When API requests are made one-after-the-other they'll quickly hit rate limits and when that happens:
That tweet spawned a discussion that generated a quest to add rate throttling logic to the platform-api gem that Heroku maintains for talking to its API in Ruby.
If the term "rate throttling" is new to you, read Rate limiting, rate throttling, and how they work together
The Heroku API uses Genetic Cell Rate Algorithm (GCRA) as described by Brandur in this post on the server-side. Heroku's API docs state:
The API limits the number of requests each user can make per hour to protect against abuse and buggy code. Each account has a pool of request tokens that can hold at most 4500 tokens. Each API call removes one token from the pool. Tokens are added to the account pool at a rate of roughly 75 per minute (or 4500 per hour), up to a maximum of 4500. If no tokens remain, further calls will return 429 Too Many Requests until more tokens become available.
I needed to write an algorithm that never errored as a result of a 429 response. A "simple" solution would be to add a retry to all requests when they see a 429, but that would effectively DDoS the API. I made it a goal for the rate throttling client also to minimize its retry rate. That is, if the client makes 100 requests, and 10 of them are a 429 response that its retry rate is 10%. Since the code needed to be contained entirely in the client library, it needed to be able to function without distributed coordination between multiple clients on multiple machines except for whatever information the Heroku API returned.
Making client throttling maintainable
Before we can get into what logic goes into a quality rate throttling algorithm, I want to talk about the process that I used as I think the journey is just as fascinating as the destination.
I initially started wanting to write tests for my rate throttling strategy. I quickly realized that while testing the behavior "retries a request after a 429 response," it is easy to check. I also found that checking for quality "this rate throttle strategy is better than others" could not be checked quite as easily. The solution that I came up with was to write a simulator in addition to tests. I would simulate the server's behavior, and then boot up several processes and threads and hit the simulated server with requests to observe the system's behavior.
I initially just output values to the CLI as the simulation ran, but found it challenging to make sense of them all, so I added charting. I found my simulation took too long to run and so I added a mechanism to speed up the simulated time. I used those two outputs to write what I thought was a pretty good rate throttling algorithm. The next task was wiring it up to the platform-api gem.
To help out I paired with a Heroku Engineer, Lola, we ended up making several PRs to a bunch of related projects, and that's its own story to tell. Finally, the day came where we were ready to get rate throttling into the platform-api gem; all we needed was a review.
Unfortunately, the algorithm I developed from "watching some charts for a few hours" didn't make a whole lot of sense, and it was painfully apparent that it wasn't maintainable. While I had developed a good gut feel for what a "good" algorithm did and how it behaved, I had no way of solidifying that knowledge into something that others could run with. Imagine someone in the future wants to make a change to the algorithm, and I'm no longer here. The tests I had could prevent them from breaking some expectations, but there was nothing to help them make a better algorithm.
The making of an algorithm
At this point, I could explain the approach I had taken to build an algorithm, but I had no way to quantify the "goodness" of my algorithm. That's when I decided to throw it all away and start from first principles. Instead of asking "what would make my algorithm better," I asked, "how would I know a change to my algorithm is better" and then worked to develop some ways to quantify what "better" meant. Here are the goals I ended up coming up with:
- Minimize average retry rate: The fewer failed API requests, the better
- Minimize maximum sleep time: Rate throttling involves waiting, and no one wants to wait for too long
- Minimize variance of request count between clients: No one likes working with a greedy co-worker, API clients are no different. No client in the distributed system should be an extended outlier
- Minimize time to clear a large request capacity: As the system changes, clients should respond quickly to changes.
I figured that if I could generate metrics on my rate-throttle algorithm and compare it to simpler algorithms, then I could show why individual decisions were made.
I moved my hacky scripts for my simulation into a separate repo and, rather than relying on watching charts and logs, moved to have my simulation produce numbers that could be used to quantify and compare algorithms.
With that work under my belt, I threw away everything I knew about rate-throttling and decided to use science and measurement to guide my way.
