
With the advancements in AI technology in the past couple of years, it became clear that it is here to stay and is already impacting our lives and how we interact with technology. As a software developer, I was drawn to discover how to use this new tool to enhance my problem-solving capabilities and provide better solutions.
When studying the field, I came across similarity search as a technique that I could easily implement and would provide a new way for searching information, combining my own databases with the power of language models. In this article, I will explain similarity search and some of its underlying concepts, as well as a walkthrough of a practical implementation of a movie recommendation system using Python, MongoDB, and the OpenAI API. I hope this can help others to better understand one of the many practical applications of language models.
This project was inspired by freeCodeCamp’s video on the same topic. Shout out to freeCodeCamp for providing amazing free resources for learning!
Similarity search
It is a way to search for text data using its meaning. This is initially a confusing concept when compared with regular database searches. Normally, you would look for text matches to find similar words, something like regex, but semantic meaning is something different. Think about the words ‘sea’ and ‘ocean’ - they are completely different words but have similar meanings and a shared context, which make them close to each other in terms of meaning.
But how can we tell our software programs that two different words or sentences have similar meaning? Since this is a human concept, some very smart people came up with a way to represent meaning in a way a computer can understand: vector embeddings.
Vector embeddings
In essence, vectors are arrays of numbers. However, their true power lies in translating meaning, as perceived by human language, into proximity in the vector space. It is beyond the purpose of this article to explain the concept of vector spaces. For now, it is enough to understand that vectors that are close to each other represent similar meaning.

To transform text into a vector we need to use a text embedding model, which is a machine learning model that has been trained to do this task of converting a piece of text into an array of numbers representing its meaning. Models such as Word2Vec, GLoVE, and BERT transform words, sentences, or paragraphs into vector embeddings. Images, audio and other formats can also be transformed into vectors, but we will stick to text for now. To learn more about vector embeddings, check out this great article from Pinecone, a vector database provider.
MongoDB’s vector search
MongoDB is a NoSQL database capable of storing unstructured data at scale. It uses a JSON-like format to store documents with a dynamic schema, making it flexible to store almost any type of data, which is less easy to do with traditional SQL databases where the data must be structured in a tabular form.
One of the things that can be stored in Mongo are vector embeddings, which we already know are just arrays of numbers. Besides that, Mongo has implemented vector search in its databases, which allows us to perform similarity search.
To perform a similarity search, we need two things: a query vector, representing what we are looking for, and a database of vectors, representing our universe of possibly similar vectors. So in this case we need to embed our natural language query, normally coming from the user of our application, into a vector. We also need to have the database with embedded data.
We can use search algorithms like K-Nearest-Neighbours to find the database vectors that are closer to our query vector, and determine which are the most meaningful matches within our search space.
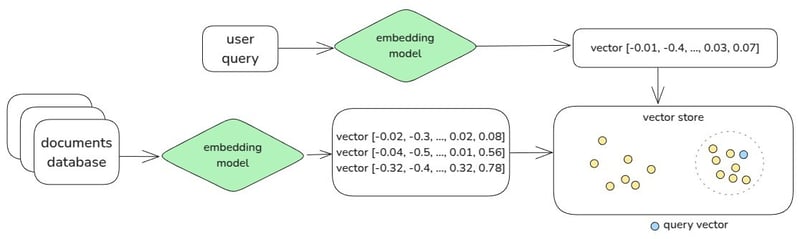
Hopefully this will get clearer with the practical implementation. Let’s get to it.
Generating Embeddings
In this example, we will use Mongo’s sample movie database, specifically the database sample_mflix and the collection embedded_movies, which contains data about movies including title, cast, plot, etc. The sample data is offered for loading whenever you create a new Cluster. If you are not sure how to create a new Mongo cluster, follow the docs to create a free cluster and connect to it.
The sample data for this collection already has a field called plot_embdding that contains embeddings of the plot field. In this case, the field is embedded by OpenAI’s text-embedding-ada-002 model, which generates arrays with 1536 numbers. Different models will output different array sizes.
In a production-like situation where you want to use your own project’s data for this, you would have to generate the embeddings and save them to the database, which can be done in several ways. In this example we are going to use the embeddings already present in the sample data for ease, but we could also generate the embeddings using an open source model with the library sentence-transformers, for example. MongoDB’s documentation has a comprehensive section on how to create embeddings for your data.
Keep in mind that generating embeddings can be computationally expensive, and a good strategy must be outlined if you are doing this for an entire database, especially a large one.
OpenAI’s embedding API models are not free, and you need to set up an account and add balance to it in order to use it, which is what I did for this project. This might be good for production since it is a reliable supplier of AI models, but using open-source models would also be a good strategy. It all depends on the needs of the project.
