In this article, we will continue inspecting the quality of the software. Instead of selecting packages to be checked manually, we will use a component called "Dependency Monkey" which can resolve software stacks following programmed rules and verify the application correctness.

Neurathen Castle located in the Bastei rocks near Rathen in Saxon Switzerland, Germany. Image by the author.
Why different combinations of packages?
In the previous article, but mainly in the introductory article to "How to beat Python’s pip" series, we have described a state space of all the possible software stacks that can be resolved for an application stack given the requirements on libraries. Each resolved software stack in such state space can be scored by a scoring function that can compute "how good the given software is". In the figure below, we can see an interpolated scoring function for resolved software stacks created out of two libraries simplelib and anotherlib.
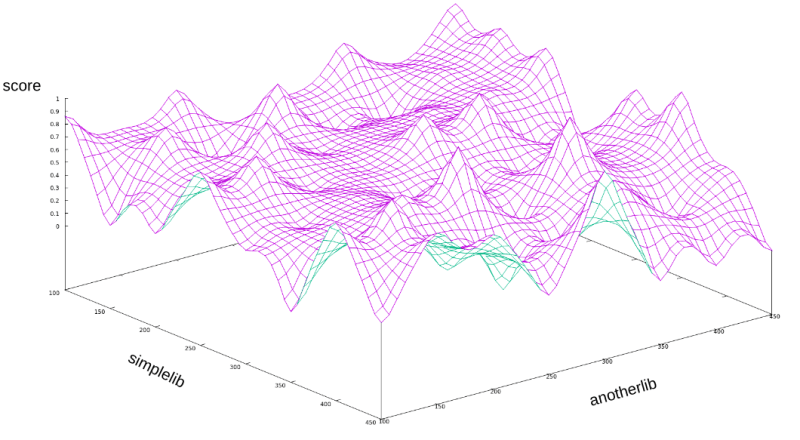
The image above shows an interpolated score function for a state-space made when installing two dependencies "simplelib" and "anotherlib" in different versions (valid combinations of different versions installed together).
The interpolated function above shows a score for two-dimensional state space (one dimension for each package). As we add more packages to an application, this state space is becoming larger and larger (especially considering transitive dependencies that need to be added as well to have a valid software stack).
For real-world applications, we can very easily get tens of dimensions (e.g. by installing tensorflow==2.3.0 we include 36 distinct packages in different versions, thus 36 dimensions plus one dimension for the scoring function). These dimensions introduce distinct input features that affect application behavior as reflected by the scoring function. As we already know based on our last article, any issue in any of these packages can introduce a problem in our application (run time or build time).
All the possible versions (all the possible 36-dimensional vectors following our example) are impossible to test in a reasonable time and thus require some smart picking which versions should be included in the final resolved stack. One slicing mechanism is the actual resolver — it can slice possible resolutions respecting version range specifications of packages in the dependency graph. But how do we limit the number of possible stacks to a reasonable sample even more?
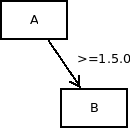
Packages "B" in versions <1.5.0 will be removed based on resolver — they are not valid resolutions following the version range specification of package "A". Hence, they will limit the size of the corresponding feature "B".
A smart offline resolver
Besides removing packages based on version range specification in the resolver, a component called Dependency Monkey is capable of using "pipeline units". The whole resolution process is treated as a pipeline made out of pipeline units of different types that decide whether packages should be considered during the resolution. In other words, if resolved stacks formed out of selected packages should be inspected.
An example can be an inspection of a TensorFlow software stack. If we want to test a specific TensorFlow with NumPy versions for compatibility, we can skip already tested software stack combinations (e.g. based on the queries to our database with previous test results).
Pipeline units create a programmable interface to the resolver which can act based on pipeline units decisions.
Amun inspections: revisited
In the previous article called "How to beat Python’s pip: Inspecting the quality of machine learning software" we introduced a service called Amun that can run software respecting a specification that states how the application is assembled and run. Besides information about the operating system or hardware used, it accepts also a list of packages that should be installed in order to build and run the software.
As Dependency Monkey can resolve Python software stacks, it becomes one of the users of the Amun service. Simply said, if a Dependency Monkey resolves a Python software stack which it considers as a valid candidate for testing, it submits it to Amun to inspect its quality.