Writing a better rate-throttling algorithm with science: exponential backoff
Earlier I mentioned that a "simple" algorithm would be to retry requests. A step up in complexity and functionality would be to retry requests after an exponential backoff. I coded it up and got some numbers for a simulated 30-minute run (which takes 3 minutes of real-time):
Avg retry rate: 60.08 %
Max sleep time: 854.89 seconds
Stdev Request Count: 387.82
Time to clear workload (4500 requests, starting_sleep: 1s):
74.23 seconds
Now that we've got baseline numbers, how could we work to minimize any of these values? In my initial exponential backoff model, I multiplied sleep by a factor of 2.0, what would happen if I increased it to 3.0 or decreased it to 1.2?
To find out, I plugged in those values and re-ran my simulations. I found that there was a correlation between retry rate and max sleep value with the backoff factor, but they were inverse. I could lower the retry rate by increasing the factor (to 3.0), but this increased my maximum sleep time. I could reduce the maximum sleep time by decreasing the factor (to 1.2), but it increased my retry rate.
That experiment told me that if I wanted to optimize both retry rate and sleep time, I could not do it via only changing the exponential factor since an improvement in one meant a degradation in the other value.
At this point, we could theoretically do anything, but our metrics judge our success. We could put a cap on the maximum sleep time, for example, we could write code that says "don't sleep longer than 300 seconds", but it too would hurt the retry rate. The biggest concern for me in this example is the maximum sleep time, 854 seconds is over 14 minutes which is WAAAYY too long for a single client to be sleeping.
I ended up picking the 1.2 factor to decrease that value at the cost of a worse retry-rate:
Avg retry rate: 80.41 %
Max sleep time: 46.72 seconds
Stdev Request Count: 147.84
Time to clear workload (4500 requests, starting_sleep: 1s):
74.33 seconds
Forty-six seconds is better than 14 minutes of sleep by a long shot. How could we get the retry rate down?
Incremental improvement: exponential sleep with a gradual decrease
In the exponential backoff model, it backs-off once it sees a 429, but as soon as it hits a success response, it doesn't sleep at all. One way to reduce the retry-rate would be to assume that once a request had been rate-throttled, that future requests would need to wait as well. Essentially we would make the sleep value "sticky" and sleep before all requests. If we only remembered the sleep value, our rate throttle strategy wouldn't be responsive to any changes in the system, and it would have a poor "time to clear workload." Instead of only remembering the sleep value, we can gradually reduce it after every successful request. This logic is very similar to TCP slow start.
How does it play out in the numbers?
Avg retry rate: 40.56 %
Max sleep time: 139.91 seconds
Stdev Request Count: 867.73
Time to clear workload (4500 requests, starting_sleep: 1s):
115.54 seconds
Retry rate did go down by about half. Sleep time went up, but it's still well under the 14-minute mark we saw earlier. But there's a problem with a metric I've not talked about before, the "stdev request count." It's easier to understand if you look at a chart to see what's going on:

Here you can see one client is sleeping a lot (the red client) while other clients are not sleeping at all and chewing through all the available requests at the bottom. Not all the clients are behaving equitably. This behavior makes it harder to tune the system.
One reason for this inequity is that all clients are decreasing by the same constant value for every successful request. For example, let's say we have a client A that is sleeping for 44 seconds, and client B that is sleeping for 11 seconds and both decrease their sleep value by 1 second after every request. If both clients ran for 45 seconds, it would look like this:
Client A) Sleep 44 (Decrease value: 1)
Client B) Sleep 11 (Decrease value: 1)
Client B) Sleep 10 (Decrease value: 1)
Client B) Sleep 9 (Decrease value: 1)
Client B) Sleep 8 (Decrease value: 1)
Client B) Sleep 7 (Decrease value: 1)
Client A) Sleep 43 (Decrease value: 1)
So while client A has decreased by 1 second total, client B has reduced by 4 seconds total, since it is firing 4x as fast (i.e., it's sleep time is 4x lower). So while the decrease rate is equal, it is not equitable. Ideally, we would want all clients to decrease at the same rate.
