
A recent paper from Meta AI Research shows that their new 10 billion parameter model trained using self-supervised learning breaks new ground in robustness and fairness.
In spring 2021 Meta AI (former Facebook AI) published SEER (Self-supervised Pretraining of Visual Features in the Wild). SEER showed that training models using self-supervision works well on large-scale uncurated datasets and their model reached state-of-the-art when it was published.
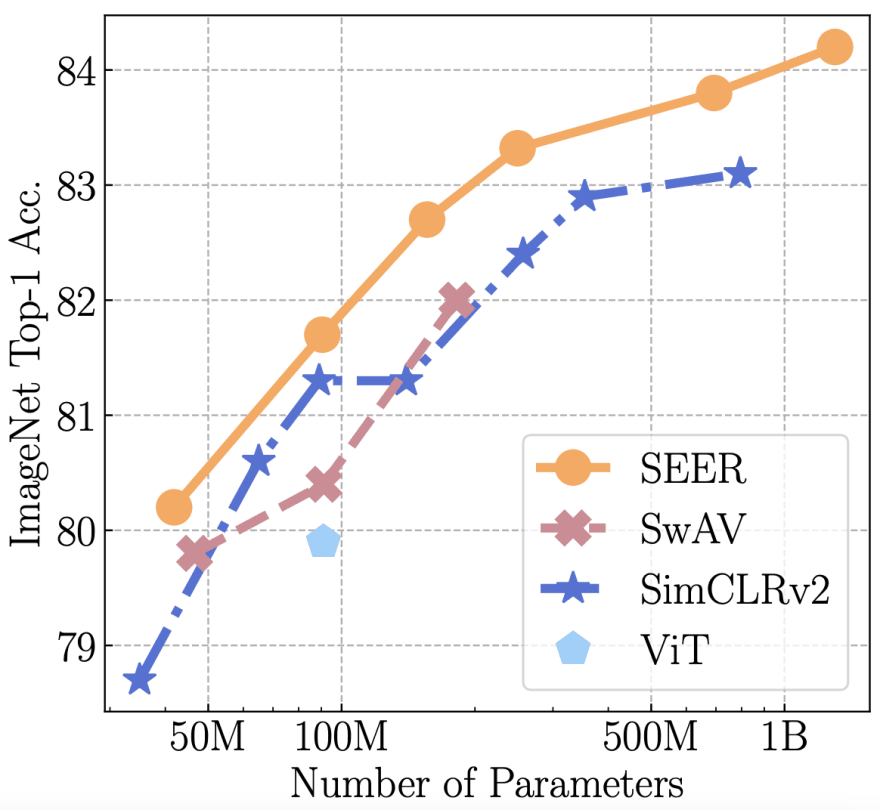
The model has been pre-trained on 1 billion random and uncurated images from Instagram. The accompanying blog post created some noise around the model as it set the ground for going further with larger models and larger datasets using self-supervised learning: https://ai.facebook.com/blog/seer-the-start-of-a-more-powerful-flexible-and-accessible-era-for-computer-vision/
In contrast to supervised learning, the approach of self-supervised learning does not require vasts amounts of labeled datasets, therefore significantly reducing the costs.
Basically, the two main ingredients-lots of data and lots of compute-are enough, as shown in this paper. Besides the independence of labeled data, there are further advantages in using self-supervised learning we talked about in another post.
SEER is more robust and fair
In this post, we’re more interested in the new follow-up paper to the initial SEER paper. The new paper has been published in late February 2022:
- Vision Models Are More Robust And Fair When Pretrained On Uncurated Images Without Supervision, 2022
The original SEER paper showed that larger datasets combined with self-supervised pre-training result in higher model accuracy on downstream tasks such as ImageNet. The new paper takes this one step further and investigates what happens if we train even larger models with respect to robustness and fairness.
Model robustness and fairness have recently gained more attention in the ML community.
With robustness, we are interested in how reliable the model works when facing changes in its input data distribution. This is a common problem as models once deployed might face scenarios they have never seen during training.
Model fairness focuses on the evaluation of models towards gender, geographical and other diversity.
But what exactly is fairness and how can we measure it?
Previous work in Fairness Indicators
Although Fairness in ML is an older research area the field has recently gained lots of interest. For example, the paper Fairness Indicators for Systematic Assessments of Visual Feature Extractors, 2022 introduces three rather simple indicators one can use to evaluate model fairness.