We use "quality" to describe a certain aspect of the software. One such quality aspect can be performance or other runtime behavior. The fact an application fails to build is also an indicator of the software stack quality.
Dependency Monkey’s resolution pipeline
One can see Dependency Monkey as a resolver that accepts an input vector and resolves one or multiple software stacks considering the input vector and an aggregated knowledge about the software and packages forming the software stacks. This aggregated knowledge can accumulate information about packages or package combinations seen in the software stacks.
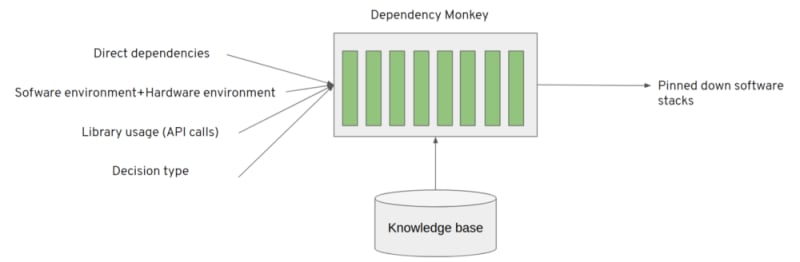
Dependency Monkey is formed out of pipeline units that help to resolve Python software stacks based on the input vector considering the knowledge base.
Checking different package combinations in TensorFlow stacks
Let’s check some dependencies of a TensorFlow stack (I used TensorFlow in version 2.1.0, the dependency listing will differ across versions). If we take a look at the direct dependencies of TensorFlow, we will find packages such as h5py, opt-einsum, scipy, Keras-Preprocessing, and tensorboard in specific versions. They share a common dependency NumPy, a direct dependency of TensorFlow itself (see this GitHub gist for the listing that can change over time with new package releases). All the packages stated can be installed in different versions, which can have different version range requirements on NumPy. The actual version of NumPy installed depends on the resolver and the resolution process that can take into account also other libraries that the user requested to install (besides TensorFlow as a single direct dependency). It’s worth to pinpoint here that any issue in NumPy (even incompatibilities introduced by overpinning or underpinning) can lead to a broken application. So let’s try to test the TensorFlow stack with different combinations of NumPy.
In the upcoming video, you can see a brief walk-through on Dependency Monkey together with a service called Amun. In the first part of the demo (starting at 19:25), Dependency Monkey resolves software stacks considering aggregated knowledge (one of such knowledge is dependency information needed during the resolution) and submits these software stacks to Amun to inspect the quality of the software. The tested software stack is TensorFlow in version 2.1.0, using the build published on PyPI, with different combinations of NumPy resolved (the whole application stack is formed with packages in the same package version but NumPy versions get adjusted respecting the dependency graph).
A note to video: Dependencies that should be locked could be also stated in the direct dependency listing. Note however that by doing so, the dependency will always be present in all the stacks, even though it would not be used and could affect the dependency graph. That’s why pinning of dependencies is performed on a unit level.
The second part of the demo (starting at 28:13) shows Dependency Monkey resolution that randomly samples the state space of all the possible TensorFlow stacks. As we already know, this state space is too large thus checking all the combinations is impossible in a reasonable time. Dependency Monkey randomly generates software stacks that are valid resolutions of TensorFlow software and submits them to Amun which verifies the software stack builds and runs correctly.
Such random state space sampling can spot issues. One such interesting issue in TensorFlow 2.1 stack is a dependency urllib3 that, when installed in a specific version, can cause runtime errors on TensorFlow imports. See this document for a detailed overview. Note the version installed can depend also on other libraries that an application can use besides TensorFlow so there can be affected applications by this issue.
- A link to Dependency Monkey configuration for demo part 1
- A link to Dependency Monkey configuration for demo part 2
- A link to the issue spotted with urllib3 and TensorFlow
Project Thoth
Project Thoth is an application that aims to help Python developers. If you wish to be updated on any improvements and any progress we make in project Thoth, feel free to subscribe to our YouTube channel where we post updates as well as recordings from scrum demos. Check also our Twitter.
Stay tuned for any updates!

Top comments (0)