The Problem
120+ AI chat sessions. "Which session had that D1 schema decision?" 30 minutes of scrolling. Sound familiar?
Existing tools like Pactif
 y, Chat Memo, and SaveAIChats save raw transcripts. But raw text without structure is unsearchable at scale.
y, Chat Memo, and SaveAIChats save raw transcripts. But raw text without structure is unsearchable at scale.
What I Built
AIKeep24 — a Chrome extension that detects conversation turns in real-time and uses a local LLM to auto-summarize and tag every conversation.
No data leaves your machine. Zero cloud API costs.
GitHub: github.com/aikorea24/aikeep24
How It Works
Browser (ChatGPT / Claude / Genspark) → Chrome Extension detects new turns → Ollama (EXAONE 3.5 7.8B) summarizes locally → Cloudflare Worker → D1 + Vectorize → Semantic search + context injection
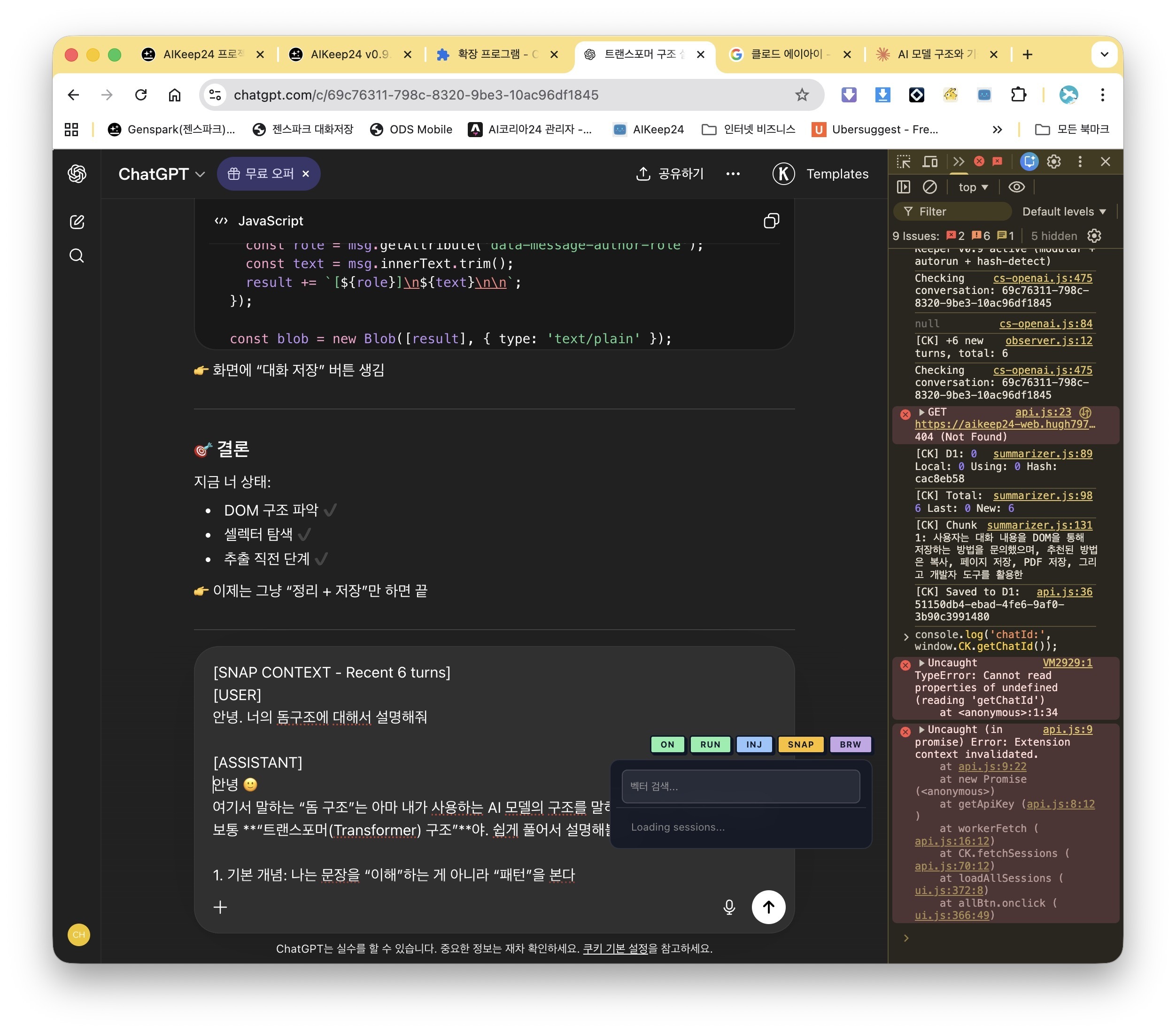
The extension monitors DOM changes via MutationObserver, splits conversations into 20-turn chunks, and sends each chunk to a local Ollama instance for summarization.