The approach is to fine-tune (think about transfer learning) a trained backbone to make predictions across three indicators:
- harmful mislabeling of images of people by training a classifier Harmful mislabeling happens when a model associates attributes like “crime” or non-human attributes like “ape” or “puppet” with a human. Apart from being low overall, the mislabeling rate should be independent of gender or skin color. If however, people with a certain gender or skin color are mislabeled more often than others, the model is unfair.
- geographical disparity in object recognition by training a classifier How well do we recognize objects all around the world? Common objects like chairs/ streets/ houses look different across the globe.
- disparities in learned visual representations of social memberships of people by using similarity search to retrieve similar examples If we do similarity lookup of people of different skintone do we also get similar skintones in the set of nearest neighbors?
In their paper, three different training methodologies and datasets are used for the evaluation.
- Supervised training on ImageNet
- Weakly-supervised training on filtered Instagram data
- Self-Supervised training on ImageNet or uncurated Instagram data (SEER model)
All three training paradigms use the same model architecture. A RegNetY-128 backbone with 700M parameters.
The results of the evaluation show that training models with less supervision seem to improve the fairness of the trained models:
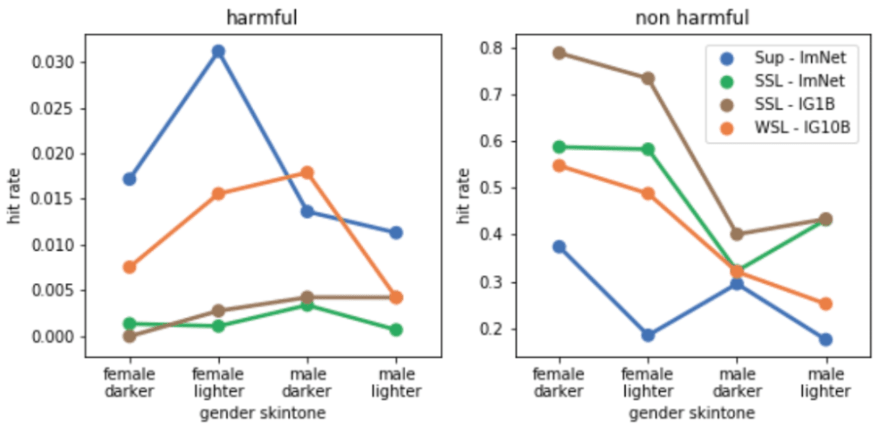
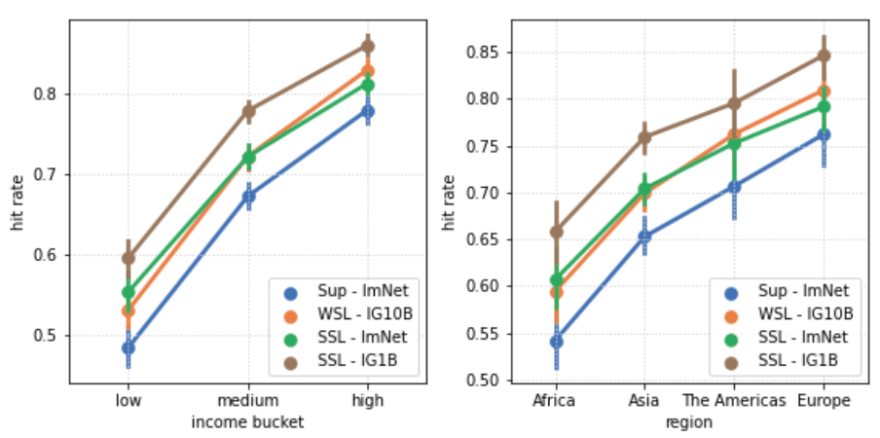
Going Deeper into Fairness Evaluation
Now, how does the new SEER paper build on top of the Fairness Indicators paper we just discussed?
There are two main additions:
- A larger model (A RegNetY-10B model with 10B parameters, over 14x times more)
- Evaluation across 50+ benchmarks
In order to fit the model onto the GPUs tricks like model sharding, Fully Sharded Data Parallel (FSDP), and Activation Checkpointing are used. Finally, the authors used a batch size of 7,936 across 496 NVIDIA A100 GPUs. Note that according to the paper only 1 Epoch is used for the self-supervised pertaining. On ImageNet these models are often trained for 800 epochs or more. This means that even though the dataset is almost 1'000 times larger the images seen during training are comparable.
