The code for calculating CSV files in Java is too cumbersome, and relying on databases can lead to complex structures. esProc provides JDBC drivers and computation libraries, which can embed SPL statements in Java and directly query CSV files as data tables, making it much more convenient.
Download esProc first, recommend standard edition: Free download
Download and install the corresponding version.
Before configuring the Java environment, try whether the installation of esProc is successful. Prepare a standard CSV file:

Open the esProc IDE, create a new script, and write the SPL statement in cell A1 to read the CSV file:
![]()
Press ctrl-F9 to execute, and you can see the execution result on the right side of the IDE. The file is read as a data table, which is very convenient for debugging SPL code.
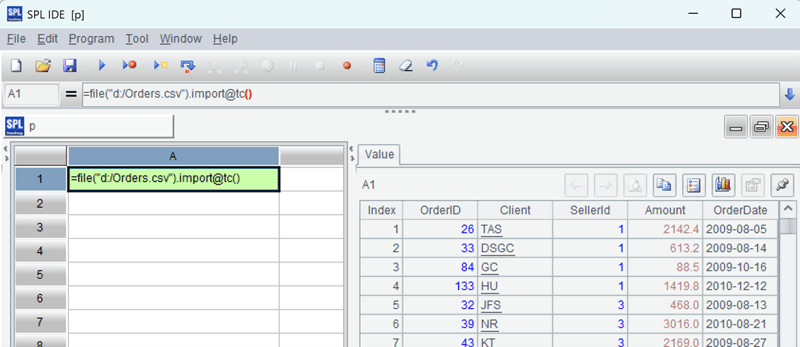
The IDE is running normally, indicating that esProc’s own environment is functioning properly. Then configure the Java environment.
Find the esProc JDBC related jars from the directory “[Installation directory]\esProc\lib”: esproc-bin-xxxx.jar, icu4j_60.3.jar.
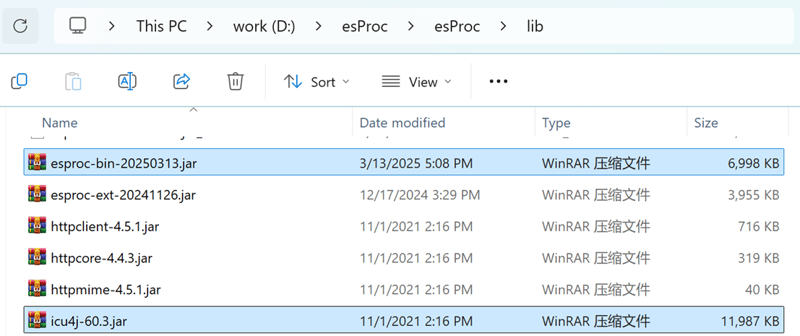
Deploy these two jar packages to the class path of the Java development environment.
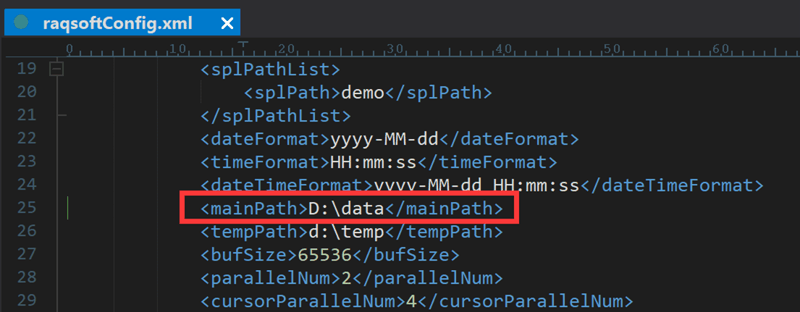
Find the esProc configuration file raqsoftConfig. xml from the directory “[Installation directory] \ esProc \ config” and deploy it to the Java development environment’s class path. The configuration file can be used without modification, and the mainPath locates the default path for various files such as CSV files, which can be modified as needed.