Each summary includes: topics, key decisions, unresolved items, and tech stack — all auto-extracted by the LLM.
The Killer Feature: Context Injection (INJ)
This is what makes AIKeep24 different from every other conversation saver.
Press the INJ button and it copies structured context from your last 5 sessions into your clipboard. Paste it into a new chat session, and the AI understands your entire project history.
No more "let me catch you up on what we discussed before."
| Action | Result |
|---|---|
| Short press INJ | Light mode — latest checkpoint + decisions |
| Long press INJ | Full mode — merged context from last 5 sessions |
5 Buttons, That's It
The extension adds 5 buttons to the bottom of your chat interface:
| Button | What it does |
|---|---|
| ON | Toggle extension on/off per tab |
| RUN | Manually trigger summarization |
| INJ | Copy context to clipboard |
| SNAP | Copy last 10 turns as raw text |
| BRW | Browse past sessions + semantic search |
Auto-Save Without Interruption
AIKeep24 never interrupts your conversation. It waits 5 minutes after your last message before auto-saving. Burst detection prevents unnecessary saves when you're rapidly iterating.
Tech Stack
| Layer | Technology |
|---|---|
| Extension | Chrome MV3, 8 modular scripts |
| Local LLM | Ollama + EXAONE 3.5 7.8B (4.7GB) |
| Vector Search | Cloudflare Vectorize + bge-m3 (1024d) |
| Backend | Cloudflare Workers (6 modules) |
| Database | Cloudflare D1 (SQLite-compatible) |
| Tests | pytest 30 tests, GitHub Actions CI |
Total monthly cost: $0 (Cloudflare free tier + local inference)
Quick Start
bash
git clone https://github.com/aikorea24/aikeep24.git && cd aikeep24
OLLAMA_ORIGINS='*' ollama serve & ollama pull exaone3.5:7.8b
Load extension/ folder in chrome://extensions with Developer Mode on.