All clients created equal: exponential increase proportional decrease
Since clients cannot communicate with each other in our distributed system, one way to guaranteed proportional decreases is to use the sleep value in the decrease amount:
decrease_value = (sleep_time) / some_value
Where some_value is a magic number. In this scenario the same clients A and B running for 45 seconds would look like this with a value of 100:
Client A) Sleep 44
Client B) Sleep 11
Client B) Sleep 10.89 (Decrease value: 11.00/100 = 0.1100)
Client B) Sleep 10.78 (Decrease value: 10.89/100 = 0.1089)
Client B) Sleep 10.67 (Decrease value: 10.78/100 = 0.1078)
Client B) Sleep 10.56 (Decrease value: 10.67/100 = 0.1067)
Client A) Sleep 43.56 (Decrease value: 44.00/100 = 0.4400)
Now client A has had a decrease of 0.44, and client B has had a reduction of 0.4334 (11 seconds - 10.56 seconds), which is a lot more equitable than before. Since some_value is tunable, I wanted to use a larger number so that the retry rate would be lower than 40%. I chose 4500 since that's the maximum number of requests in the GCRA bucket for Heroku's API.
Here's what the results looked like:
Avg retry rate: 3.66 %
Max sleep time: 17.31 seconds
Stdev Request Count: 101.94
Time to clear workload (4500 requests, starting_sleep: 1s):
551.10 seconds
The retry rate went WAAAY down, which makes sense since we're decreasing slower than before (the constant decrease value previously was 0.8). Stdev went way down as well. It's about 8x lower. Surprisingly the max sleep time went down as well. I believe this to be a factor of a decrease in the number of required exponential backoff events. Here's what this algorithm looks like:
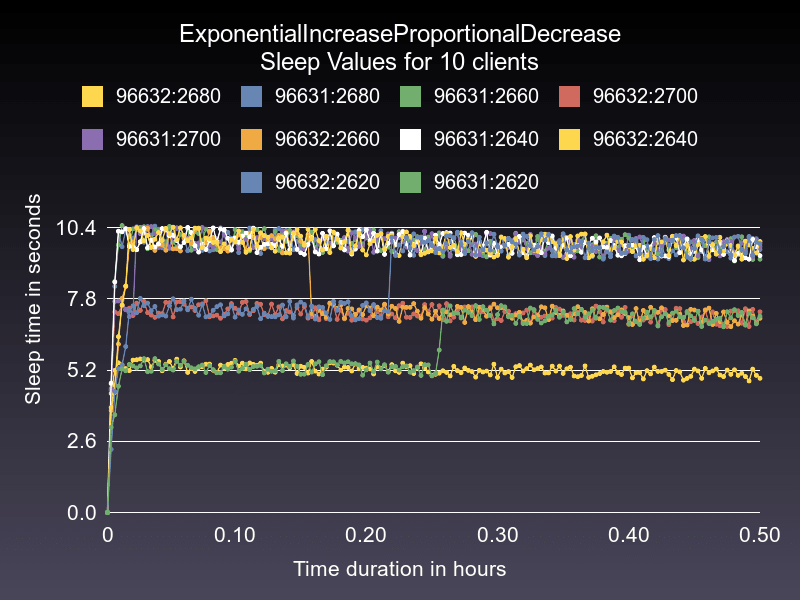
The only problem here is that the "time to clear workload" is 5x higher than before. What exactly is being measured here? In this scenario, we're simulating a cyclical workflow where clients are running under high load, then go through a light load, and then back to a high load. The simulation starts all clients with a sleep value, but the server's rate-limit is reset to 4500. The time is how long it takes the client to clear all 4500 requests.
What this metric of 551 seconds is telling me is that this strategy is not very responsive to a change in the system. To illustrate this problem, I ran the same algorithm starting each client at 8 seconds of sleep instead of 1 second to see how long it would take to trigger a rate limit:

The graph shows that it takes about 7 hours to clear all these requests, which is not good. What we need is a way to clear requests faster when there are more requests.
The only remaining option: exponential increase proportional remaining decrease
When you make a request to the Heroku API, it tells you how many requests you have left remaining in your bucket in a header. Our problem with the "proportional decrease" is mostly that when there are lots of requests remaining in the bucket, it takes a long time to clear them (if the prior sleep rate was high, such as in a varying workload). To account for this, we can decrease the sleep value quicker when the remaining bucket is full and slower when the remaining bucket is almost empty. To express that in an expression, it might look like this:
decrease_value = (sleep_time * request_count_remaining) / some_value
In my case, I chose some_value to be the maximum number of requests possible in a bucket, which is 4500. You can imagine a scenario where workers were very busy for a period and being rate limited. Then no jobs came in for over an hour - perhaps the workday was over, and the number of requests remaining in the bucket re-filled to 4500. On the next request, this algorithm would reduce the sleep value by itself since 4500/4500 is one:
decrease_value = sleep_time * 4500 / 4500
That means it doesn't matter how immense the sleep value is, it will adjust fairly quickly to a change in workload. Good in theory, how does it perform in the simulation?
