Machine Learning Process for Decision-Making
Machine learning applications have gained widespread adoption in various industries. In general, the entire machine learning lifecycle, from development to deployment, can be summarized as shown in Figure 1. On a larger scale, machine learning applications usually undergo two processes: offline development and online deployment. Within each process, the value residing within data is revealed step-by-step through raw data, features, and finally from models.
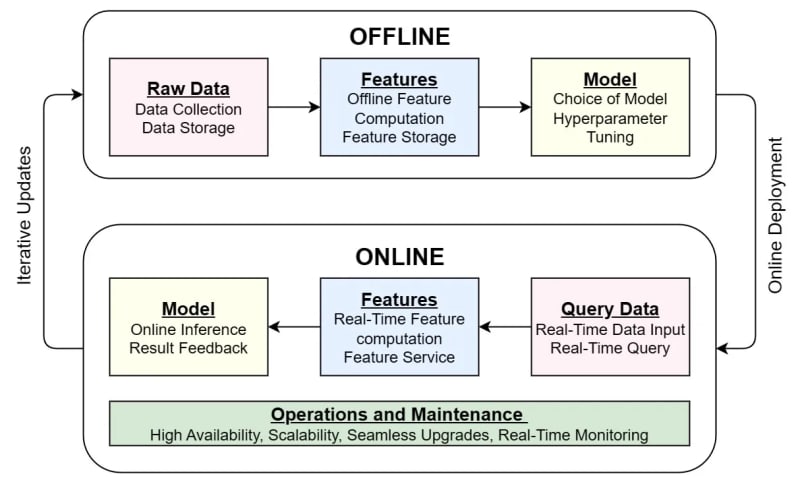
- Raw data: data collected (cleaned), for example, transactional records including transaction amount, timestamp, and merchants. Query data here means real-time data that triggers an online inference, for example, data generated from a card swipe action which is sent to the server for fraud detection.
- Feature: Information extracted from raw data that reveals richer insights. These features are essential in generating high-quality models. For example, the average amount spent by a user for the past three months.
- Model: Decision rules that are trained from thousands to even billions of features generated from data. It depicts the fundamental patterns of data from a high-dimensional perspective and is able to predict behaviors based on data.
In practice, there are established industrial standards for handling data and models. However, when it comes to features, there is still no unified methodology or toolchain in the industry in the case of decision-making scenarios. Decision-making applications, such as risk assessment and personalized recommendations, have seen widespread deployment by enterprises. Feature engineering for decision-making is relatively more flexible and complex. As a result, no standardized methodology or toolchain has been established.
Real-Time Feature Computation is Essential
In decision-making applications that require strict real-time performance, such as credit card transaction anti-fraud, the response time is required to be at millisecond scale. As a significant part of the whole inference process, the end-to-end latency for a query is typically set at the level of a few tens of milliseconds.
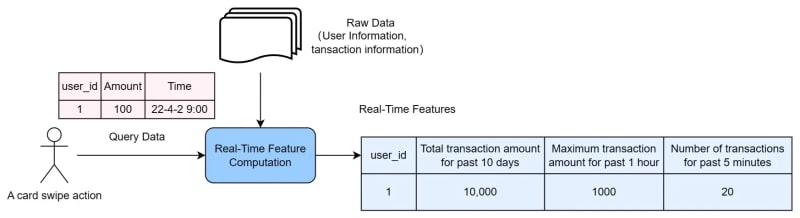
Window aggregation is one of the most common patterns for real-time feature computation. When an event occurs, a time window is constructed from the timestamp when the event happens, to an earlier timestamp. This window can be a few minutes, a few hours, or a few days. The aggregation is then performed on this time window, creating a time series feature. As shown in Figure 2, the real-time features are calculated for time windows of 10 days, 1 hour, and 5 minutes. The essence of real-time feature computation is that it captures data features from the most recent time period, providing strong support for rapid decision-making.
