
A brief conversation about big O
To be honest with you, when I first got into programming I procrastinated learning Big O for quite a while out of intimidation, and this article is really for anyone out there who feels similar. I don’t know if it will help for me to say that most of it is common sense and the math doesn’t get much harder than multiplication. But just in case, I will add some visuals to make this as non-miserable as possible. The graphics are super silly, but honestly that helps me remember things.
If I were to give you the simplest version possible of the idea behind Big O notation, or the time complexity of how your code runs, it would be something like this:
- basic operations are the most efficient
- repeated operations (loops) can be more of a worry for efficiency
- nested loops are among the biggest worries for efficiency
Honestly, that’s the basics. Not too terrible right? There’s also a whole category of things you never have to think about when figuring out the performance of your code. You can consider them “Freebies”. They include:
- basic math, addition and subtraction
- assigning variables
- if/else conditions
- declaring a function
- calling a function (at face value)
- changing variables
If I had to sum the concept of Big O up in simplest terms imaginable, loops are pretty much all we are worried about. I know when I realized that, I felt a lot less intimidated.
💡A note before we begin: This is meant to be the absolute basics, for people who think Big O notation sounds like archaic rituals. There are more nuances, and more descriptors, than I’ve included here. Whenever there is a chance to take clarity vs greater detail, I have chosen clarity. This post is for folks a few months into programming who need basic, actionable info. This is part of a larger series I’m writing on live coding interviews so give that a read as well 🤓
To explain some of these, let’s pretend that in my free time, I like to go on scavenger hunts. My friends make the rules for these hunts and some are less challenging than others. (Sidebar, some people really do this! There is a hobby called geocaching that is pretty much real life treasure hunting. You can read about that here if you are curious. My examples are too silly to conform to really geocaching though so I’ll stick with the term scavenger hunt).
Part I: Constant time or O(1)
🏴☠️ Jamie sends me on a treasure hunt to retrieve a pen from a certain address on Chestnut street. I have one address so only need to go to one house, easy peasy.

This is an example of what we would call “constant time”. Whether the scavenger hunt was for a pen or something else, I’m only knocking on one door in this scenario and it will not change. This is considered a very positive state for algorithm performance, the most optimal actually. An example of a constant operation would be retrieving a value from a JavaScript object.
const person = {
name: "Ann",
hobbies: ["drawing", "programming"],
pet: "dog"
}
console.log(person.name)
Because JavaScript objects are an example of a hash, it is very performant to look up some value in an object. It is a perfect analog to having an exact address and being able to go straight to it without searching further. Regardless of what is inside, the step of retrieving the item is considered to run in constant time.
💡For this reason, objects/hash data structures are often your friend in code challenges.
Sometimes getting arrays into an object format can be hugely helpful for good performance in these types of challenges. We call this constant time O(1), in Big O notation.
Part 2: Logarithmic time, or O(log N)
🎁 My friend Jake has set me on a trickier task. There is a new development being built near me but they have not added visible street signs. If I walk up to the houses though, They have notated the address on beams by the front door.
I don’t really want to have to walk up to each house individually, but after thinking about it I realize Jake has shared that the home address numbers increase as you progress down the street.

I don’t know the starting number as the road continues a ways past this cul de sac in the opposite direction, so I’m not sure what the lowest house number is. But I do know I’m looking for #22. I realize that if I start in the middle of the street, I’ll see if the address is lower or higher than what I’m looking for, and can knock out half the houses on the block, so I don’t have to search those.

I see the house in the middle is #26, so all the houses to the right of this one would have house numbers too high for what I’m looking for, #22. So I can cross off the house I walked up to, and all the houses to the right because they would have even higher numbers.

Now in a normal world, these houses would all be regular and I could just count my way to the correct one, but I see some empty dirt lots and can’t tell if those will also become homes or are for landscaping or parks. Because I’m not entirely sure what are lots, I am not sure just counting my way down the street to the correct house would work.
So I decide to go with my “pick from the middle” approach again, and that way can at least cross of half of the remaining section of the street based on if the house is numbered too high or low. For this reason, I pick the middle house again of my remaining three houses.

