Problem A — developing and maintaining multiple APIs
If you’re developing and / or consuming multiple RESTful APIs you know the struggle.
You need to work with multiple endpoints for each entity and support different schema for your clients.

Consider the following example for getting orders details via the following Orders API endpoints:
GET /api/orders/{id}
GET /api/orders/GetByStatus/{status}
GET /api/orders/GetByDate/{Date}
GET /api/orders/GetByCustomerId/{id}
GET /api/orders/GetByCustomerEmail/{email}
You see where this is going. Even if you only support retrieving orders by id , you’ll still have different endpoint according to the data that the client asked for:
GET /api/order/details/{orderId}
GET api/ordersWithCustomerDetails/{id}
GET api/orders/shipping/{id}
GET api/orders/payment{id}
Either you return all the above data in your response or you create multiple endpoints for your clients.
Problem B — Frontend and Backend teams integration

Even if you designed the perfect API architecture for your system, different clients might need different data in a different schema or format. I’ve seen backend teams change their response types just to meet the needs of the frontend team.
For example: client A would like to get the products as an object and client B as an array. Client A has to have the payment data WITH the rest of the order’s details but client B would rather get a lighter and faster response with just the order’s number and address.
GraphQL to the rescue!
GraphQL is an open-source data query and manipulation language for APIs, and a run-time for fulfilling queries with existing data. GraphQL was developed internally by Facebook in 2012 before being publicly released in 2015.
GraphQL isn’t tied to any specific database or storage engine and is instead backed by your existing code and data.
Query whatever and however you like!
GraphQL defines a schema and can support any request to the server within this format.
Check it out:

In the above example, the client decides what and how that data returned to it, removing the need of changes in on the server side.
Here’s another use case returning the data using a flag:
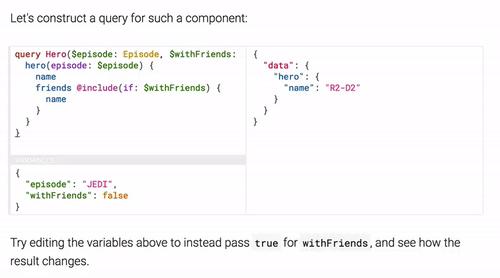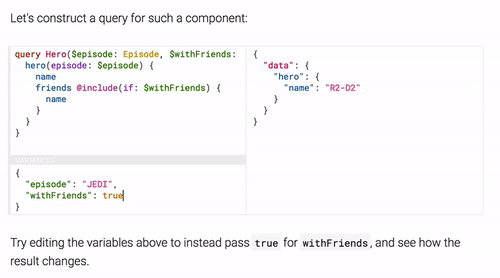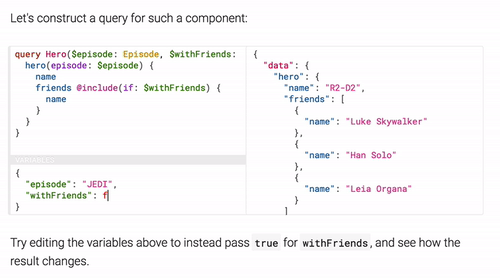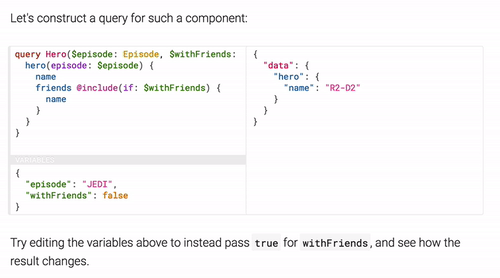
In addition to supporting queries, GraphQL also support object updates via “Mutations”. Those enables you to manipulate the state of an object on the server:

Another cool feature is the GraphQL subscriptions. Subscriptions enables the server to push data to the clients, usually notifying about specific events like creation of an object, update of a field and so on.
GraphQL is a full specification language that supports schema definitions, fields, parameters, variables, a wide range of types, validations and even built in authorization and pagination features.
Implementing GraphQL on your system
Hopefully by now, you can get the feel of out GraphQL implementation can do for you. Implementing GraphQL solution with in your system is not an easy task, while there are frameworks for most frontend and backend languages, using services like Apollo, Relay (JavaScript only) or Prisma that even offers a database ORM solution are very useful and usually worth it.
For example you can use Azure functions as a serverless architecture with Apollo like this.
Get the resources
Here’s great resources to get you started:
*GraphQL.org, the official site, get place to get started
*Get started with .NET Core and GraphQL here
*Apollo, great server, client and tools for GraphQL
*Pluralsight, create couple of courses to get you started here and here

Top comments (0)