
On a previous article on microservices, we went through the best practices I've seen, which doesn't mean those are the only ones, it only means that those are the ones I've seen work for me and the ones I've tried.
This time, I would like to focus on Choreography over Orchestration and Rely on data, not services because I feel I didn't develop enough on these ones and those are really important these are also the two principles that will help you avoid sync calls, which is usually a good practice for inter-service communication.
But first:
Internal REST services, why not?
Don't get me wrong, I love REST, I like building API*s and I enjoy using a well designed one for sure, but for internal communication I prefer to avoid it unless the communication **needs* to be synchronous, there are some cases where you can't help it and it's not always because of a bad design, sometimes the use case itself enforces that restriction.
If you find yourself using network calls most of the time, something will most likely go wrong. Network is not 100% reliable and, always remember, if something can fail, it will fail.
Increases overall response time
Take a look at the following figure:
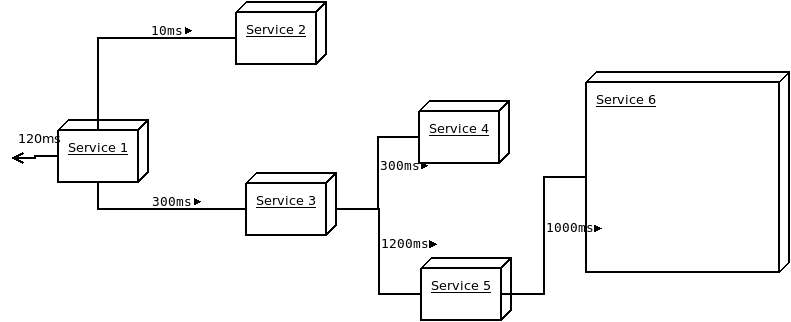
Response times are not taking into account the wait time while the downstream services respond. This means, service 1 queries service 2, it does something and takes 10ms to respond. Also, Service 1 queries Service 3 which queries Service 4 and Service 5. Service 4 does something and takes 300ms to respond and Service 5 queries Service 6 which takes 1000ms to respond, then Service 5 does something and takes another 1200ms to come back to Service 3, which has been waiting 2200ms to get all the data it needs to do some stuff which takes 300ms. By this time, Service 1 has been waiting 2500ms for all the data it needs to do a 120ms something and return back to the upstream caller, which could be another service waiting or the end user.
Note that the above flow paralelizes all the needed downstream calls per service, so in this case, the total response time will be constrained by the slowest call chain. If you were using a stack where doing multiprocessing or async programming is not an easy option, you'll have to add up the response time for all of the downstream calls because in reality the service in question is being blocked while waiting for the network call to finish and, only then, making the second call and blocking until it comes back and so on.
There are several ways you can keep the same setup, you can add several levels of cache in between services, you can add a timeout to the network calls but everything comes at a cost. If you're keeping a synchronous approach to answer certain questions it's because you need your data as fresh as possible, so, the more cache you add the more stale your data could be. You could also add a timeout to your calls but, if one of them times out, you'll fail in responding to the upstream caller and it will look like the system is down.
What if someone is down?
Let imagine Service 6 is down because we had a buggy release.
This means, Service 1 will have to wait 1500ms before returning an error upstream, you can mitigate this with a [circuit breaker (https://www.martinfowler.com/bliki/CircuitBreaker.html) approach or returning a cached response for the query you're trying to answer but, again, unless you really need this to be synchronous, you'd be adding more complexity to an already complex system.
Also, what if it isn't a read operation, what if we're actually writing downstream and the last write fails because of reasons. You'll be half way a transaction and you'll have to deal with it somehow, either queuing that last write and hoping Service 6 comes back soon or rolling back the whole transaction which would mean deleting from the other services and returning an error, there are ways to solve this, but usually it doesn't need to be this hard.
When should I go synchronous?
In my opinion, it will depend on the use case you're implementing and how critical it is to return the exact data at the moment the request was done, usually there's some tolerance to return slightly stale data, but things like credit accounting, warehouse availability or anything that was to do with resources being consumed in real time are good candidates for sync calls and all the complexity they involve.
Choreography vs Orchestration
There's a good analogy in the microservices world and how they handle things happening within the system, let's call those things events.
Let's say there are two types of events, those which make the system do something, for example, in an e-commerce website it could be a user bought something, and those which make the system change its status, for example, update some records in the database o send a request to another service. The first ones, let's call them external events because they're triggered by an external actor, maybe the user or an external system consuming our API, these external events are the ones triggering the second ones, let's call them internal events because it's the system updating itself. So, external events trigger internal events.
