
This article was originally published on IBM Developer by Soumyaranjan Swain
Prompt tuning is a technique for adapting large language models (LLMs) without needing to fine-tune all the model's parameters. Instead, you add a learnable input (called "prompt parameters") to the model’s input to guide the model toward better performance on a specific task. Prompt tuning is more lightweight and efficient compared to full fine-tuning, as it doesn't modify the core model itself but optimizes only the prompt, which is often much smaller in size.
Why should you use prompt tuning?
Developers and data scientists should use prompt tuning for these two key reasons:
Efficiency: Instead of training billions of parameters (like in full fine-tuning), we only need to optimize the prompt, which typically involves a few thousand parameters. This makes the approach much lighter and faster.
Generalizability: The core model remains unchanged, preserving the general knowledge of the large language model while adapting it for specific tasks with a minimal overhead.
Mathematical explanation of prompt tuning
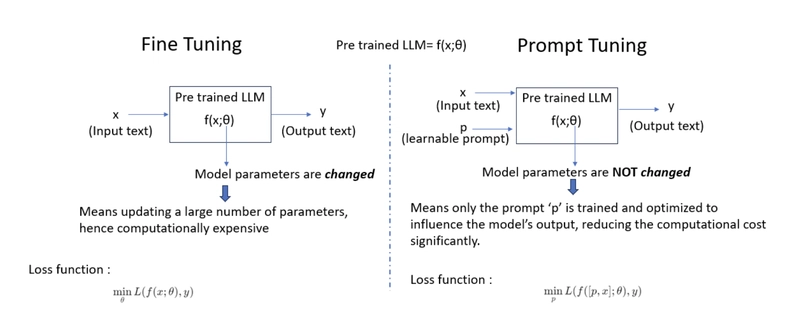
Consider a pre-trained LLM f (x; θ) where:
- x is the input text.
- θ represents the fixed parameters (weights and biases) of the large language model.
- f (x; θ) outputs a probability distribution over the next word or generates a continuation of the input text.
To understand the benefits of prompt tuning, let's compare it with fine tuning. See the following schematic that explains the difference between prompt tuning and fine tuning, from a mathematical point of view.
How prompt tuning really works
Let's dive deeper into how prompt tuning works in the context of a specific example. Suppose we are working with a LLM that is already trained on general language tasks. We want to adapt it for a specific task like sentiment analysis.
Task: Our task in this example is: "Classify the sentiment of a given text as positive or negative."
Input: Our original input text (x) is: "The movie was fantastic."
The learnable prompt (p): This prompt is a learnable set of tokens or embeddings that we will tune to steer the LLM toward the sentiment classification task.The true label (y) is "Positive" or "1".
Objective: To use the large language model to classify the sentiment of the input text, but instead of retraining or fine-tuning the entire model, we will learn an optimal prompt p to adjust the model’s behavior.
Let's now explore this example with a mathematical deep dive.
Click on IBM Developer to read the entire article.

Top comments (0)