Whaddya know! That’s the correct one. If you want to think of my “treasure hunt algorithm” the end result is pretty good. I wound up only having to walk up to two houses even though there were seven on the street. In terms of how much work I had to do to succeed at this task, my approach meant that the remaining houses to search would have been cut in half each time I walked up to one.
We call the performance when you cut the result set each time logarithmic performance, and after constant time (O(1)) it is as ideal as you can get. Even though you have a result set of 7, the operations you perform could be as low as 2. If you don’t remember much about logarithms from math, that’s honestly fine - all you need to know is that its a GREAT performance for an algorithm to have, because you are cutting your result set down significantly each time.
In Big O language, we write logarithmic performance as O(log n). If you are worried about memorizing the big o descriptor, simply calling it “logarithmic time” in an interview is perfectly ok. And if all you need to know is that logarithmic time means that each pass you cut your results down potentially by half, it is pretty easy to recognize this when you are doing it.
As a side bar: my scavenger hunt example is an example of a binary search algorithm. Not too bad, right? Just pick from the middle over and over. It is a great algorithm to use if you know your results are already in some type of order.
Part 3: Linear time, or O(n)
🍬My friend Jess, on hearing how much work I’ve been putting into these scavenger hunts, takes pity on me. Lucky for me it happens to be October 31st and she assigns me the task of trick or treating! My treasure hunt is to get one piece of candy from every house on Sycamore street.
In this somewhat deliberately messy graphic, you can see how much work this is compared to my last task.

This is what we call in Big O “linear time”, aka a loop, aka simple multiplication. My task is multiplied by the number of houses. On a bigger street, that might be 50 trips. My work increases in a linear fashion based on what street I’m on and how many houses it has.
For big O, linear time is a good algorithm performance in many cases. Not as good as the first two we covered, but normally a code challenge you would receive in an interview is complex enough that there is a reasonable chance loops will be required. We write this as O(n), with “n” being basically what you are multiplying by, or how many loops you’d have to do.
Part 4: Quadratic and cubic time
👿 My last pal, Andrew, is really devious and sets me on the hardest treasure hunt yet. He sets me off on main street and says that for every house on the street, I need to see if I can find an item at each house duplicated at each other house.

Very quickly I’m up to 25 individual tasks, since I have five things to do for each of five houses. You can easily see if we put this to numbers I have 5 x 5 tasks, or 5^2. This is what we call quadratic time.
In programming, this means one thing: nested loops! Each nested layer is adding an exponent. If my friend had said I want you to do this for more than one street, the math becomes something like neighborhood x houses x items, and could easily get into cubic time, or O(n^3), often presented in a third nested loop in real life.
My example is pretty manageable still, but in real life programming we are looking at way larger numbers than this. See how the tasks balloon:
| Base number | Tasks ^2 | Tasks ^ 3 | Tasks ^ 4 |
|---|---|---|---|
| 100 | 10000 | 1000000 | 100000000 |
| 1000 | 1000000 | 1000000000 | 1000000000000 |
| 100000 | 10000000000 | 1000000000000000 | 100000000000000000000 |
| 1000000 | 1000000000000 | 1000000000000000000 | 1000000000000000000000000 |
This is maybe the most important area I can talk to you about. It comes up the most in my job and the most programming. You can quickly see why it gets important fast.
You will notice that that first row where your base number is 100 can quickly get into more operations than that last row, with a starting number of a million, if they are not careful about nested looping. Someone with a data set a million large can have a program doing less work than someone with that data set of 100 records, all depending on how careful they are with nested looping.
Most of the finer points that come up for me in code challenges are if I can get something from a loop to constant time, and then if I can get something from a nested loop to a single loop. (So from cubic time O(n^3) to quadratic time O(n^2)).*
We also have a more general word to represent situations where the exponent is going to be to the power of n: *exponential time (O(2^n)).
Part 5: What this may look like
Let’s say we got the following code challenge.
Given an array of unique integers and a target number, determine if any two
numbers in the array when added together would equal the target. If that
condition is met, return the array position of the two numbers. You cannot
reuse a number at a single index position (So array [4,2] could make
target number 6, but array [3] could not since it would require reusing the
array value at position array[0]).
Example: given array [1, 2, 3, 4, 5, 6] and target number 10, you would return
an answer [3, 5] since at array[3] you have number 4, at array[5] you have
number 6, and added together they make 10.
Example: given array [1,2,4] and target number 50, you would return false
because the condition can not be met.
This is a paraphrase of a Leetcode problem, where below it asks follow up question, “Can you get the time complexity below O(n^2)”. The fact that they ask is a good hint that we might. But for a very new programmer, the obvious way to solve this problem might be something like this. (You can also run the code yourself, here).