Since we already have our database field embedded, now we need to create the function that will generate the vector for our search query. We should use the same model used for the rest of the database - mainly because we need to have same-size arrays in our vectors and also because using different models can impact the quality of our search results. We need to get an OpenAI API key and set it up on our environment variables. Reminder to never upload API keys to public repositories!
# generate_embeddings_openai.py
from openai import OpenAI
from dotenv import load_dotenv
import os
load_dotenv(override=True)
openai_key = os.getenv("OPENAI_API_KEY")
client = OpenAI(api_key=openai_key)
def generate_embedding_openai(text: str) -> list[float]:
response = client.embeddings.create(
model="text-embedding-ada-002",
input=text,
encoding_format="float"
)
return response.data[0].embedding
Before running the vector search we need to create a search index in the MongoDB database, which can be done in the Mongo interface or programmatically via the pymongopackage in Python. The index is an essential part to perform the search efficiently.
from pymongo.mongo_client import MongoClient
from pymongo.operations import SearchIndexModel
import time
from dotenv import load_dotenv
import os
load_dotenv(override=True)
# Connect to your Atlas deployment
uri = os.getenv("MONGODB_URI")
client = MongoClient(uri)
# Access your database and collection
database = client["sample_mflix"]
collection = database["embedded_movies"]
# Create your index model, then create the search index
search_index_model = SearchIndexModel(
definition={
"fields": [
{
"type": "vector",
"path": "plot_embedding",
"numDimensions": 1536,
"similarity": "dotProduct",
"quantization": "scalar"
},
{
"type": "filter",
"path": "genres"
},
{
"type": "filter",
"path": "year"
}
]
},
name="plot_embedding_vector_index",
type="vectorSearch",
)
result = collection.create_search_index(model=search_index_model)
print("New search index named " + result + " is building.")
# Wait for initial sync to complete
print("Polling to check if the index is ready. This may take up to a minute.")
predicate=None
if predicate is None:
predicate = lambda index: index.get("queryable") is True
while True:
indices = list(collection.list_search_indexes(result))
if len(indices) and predicate(indices[0]):
break
time.sleep(5)
print(result + " is ready for querying.")
client.close()
Now we have everything we need to run our search: our embedded database, our embedded user query and the search index created in the appropriate field. With all that, the search can be performed as follows:
# query_movies.py
import pymongo
from dotenv import load_dotenv
import os
from generate_embedding_openai import generate_embedding_openai
load_dotenv(override=True)
mongodb_uri = os.getenv("MONGODB_URI")
client = pymongo.MongoClient(mongodb_uri)
db = client["sample_mflix"]
collection = db["embedded_movies"]
query = 'movies about war in outer space'
query_embedding = generate_embedding_openai(query)
results = collection.aggregate([
{
"$vectorSearch": {
"queryVector": query_embedding,
"path": "plot_embedding",
"numCandidates": 1000,
"limit": 4,
"index": "plot_embedding_vector_index"
}
}
])
for r in results:
print(f'Movie: {r["title"]}\nPlot: {r["plot"]}\n\n')
The vector search query get several parameters, which include:
-
queryVector: the user query embedded by the model, in this example we embedded the query 'movies about war in outer space' with the same model we used to embed the rest of the database. -
path: the collection field in which to perform the vector search. -
numCandidates: the number of possible results that are candidates to being the closest one to the user query. -
limit: the numbers of top results we will return from the candidates. The closest ones from the query in the vector space. -
index: the search index we just created.
Results and conclusion
When running our script on query_movies.py we get the following results:
Movie: Buck Rogers in the 25th Century
Plot: A 20th century astronaut emerges out of 500 years of suspended animation into a future time where Earth is threatened by alien invaders.
Movie: Farscape: The Peacekeeper Wars
Plot: When a full-scale war is engaged by the evil Scarran Empire, the Peacekeeper Alliance has but one hope: reassemble human astronaut John Crichton, once sucked into the Peacekeeper galaxy ...
Movie: Space Raiders
Plot: A futuristic, sensitive tale of adventure and confrontation when a 10 year old boy is accidentally kidnapped by a spaceship filled with a motley crew of space pirates.
Movie: V: The Final Battle
Plot: A small group of human resistance fighters fight a desperate guerilla war against the genocidal extra-terrestrials who dominate Earth.
We can notice that all four results have plots related to war in outer space, including some that don’t even share the same keywords, proving our point that this is not a simple text search. This meaning-driven search is a powerful tool to help you create more sophisticated applications.
The true value of this approach lies in the fact that you can use your proprietary data to make this type of search, delivering much better results to users and adding value to your application.

Top comments (0)