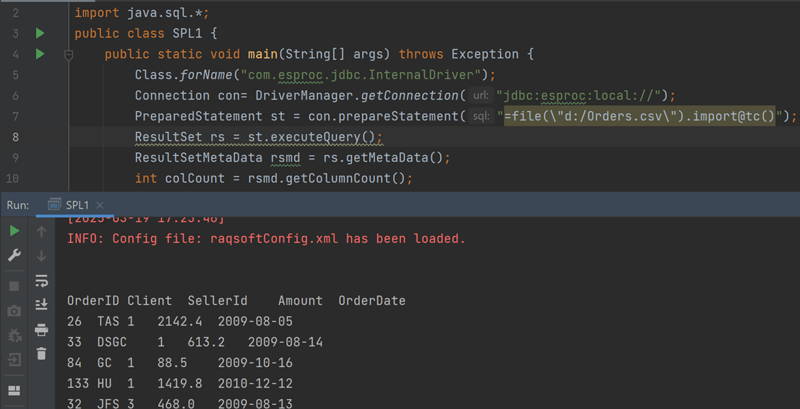
Next, you can write Java code to execute SPL through esProc JDBC:
Class.forName("com.esproc.jdbc.InternalDriver");
Connection con= DriverManager.getConnection("jdbc:esproc:local://");
PreparedStatement st = con.prepareStatement("=file(\"d:/Orders.csv\").import@tc()");
ResultSet rs = st.executeQuery();
ResultSetMetaData rsmd = rs.getMetaData();
for ( int c = 1; c <= colCount;c++) {
String title = rsmd.getColumnName(c);
if( c > 1 ) {
System.out.print("\t");
}
else {
System.out.print("\n");
}
System.out.print(title);
}
while (rs.next()) {
for(int c = 1; c<= colCount; c++) {
if ( c > 1 ) {
System.out.print("\t");
}
else {
System.out.print("\n");
}
Object o = rs.getObject(c);
System.out.print(o.toString());
}
}
if (con!=null) {
con.close();
}
The first four lines are the key, loading the esProc driver and executing SPL statements to read the CSV file. As can be seen, this part of the code is completely consistent with the code for executing SQL through database JDBC.
Here is the execution result:
Of course, just reading data in won’t reduce much Java workload. Let’s try querying with conditions and design a parameter to replace the prepareStatment with the following code:
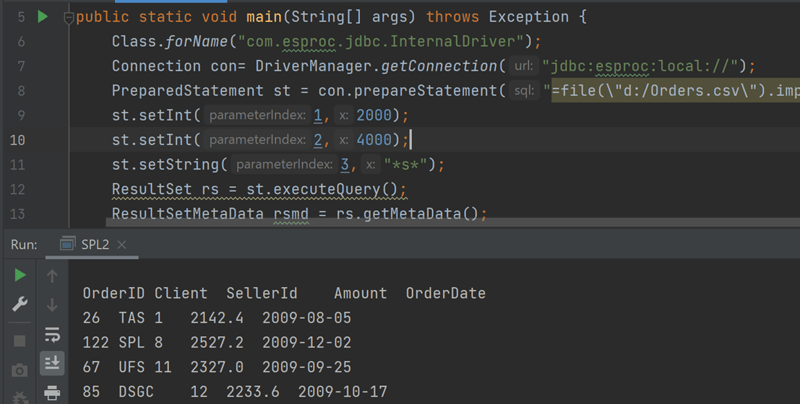
PreparedStatement st = con.prepareStatement("=file(\"d:/Orders.csv\").import@tc().select(Amount>? && Amount<=? && like@c(Client,?))");
st.setInt(1,2000);
st.setInt(2,4000);
st.setString(3,"*s*");
Find the records with Amount between 2000 and 4000 and client containing s (case insensitive). The result after execution looks like this:
The above is the native code SPL of esProc, and esProc also supports simple SQL, making it convenient for database programmers to use. For example, group and aggregation query:
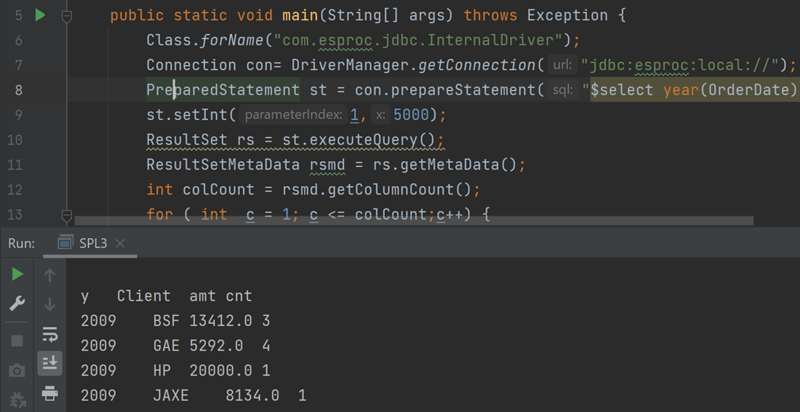
PreparedStatement st = con.prepareStatement("$select year(OrderDate) y, Client,sum(Amount) amt,count(1) cnt from d:/Orders.csv group by year(OrderDate),Client having sum(Amount)>?");
st.setInt(1,5000);
Group and aggregate by year and client and then filter, and after execution, you can see the result:
esProc also supports calculating large CSV files that exceed memory, and the code is also simple. The official website provides specific instructions.

Top comments (0)