Since the authors used a very large dataset (1 Billion images) they argue that they can also scale the model size: We scale our model size to dense 10 billion parameters to avoid underfitting on a large data size.
Results
The paper is full of interesting plots and tables. We will just highlight a few of them in this post. For more information, please have a look at the paper.
Fairness
This benchmark is the one we looked at previously when talking about the Fairness Indicators paper. If you look at the table you find different genders and skintones as well as different age groups. Interesting here is that all SSL pre-trained models perform much better than the supervised counterpart.
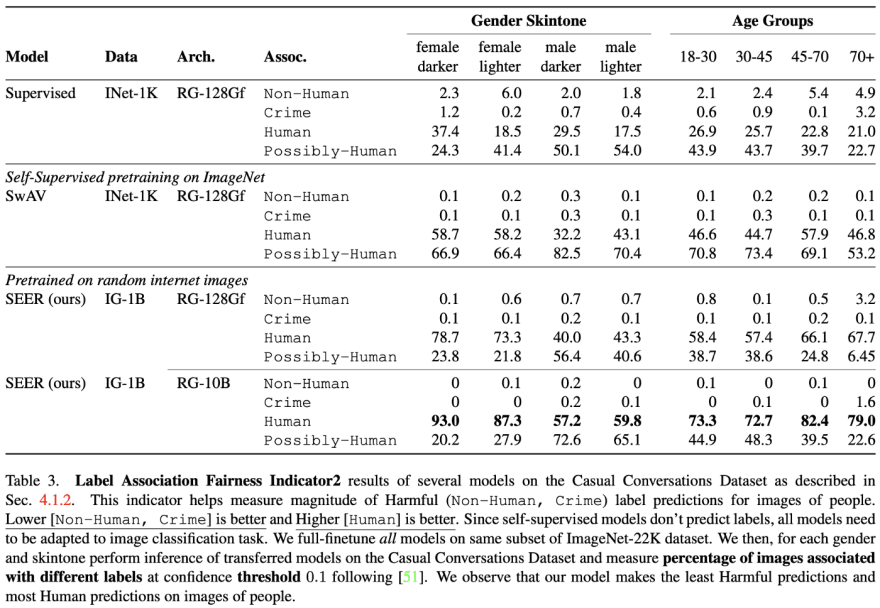
Out-of-distribution Performance
Out-of-distribution or commonly called robustness towards data distribution shifts is a common problem in ML. A model trained on a set of images might find slightly different images once deployed.
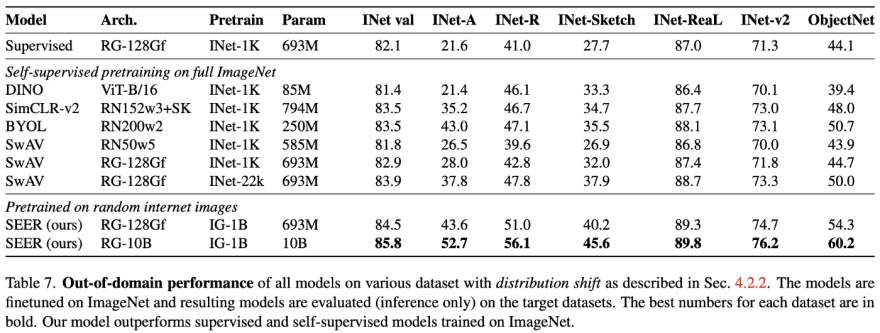
Conclusion
While self-supervised learning (SSL) is still in its infancy the research direction looks very promising. Not having to rely on large and fully labeled datasets allows training models that are more robust to data distribution shifts (data drifts) and are fairer than their supervised counterparts. The new paper shows very interesting insights.
If you’re interested in self-supervised learning and want to try it out yourself you can check out our open-source repository for self-supervised learning.
We’re using self-supervised learning at Lightly from day one as our initial experiments showed its benefits when doing large-scale data curation. We’re super happy that new research papers support our approach and we hope that we can help curate datasets to allow for less biased datasets and more fair models.
Igor, co-founder
Lightly.ai

Top comments (0)