
Um throttle “auto regulado” no lado do client até a leitura do capítulo ‘Handling Overload’ do livro SRE do Google era uma abordagem desconhecida pra mim, então, resolvi fazer alguns testes, durante esse processo descobri que não tinha muito material sobre esse tema e nem uma lib para fazer exatamente o que eu queria, então resolvi escrever esse post.
Client-Side Throttling
Não importa o quão eficiente seja sua política de balanceamento de carga, eventualmente alguma parte do seu sistema ficará sobrecarregada. O tratamento adequado das condições de sobrecarga é fundamental para o funcionamento de um sistema de serviço confiável — SRE-Book
Existem várias maneiras de lidar com sobrecarga, dependendo da parte da aplicação com a qual você está trabalhando, entretanto, achar que algo, ou algum estratégia, será 100% à prova de falhas, um equivoco . Você pode tornar sua infra melhor escalável, pode empregar limite de carga para rejeitar solicitações adicionais que você sabe que não pode lidar imediatamente, customer quotas e etc. Embora todas essas sejam ótimas abordagens para resolver o problema, fazer mais perto do client (na origem) para tentar não repassar o tráfego quando o back-end está tendo dificuldades, será um caminho para melhorar o funcionamento de outras estratégias.
Como aplicar a Client-Side Throttling
Quando um client detecta que uma parte significativa de suas solicitações recentes foi rejeitada, ele começa a se autorregular e limitar a quantidade de tráfego de saída que gera, o que é chamado de Adaptive throttling. A ideia original para a implementação vem do capítulo ‘Handling Overload’ do livro SRE do Google.
O Adaptive throttling é calculado da seguinte forma:
(Por Google)
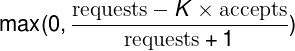
Porém, de acordo com Rafael Capucho, existe um possível problema com esta abordagem.
Minha preocupação com essa probabilidade é que, se o servidor ficar inativo por mais de 2 minutos, o valor P0 ficará em 1, rejeitando localmente cada nova solicitação ao servidor, de modo que o aplicativo cliente não será capaz de configurar um nova conexão. Como resultado disso, o aplicativo cliente nunca terá outra solicitação chegando ao servidor.
Gostaria de sugerir uma nova medida de probabilidade, P 1 , que limita em 90%… — Rafael Capucho

(Por Rafael Capucho)
Esta foi a abordagem usada na biblioteca adaptive-throttling. Onde você passa sua requisição é ela autorregula os limites de saidá. Segue um exemplo de uso:
const { AdaptiveThrottling } = require('adaptive-throttling');
const axios = require('axios');
const adaptiveThrottling = AdaptiveThrottling();
adaptiveThrottling
.execute(() => {
return axios.get('/user?ID=12345');
})
.then((response) => {
console.log('success', response.data);
})
.catch((error) => {
// Se o servidor estiver com dificuldades
// erros "The request was throttled." podem ser lançados, nem indo no servidor, ajudado assim a aliviar a sobrecarga.
console.log('error', error.message);
});
Fiz um desenho tentando evidenciar onde o cenário com Adaptive Throttling complementa algumas outras soluções de contorno.

Enfim, como não existe uma solução mágica, considere fundamental garantir que as tarefas individuais sejam protegidas contra sobrecarga e Adaptive throttling vem pra ser mais um ferramenta com esse propósito.
Bônus
Neste mesmo capítulo temos uma parte que aborda quando aplicar retry e como, aproveitando que estava com a mão na massa, fiz uma “extensão”
para a lib influenciado pela parte sobre “per-client retry budget request”, porém, no meu caso, usei a própria probabilidade de rejeitar request, que vimos em Client-Side Throttling, como limitador das retentativas.
(adaptive-throttling-with-retry)

Top comments (0)