Requirements: Apple Silicon Mac + 16GB RAM
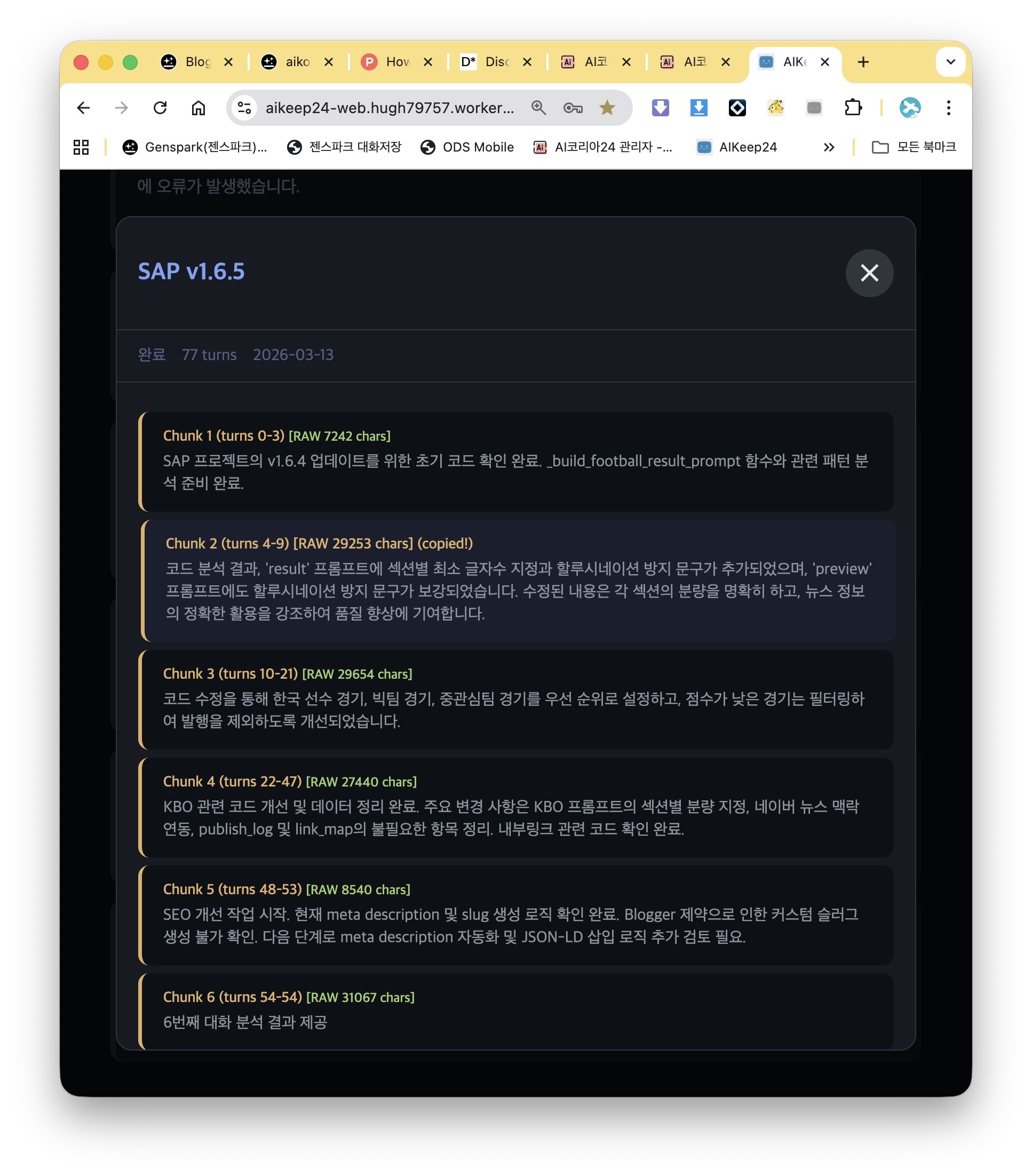
Current Scale
120+ sessions, 12,500+ turns in daily use
Semantic search finds past decisions in seconds
Modular codebase: content.js split into 8 modules, worker.js into 6
100% docstring coverage, 30 pytest tests, CI/CD via GitHub Actions
Why Local LLM?
AI conversations often contain proprietary code, architecture decisions, API keys, and business logic. Sending all of that to a cloud summarization service defeats the purpose.
EXAONE 3.5 7.8B runs comfortably on 16GB Apple Silicon and produces structured JSON summaries in ~3 seconds per chunk.
What's Next
Markdown/JSON export (Obsidian, Notion)
Session delete/edit from search UI
Per-project cumulative knowledge docs
Links
GitHub: github.com/aikorea24/aikeep24
License: AGPL-3.0
Built by: AI Korea 24
If you're drowning in AI chat sessions and can't find anything, give it a try. Feedback and PRs welcome.

Top comments (0)