virtual IP then routes to the pod IPs. If the pod IPs change or new pods are deployed, the service resource type will track the change and update the internal routing on your behalf.

What are Deployments?
Now for the last piece of the puzzle: deployments. The deployment resource type sits above a replica set and can manipulate them. In other words, deployments provide updates for pod replica sets.
To do so, you describe a desired state in a Deployment, and the Deployment Controller will change to the desired state at a controlled rate. This allows you to run a stateless application. If you need to do an upgrade, you need to replace the replica set. This action will cause downtime to your application.
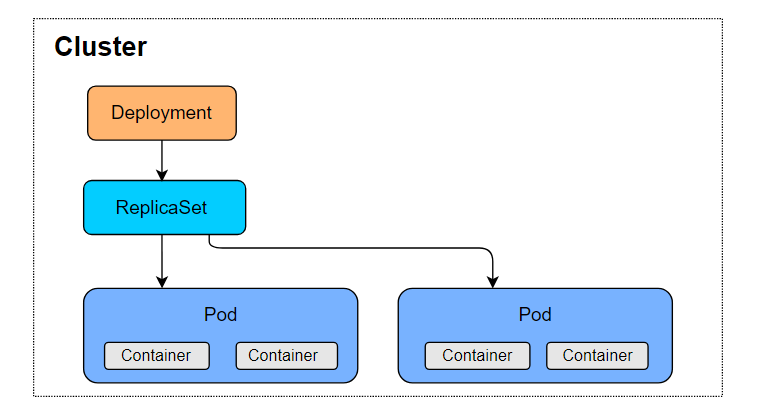
One of the main benefits of Kubernetes is its high availability. Deployments give us the functionality to do upgrades without downtime. As you do in a replica set, you specify the number of pods you would like to run.
Once you trigger an update, a deployment will do a rolling upgrade on the pods while ensuring that the upgrade is successful for each pod before moving to the next.
Let's look at an example of a deployment to see how they are created in main.go.
kubectl create \
-f deploy/go-demo-2-db.yml \
--record
kubectl get -f deploy/go-demo-2-db.yml
The output of the latter command is as follows.
NAME READY UP-TO-DATE AVAILABLE AGE
go-demo-2-db 0/1 1 0 4s
So, what happens if we rollout a new version of our application and something goes wrong? Deployments have us covered there as well, as we can just as easily rollback a deployment.
There is one caveat to this: if you are using a PVC (persistent volume claim) and have written something to the claim. That will not be rolled back. Deployments control replica sets, and replica sets control pods. So, when use a deployment resource type, you still need a service to access it.

Pro Tip: In a production environment, the best practice is to use deployments for our applications within Kubernetes, but it's still important to understand how deployments work.
What to learn next
Congrats! You've now learned the basics of pods, services, and deployments. You've familiarized yourself with their uses, pros, and cons. There is still a lot to learn to master Kubernetes and understand all it has to offer for your apps.
A good next step would be to learn the following:
- How to define pods
- Components of pod scheduling
- Creating Split API pods
- Rolling back failed deployments
- Updating multiple objects
To get started with these concepts and more, I recommend Educative's course A Practical Guide to Kubernetes. You'll start with the fundamentals of Kubernetes and learn how to build, test, deploy, and upgrade applications. You'll also learn how to secure your deployments and manage resources. By the end, you'll be able to use Kubernetes with confidence.
Happy learning!
Continue reading about Kubernetes and Docker on Educative
- Deploying your first service on Kubernetes: Demystifying ingress
- Getting started with Docker and Kubernetes: a beginners guide
- Docker Compose Tutorial: advanced Docker made simple
Start a discussion
What is your favorite use case of Kubernetes? Was this article helpful? Let us know in the comments below!

Top comments (0)