title: [TIL] Knowledge Retrieval Architecture for LLM’s (2023) Notes
published: false
date: 2023-07-13 00:00:00 UTC
tags:
canonical_url: http://www.evanlin.com/knowledge-retrieval-architecture/
---
I found this great article while searching online for articles related to RAG and LangChain: [Knowledge Retrieval Architecture for LLM’s (2023)](https://mattboegner.com/knowledge-retrieval-architecture-for-llms/)
# Summary:
This article specifically discusses how to build an LLM Retrieval Architecture (I'm not sure how to translate it well in Chinese XD), from the simplest [OpenAI Cookbook repo](https://github.com/openai/openai-cookbook/blob/main/examples/Question_answering_using_embeddings.ipynb?ref=mattboegner.com) to RAG, RETRO, and REALM architectures.
It also addresses the issue of data hallucinations and discusses two papers: [HyDE](https://arxiv.org/abs/2212.10496?ref=mattboegner.com) and [GenREAD](https://arxiv.org/abs/2209.10063?ref=mattboegner.com).
# Detailed Explanation
## Problems with querying large datasets:
- Be mindful of the 4000 token limit.
- The more tokens, the slower the processing speed.
## Solutions
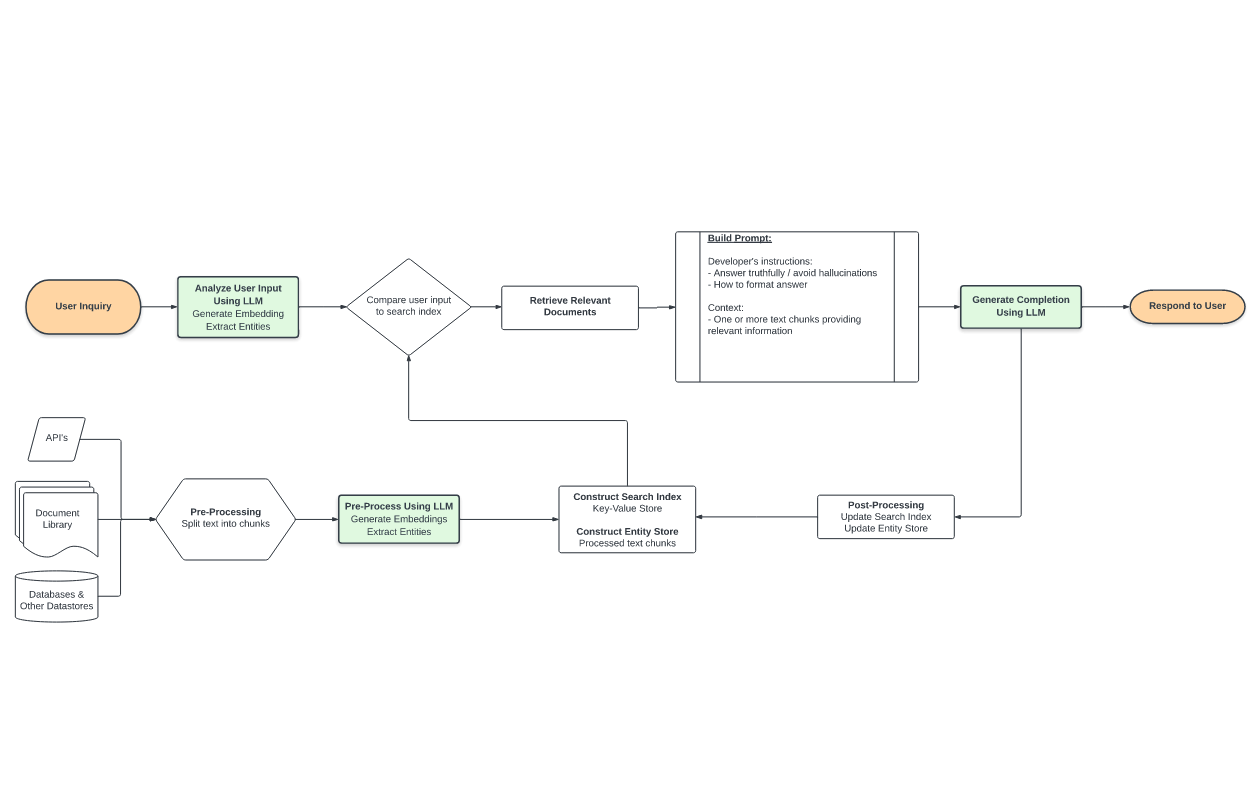
- **(R: Retrieval)** (above) through the introduction of external data
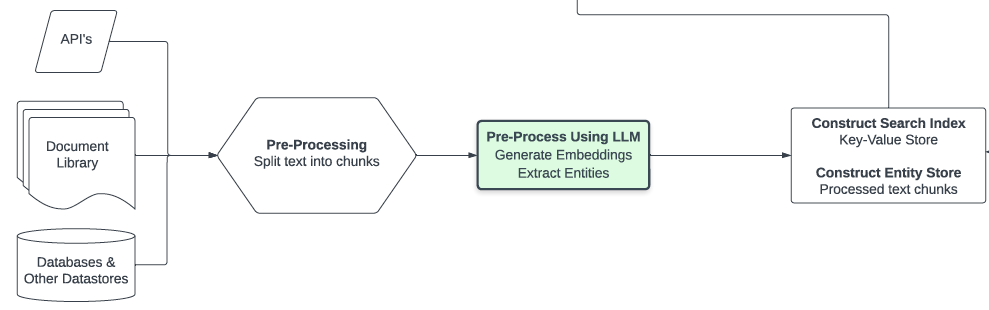
- Many external data sources, txt/pdf/API, are split and then embedded into an Embedding Store within some vector space.

- (Above) The questions asked by the user are also embedded to find relevant data. For example: Asking where to find places for exercise and weight loss will be very close to the "vector space" of gyms.
- **(A: Augment)** Augmentation:
- Put the relevant content and the user's question together in a Prompt to ask. However, in order to make the answer more effective, you may need relevant augmentation statements. For example:
- `Please reply in Chinese`
- `Please do not answer if you don't know the answer`
- `If necessary, please give me follow-up questions`