Avg retry rate: 3.07 %
Max sleep time: 17.32 seconds
Stdev Request Count: 78.44
Time to clear workload (4500 requests, starting_sleep: 1s):
84.23 seconds
This rate throttle strategy performs very well on all metrics. It is the best (or very close) to several metrics. Here's a chart:
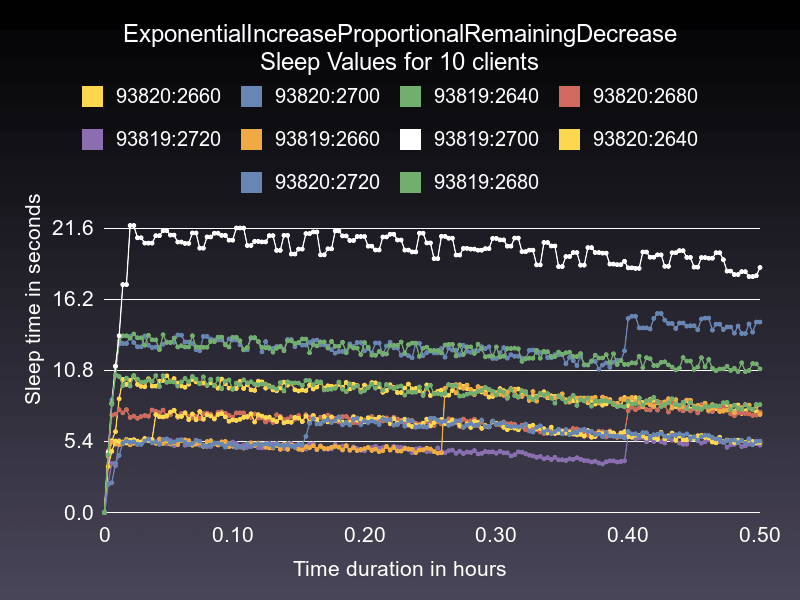
This strategy is the "winner" of my experiments and the algorithm that I chose to go into the platform-api gem.
My original solution
While I originally built this whole elaborate scheme to prove how my solution was optimal, I did something by accident. By following a scientific and measurement-based approach, I accidentally found a simpler solution that performed better than my original answer. Which I'm happier about, it shows that the extra effort was worth it. To "prove" what I found by observation and tinkering could be not only quantified by numbers but improved upon is fantastic.
While my original solution had some scripts and charts, this new solution has tests covering the behavior of the simulation and charting code. My initial solution was very brittle. I didn't feel very comfortable coming back and making changes to it; this new solution and the accompanying support code is a joy to work with. My favorite part though is that now if anyone asks me, "what about trying " or "have you considered " is that I can point them at my rate client throttling library, they have all the tools to implement their idea, test it, and report back with a swift feedback loop.
gem 'platform-api', '~> 3.0'
While I mostly wanted to talk about the process of writing rate-throttling code, this whole thing started from a desire to get client rate-throttling into the platform-api gem. Once I did the work to prove my solution was reasonable, we worked on a rollout strategy. We released a version of the gem in a minor bump with rate-throttling available, but with a "null" strategy that would preserve existing behavior. This release strategy allowed us to issue a warning to anyone depending on the original behavior. Then we released a major version with the rate-throttling strategy enabled by default. We did this first with "pre" release versions and then actual versions to be extra safe.
So far, the feedback has been overwhelming that no one has noticed. We didn't cause any significant breaks or introduce any severe disfunction to any applications. If you've not already, I invite you to upgrade to 3.0.0+ of the platform-api gem and give it a spin. I would love to hear your feedback.
Get ahold of Richard and stay up-to-date with Ruby, Rails, and other programming related content through a subscription to his mailing list.

Top comments (1)
Thank you for sharing this. This was a joy to read!