The Challenge
In the following, I will share the major challenge we have faced in the process of feature engineering in decision-making scenarios, and how we tackle it in terms of design principles and architectural design practices for a real-time feature computation platform. Hopefully, you will have a better understanding of real-time feature store systems and the typical workflows.
What is Online-Offline Consistency?
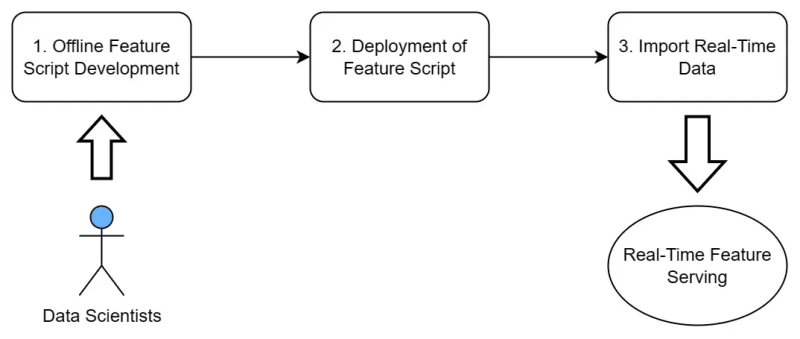
Without a standardized methodology or toolchain, three steps are required to develop real-time feature computation functionality, as shown in Figure 3. First, the developing of offline feature scripts by the data scientists, the result of which is used for model training; Second, the refactoring of feature script by the engineering team to fulfill the strict real-time requirement for online inference; Last but the “most”, ensuring consistency for online-offline computation logic. It’s an iterative process that involves back-and-forth communication, collaboration, and significant resources and manpower.
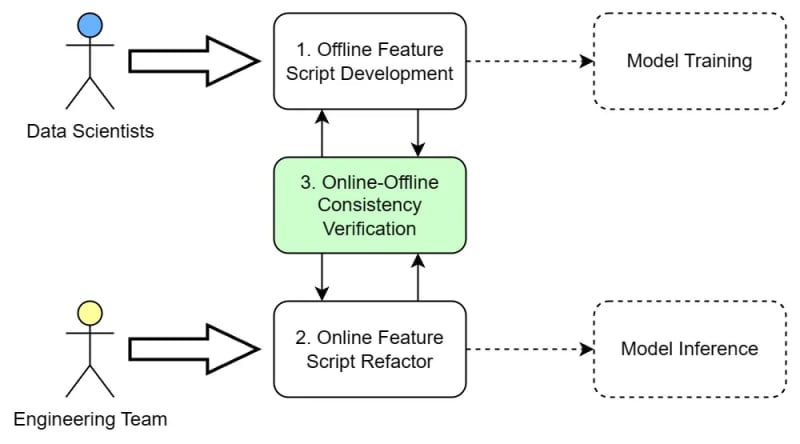
I have listed the details of the three steps required in Table 1. A few key takeaways:
- Data scientists often use tools like Python and SparkSQL for developing feature scripts, but these scripts typically cannot meet the performance and operational requirements for real-time feature computation, such as low latency, high throughput, and high availability.
- Due to the involvement of two teams, data scientists and engineering teams, using different toolchains and systems, ensuring consistency between these two systems is crucial.
- From our experiences in numerous deployment cases, the consistency check consumes the most manpower and time, due to the need for back-and-forth communication, alignment of requirements, and extensive testing.