- Related information can be found at: [OpenAI Cookbook repo](https://github.com/openai/openai-cookbook/blob/main/examples/Question_answering_using_embeddings.ipynb?ref=mattboegner.com)
- **G: Generative) Generation:**
- This is to throw the relevant data into the LLM to generate an answer.
# Optimization Design
- Use [GPT Index](https://gpt-index.readthedocs.io/en/latest/guides/primer.html?ref=mattboegner.com) to measure the responses of the LLM you are using. And this kind of optimization design,
# Related Information
- [Paper: HyDE](https://arxiv.org/abs/2212.10496?ref=mattboegner.com)
- [Paper: GenREAD](https://arxiv.org/abs/2209.10063?ref=mattboegner.com).
- [OpenAI Cookbook repo](https://github.com/openai/openai-cookbook/blob/main/examples/Question_answering_using_embeddings.ipynb?ref=mattboegner.com)
- [GPT Index](https://github.com/jerryjliu/gpt_index?ref=mattboegner.com)
- [Haystack library](https://docs.haystack.deepset.ai/docs/intro?ref=mattboegner.com) for semantic search and other NLP applications
- [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://arxiv.org/abs/2005.11401?ref=mattboegner.com)
- [LangChain](https://github.com/hwchase17/langchain?ref=mattboegner.com)
- [How to implement question answering on documents using GPT3, embeddings, and datasets](https://simonwillison.net/2023/Jan/13/semantic-search-answers/?ref=mattboegner.com)
- [FAISS](https://github.com/facebookresearch/faiss?ref=mattboegner.com) for vector similarity calculation
- [Generate rather than Retrieve: Large Language Models are Strong Context Generators](https://arxiv.org/abs/2209.10063?ref=mattboegner.com)
- [Implementation Code](https://github.com/wyu97/GenRead?ref=mattboegner.com)
Evan Lin
Posted on • Originally published at evanlin.com on
TIL: Notes on Knowledge Retrieval Architecture for LLMs (2023)
For further actions, you may consider blocking this person and/or reporting abuse

Top comments (0)