You can see that very quickly, the exponential logic catches up with us and we have quite a few individual task calls in this method.
Going back to what I said before about trying to get things into shape where you can take advantage of constant time and linear time, I’m going to use all the same test cases but rewrite this function in a way with better Big O. (BTW, this is illustrative, maybe not precisely how I would solve this problem so don't come for me in the comments lol).
Hashes are really your friend in these kind of problems. So when I iterate over my list, I’m going to make a JavaScript object where each key is what the list item would need to be added with to reach the target number, and the value would be the index I found this item at.
Example: given target number 8 and list [1,2,3,4,9,6] my JS object would
look like this:
{
// first array item is 1, we'd need to find a 7 to make 8, its at index 0
7: 0,
// second array item is 2, we'd need to find a 6 to make 8, its at index 1
// so on and so forth
6: 1,
5: 2,
4: 3,
6: 5
}
So with this object, it means I don’t need to do a nested loop. I can do another regular loop (so linear time) and just check if the current list item is one of the keys for this Javascript object. If it is, I’ve found a matching pair whose sum is the target number. I have saved the index where the first number was located as the key value so I already have that handy, and then can just return the index of the list item I am on in my second loop. You can also play with this code here.

I used the same test cases, and you can see got the same results. But with my nested loop approach the worst performance we saw was > 200 operations, and by not nesting my loops it is only THIRTY! That’s pretty amazing. And it wasn’t too hard, once you get used to thinking this way, to extract the nested loop behavior and find another way.
Visualizing what we’ve learned
One great way to drive home how these perform is to look at a graph of performance, I grabbed this one from this website.

Another fun note
You may wonder when looking at the problem above, is the Big O notation O(2(n)) since we are looping twice? If a loop is O(n), we have done that twice: once to build the JavaScript object, and a second time to process the list again and see if we have two numbers that will sum to the target number.
If you remember me saying that all we care about is loops, mainly, add an asterisk here to say we care about the greatest magnitude of operation present in the problem. What does that mean?
- If you have a loop in your program with performance O(n), and later in the code you have a nested loop with performance O(n^2), we call the big O simply O(n^2) - the exponent is the behavior of the highest order of magnitude in the program, aka the biggest worry. So we drop the lesser one
- If you have a nested loop running at O(n^2), and later on a triple-nested loop running O(n^3), we would simplify that to cubic time. That triple nested loop is the highest order of magnitude thing going on in the code so we simplify to call it O(n^3).
If you think about it, it is more fair to do it this way. Almost everything you will write will have some operations that are O(1), but it is almost never accurate to say the overall performance of a program is O(1). If it has a single loop, that statement will not be accurate.
Conclusion
There are some other types of Big O notation we could cover, but these are the ones I see most commonly and they should get a new programmer pretty far in code challenges. Even if you don’t feel super into math concepts, remembering that loops are the biggest thing you need to worry about is I think easy enough advice that anyone can keep in mind, and it really does help you in keeping performance in mind no matter what level of coding expertise you have.
Also, here are some other great resources:

Top comments (12)
Great post! Not sure if I'm getting something wrong, but in your object example, should't it be like this
Also, in your code what happens if
targetNum < list[i](this would happen in your given example array above[1,2,3,4,9,6]and target number 8) on line 28:I'm not sure if I am getting your question but will return to it later, I'm not sure if I am seeing the behavior you mention running that example though? Screenshot below...will try to remember to revisit this and get back to you later on
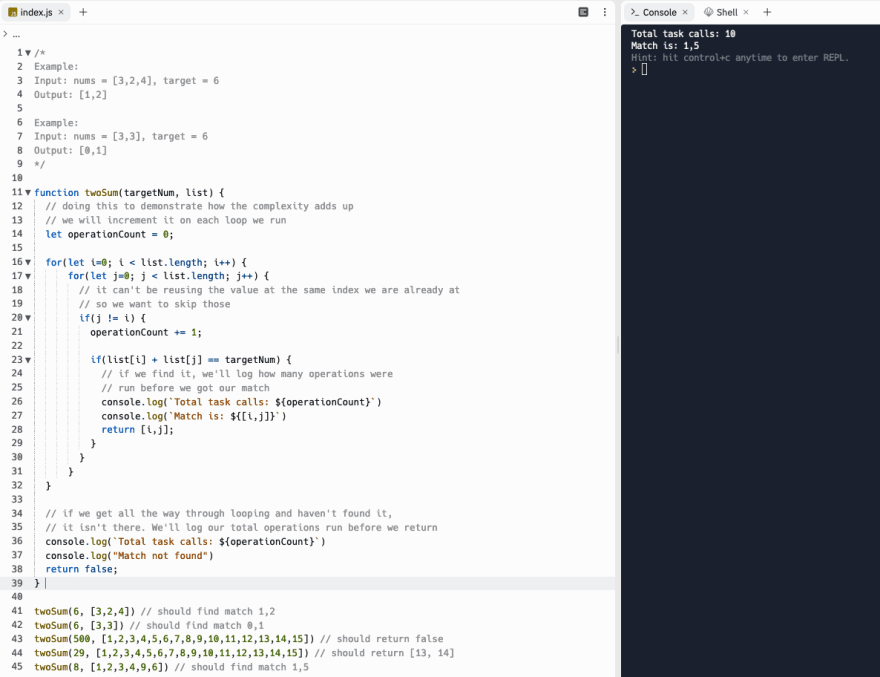
I think it's correct in your code, but wrong in the example you have given. And with my comment regarding line 28 I was referring to the second (optimized) version of the code. So, not the screenshot you posted as a reply, but the next one.
Great article, thanks!
Regarding the code challenge example, keep in mind that the solution with hash map requires
M(n)additional memory, while theO(n^2)solution requiresM(1)memory. So this is a trade-off; there might be cases where it would not be possible to fit all the data in memory, and you would have to use the algorithm that is less effective in terms of CPU.Writing this for new people, I chose to skip memory entirely in introducing the concepts since in my (long) career I have so relatively rarely hit space vs time constraints. Appreciate this point, but definitely was deliberate to skip some finer points in this which was written for pure newbies :) (actually originally wrote it for some mentees who are a few months into learning to code)
Oh my god I love this haha!
@citizen428 I thought of this immediately when I saw the post, you beat me to the punch ;) It's so good.
Really well explained, thanks you
Thanks
Great job! Thanks a lot for this!
Am I missing something? The quadratic example given seems linear to me. If there are 5 tasks in each house, 5 is a constant, so the complexity is O(5N) which is considered equal to O(N). That N happens to be 5 in the example is irrelevant.
It would be O(N^2) if the number of tasks grew with the number of houses (e.g. 1 task per house if there is only one house, but 5 tasks per house if there are 5 houses, i.e. f(1)=1 and f(5)=25).
What are the rule of using Big O notation? كيفية جلب حبيب