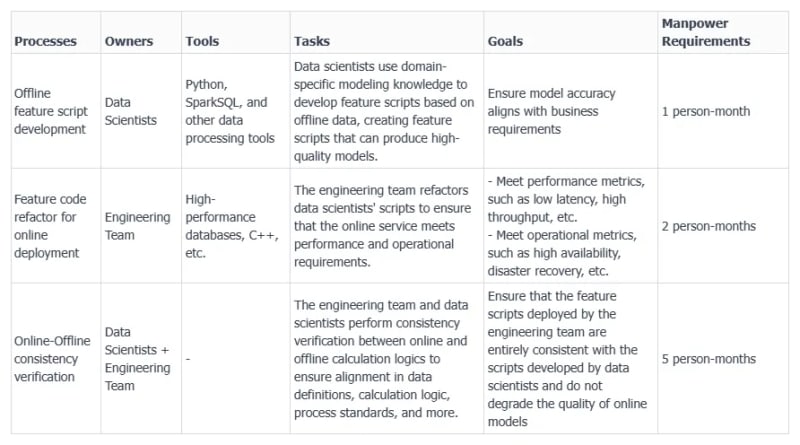
Table 1: Major Steps for Real-time Feature Computation Development Process from Script to Online Service without a Standardized Toolchain
Why is it so bad?
You may wonder, why does it require so much effort to ensure consistency? Where do these inconsistencies come from? Several factors can lead to inconsistencies between online and offline calculation logic, including:
- Inequality in tool capabilities: Python is the preferred tool for data scientists, while engineering teams often use high-performance databases to refactor Python scripts. These tools may have unequal expressive capabilities, leading to compromises in calculation logic or the need to supplement capabilities using languages like C/C++ to achieve consistency.
- Cognitive differences in requirement communication: Data scientists and engineering teams may have different perceptions of data definitions and processing methods. For example, a scenario from Varo Bank, an online bank in the United States, is mentioned, where there was an inconsistency in the definition of “account balance” (Feature Store: Challenges and Considerations). While engineering teams naturally assumed that the definition of “account balance” in the online environment should represent the actual balance at that moment, data scientists considered it challenging to construct “real-time account balance” from offline data, and instead used a simpler definition based on the balance at the end of the previous day. This difference in perception led to inconsistencies in online and offline calculation logic.
Ensuring the consistency of online and offline calculation logic is essential but labor-intensive. It is necessary to re-evaluate the entire feature computation process from development to deployment, aiming to establish a more efficient methodology and corresponding architecture to support the growing number and scale of machine learning implementations.
What do we want?
We have seen that the online and offline computation logic consistency verification is a bottleneck in the entire system implementation. Ideally, if we aim to improve the overall process, we expect to have an efficient “development equals deployment” workflow. As shown in Figure 4, in this optimized workflow, data scientists’ scripts can be deployed instantly without the need for additional code refactoring or additional online-offline consistency verification. If this methodology based on the workflow can be realized, it will significantly enhance the end-to-end process of real-time feature development and deployment, reducing the human resource costs from a total of 8 person-months to just 1 person-month.
What do we need?
To achieve the optimization goal of “development equals deployment” while ensuring high performance for real-time computation, we summarize the following technical requirements for a new architecture:
- Low latency and high concurrency for online real-time feature computation. In the optimized workflow (Figure 4), where data scientists’ scripts can be deployed directly, it’s essential to carefully address a series of engineering challenges for online computation. The primary requirement is to meet the low latency and high concurrency demands for real-time computation. Additionally, aspects like reliability, scalability, disaster recovery, and operational considerations are crucial in real-world enterprise production environments. It’s evident that relying solely on data scientists using Python scripts for feature computation won’t meet these conditions.
- Unified programming interface for both online and offline. To reduce the overall development-to-deployment costs, it’s desirable to have a unified programming interface that is consistent for both online and offline use. This eliminates the need for script refactoring during deployment, ensuring a smoother workflow.
- Assurance of online and offline computation consistency. The optimization goal is to eliminate the need for additional high-cost online-offline consistency verification. Therefore, ensuring consistency in computation between online and offline systems within the architecture is a crucial issue that must be addressed. Meeting these requirements is essential for creating an efficient, unified, and high-performance architecture for real-time feature computation that supports the “development equals deployment” approach.