Now, there are two ways of handling events, we can either do it via orchestration, where we have a service which acts as the master of the transaction, telling all the other services involved in it what to do, what to update. Just like a Conductor does in an Orchestra, it tells all the other musicians (services) when to play they part, how to play it and so on. The other way is more like a choreography, where given an event every service knows how to handle it and how to react to it, just like dancers who know how and where to move or what do do when a certain part of the song is played.
Good architectures are a mix of both approaches and good architects know when to use either of those depending on the business needs and the use case they're modeling. Unfortunately there's no recipe to decide, gaining experience designing systems and making mistakes are the only way to learn, although reading about others experience, having clear concepts on how distributed systems and networks work and a good understanding of the problem at hand we're solving are a good starting point.
Rely on data, not services
We spoke about low coupling and high cohesion in microservices in a previous article, relying on a service to be up in order for some other service to be able to do what it's supposed to do is some form of coupling, you are letting an independent system fail because another is feeling unwell.
For services to be independent, every service should have a copy of the data they need to answer at least basic queries, this doesn't mean you'll directly update the copies, you need to define which service is going to be your source of truth for a specific piece of data and perform all the write operations for it to that service and then, somehow, update the copies. You can rely on internal events to do this, every time an external event triggers an update on the source of truth for a give piece of data, you can fire up an internal event to make the services keeping a copy update their local copies.
By doing this you can still serve a read-only version of the data for some use cases even if the source of truth is down, if it's, for example, an e-commerce and the source of truth for the catalog is, for example, the Inventory Service, you can still serve the catalog even though the users won't be able to purchase anything, they still can save them to their wishlist and browse the website, this lets you gracefully degrade your system if there are problems with some services, you just show an error message or hide the options or have alternate workflows until the systems supporting the degraded use case are back up and running.
What if a service is down and misses some updates from the source of truth?, well, depending on how you propagate the updates, you can do several things. You can use a queuing system like ZeroMQ or RabbitMQ to propagate the updates, so, if a service is down, the updates will be waiting on the queue to be consumed once the service is up, if you're using HTTP calls, you can have your worker retry the failed requests after a back-off time or write the payload to a given location so, when the other service comes up, an init script checks that location, reads whatever is there and marks those messages as consumed, there are multiple ways to deal with this problem, most of them will depend on the technology you're using.
Eventual consistency
When you deal with distributed systems and distributed information, chances are, some copies will be stalled for a period of time, this means, information will always be flowing through the pipes of your system, the only way you will have total consistency is if you stop writing and wait some time. Even in monolithic systems, what you show to the user is stale most of the time, let's say, for example, a website listing used articles for sale, when the search page is served to the user, depending on the traffic, there will be probably 10ths or hundreds of new articles the user won't see unless they refresh the page or we have a pushing mechanism in place. So, how important is it really to show the most updated information available to the user?, truth is, is not that critical in most cases.
For building reports though, you should always query from your sources of truth, this could be tricky on a distributed system where your source of truth varies depending on the information you're looking for and it's not a single database where you can run a SQL query and join everything together. You could rely also on internal events to build a reporting database while the relevant events are happening instead of querying everything when a report is requested, this way you'll always have relevant business data to produce reports on top of.
Conclusion
There's no silver bullet to solve the problems that come with distributed computing, however, there are strategies to help you discover the best way to deal with certain problems for your specific use case, try to use choreography where possible and orchestrate the flows that need to be completely synchronous, always try to find the easiest solution, keep in mind that sometimes the easiest way to solve a problem is the hardest to implement, but benefits will be seen in the future, when you need to debug a failure or scale, or even extend your system with more features or plugging more microservices in.
Also, always prefer choreography and async communication when possible instead of orchestration and sync calls between services, this doesn't mean you should avoid it at all cost as there are use cases that need that approach. A good architect knows that the best way to solve a problem is not following strictly one and only one approach, it's combining different concepts and ways around it and adapting them to the specific problem to achieve an efficient and elegant solution.
Recommended readings
- Building Microservices by Sam Newman
- Circuit Breaker by Martin Fowler
- Introduction to Microservices by Oliver Wolf
- Why Microservices Should be Event Driven by Christian Posta
- Event command transformation in microservice architectures and DDD by Bernd Rücker
- My take on Microservices by me :-)

Top comments (0)