Design Principle and Practice — OpenMLDB
To meet the technical requirements mentioned above, I introduce OpenMLDB, which is an open-source, cost-effective, and efficient enterprise solution. OpenMLDB is an open-source machine learning database developed by 4Paradigm, primarily designed to build efficient solutions for feature computation scenarios.
OpenMLDB was developed in-house for 5 years before it was open-sourced in 2021. It has been part of 4Paradigm solutions which are implemented in over 100 use cases, covering more than 300 nodes. Example use cases include precise marketing, risk assessment, risk management, customer acquisition, personalized recommendations, anti-money laundering, anti-fraud, and many more. Currently, active community users of OpenMLDB include Akulaku, Huawei, Vipshop, 37Games, and others.
The architectural design of OpenMLDB adheres to the technical requirements listed above. It achieves the specific functionalities through in-house development or optimizations of existing open-source software.

As shown in Figure 5, OpenMLDB consists of three major portions: Offline portion, Consistency portion, and Online portion. Several key modules are explained below:
- SQL(+): OpenMLDB exposes SQL as a unified interface for users. Since standard SQL doesn’t optimize operations related to feature computation (such as time series window operations), it extends the functionality beyond standard SQL, supporting more feature-friendly syntax.
- Consistency Execution Plan Generator: This is a core module that ensures the consistency of online and offline computations. It mainly includes SQL syntax tree parsing and an execution plan generator based on LLVM. The unified execution plan generator can translate a given SQL into different optimized execution plans for online and offline calculations while ensuring the consistency of both.
- Distributed Batch Processing SQL Engine Spark(+): For batch processing SQL engine used for offline development, OpenMLDB has undergone intense optimization based on Spark at the source code level, efficiently supporting extended syntax for feature computation in SQL.
-
Distributed Time-Series Database: The core real-time computing functionality is mainly carried by the storage engine and real-time SQL engine, forming a distributed high-performance time-series database. The SQL engine is developed in C++, which is highly optimized for performance. The data storage engine mainly stores the latest data required for feature computation in time windows. There are two implementations available for the storage engine:
- a. In-house built memory storage engine (built-in): To optimize online processing latency and throughput, OpenMLDB uses an in-memory storage solution, building a double-layered skip list index structure. This data structure is especially suitable for quickly finding data sorted by timestamp under a particular key. This in-memory index structure can achieve millisecond-level query latency for time-series data, and its performance is far superior to commercial in-memory databases.
- External storage engine based on RocksDB: If you are not sensitive to performance but want to reduce memory usage, you can choose the external storage engine based on RocksDB.
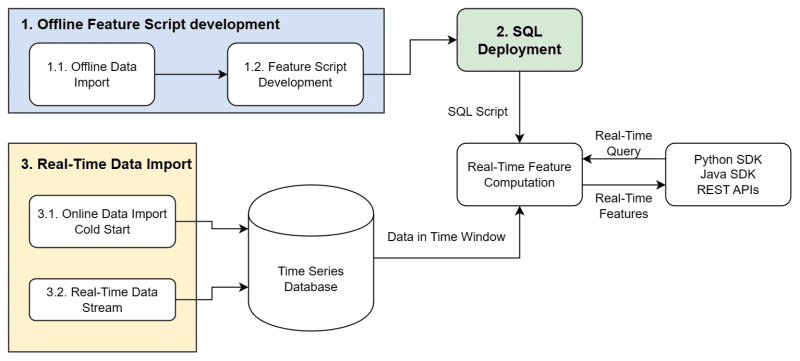
With the core components mentioned above, OpenMLDB can achieve the ultimate optimization goal of “Development Equals Deployment”. The following Figure 6 summarizes the overall usage process of OpenMLDB, from offline development to online deployment.
For more information on OpenMLDB:
- Website: https://openmldb.ai/
- GitHub: https://github.com/4paradigm/OpenMLDB
- Documentation: https://openmldb.ai/docs/en/
- Join us on Slack !
This post is a re-post from OpenMLDB Blogs.

Top comments (0)