One of the golden rules in machine learning is to split your dataset into train, validation, and test set. Learn how to bypass the most common caveats!
The reason we do that is very simple. If we would not split the data into different sets the model would be evaluated on the same data it has seen during training. We therefore could run into problems such as overfitting without even knowing it.
Back before using deep learning models we often used three different sets.
- A train set is used for training the model
- A validation set that is used to evaluate the model during the training process
- A test set that is used to evaluate the final model accuracy before deployment
How do we use the train, validation, and test set?
Usually, we use the different sets as follows:
- We split the dataset randomly into three subsets called the train, validation, and test set. Splits could be 60/20/20 or 70/20/10 or any other ratio you desire.
- We train a model using the train set.
- During the training process, we evaluate the model on the validation set.
- If we are not happy with the results we can change the hyperparameters or pick another model and go again to step 2
- Finally, once we’re happy with the results on the validation set we can evaluate our model on the test set.
- If we’re happy with the results we can now again train our model on the train and validation set combined using last the hyperparameters we derived.
- We can again evaluate the model accuracy on the test set and if we’re happy deploy the model.
Most ML frameworks provide built-in methods for random train/ test splits of a dataset. The most well-known example is the train_test_split function of scikit-learn.
Are there any issues when using a very small dataset?
Yes, this could be a problem. With very small datasets the test set will be tiny and therefore a single wrong prediction has a strong impact on the test accuracy. Fortunately, there is a way to work around this problem.
The solution to this problem is called cross-validation. We essentially create partitions of our dataset as shown in the image below. We always hold out a set for testing and use all the other data for training. Finally, we gather and average all the results from the testing sets. We essentially trained k models and using this trick managed to get statistics of evaluating the model on the full dataset (as every sample has been part of one of the k test sets).
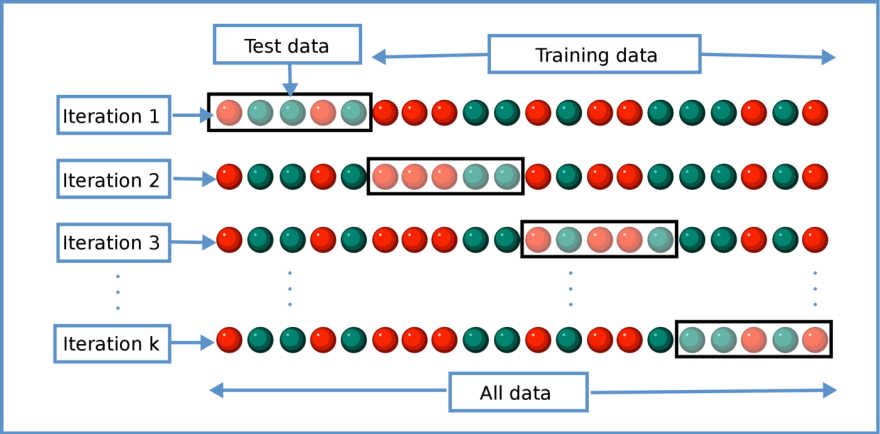
This approach is barely used in recent deep learning methods as it’s super expensive to train a model k times.
With the rise of deep learning and the massive increase in dataset sizes, the need for techniques such as cross-validation or having a separate validation set has diminished. One reason for this is that experiments are very expensive and take a long time. Another one is that due to the large datasets and nature of most deep learning methods the models got less affected by overfitting.
Overfitting is still a problem in deep learning. But overfitting to 50 samples with 10 features happens faster than overfitting to 100k images with millions of pixels
One could argue that researchers and practitioners got lazy/ sloppy. It would be interesting to see any recent paper investigating such effects again. For example, it could be that researchers in the past years have heavily overfitted their models to the test set of ImageNet as there has been an ongoing struggle to improve it and become state-of-the-art.
How should I pick my train, validation, and test set?
Naively, one could just manually split the dataset into three chunks. The problem with this approach is that we humans are very biased and this bias would get introduced into the three sets.
In academia, we learn that we should pick them randomly. A random split into the three sets guarantees that all three sets follow the same statistical distribution. And that’s what we want since ML is all about statistics.
Deriving the three sets from completely different distributions would yield some unwanted results. There is not much value in training a model on pictures of cats if we want to use it to classify flowers.

However, the underlying assumption of a random split is that the initial dataset already matches the statistical distribution of the problem we want to solve. That would mean that for problems such as autonomous driving the assumption is that our dataset covers all sorts of cities, weather conditions, vehicles, seasons of the year, special situations, etc.
As you might think this assumption is actually not valid for most practical deep learning applications. Whenever we collect data using sensors in an uncontrolled environment we might not have the desired data distribution.
But that’s bad. What am I supposed to do if I’m not able to collect a representative dataset of the problem I try to solve?
What you’re looking for is the research area around finding and dealing with domain gaps, distributional shifts, or data drift. All these terms have their own specific definition. I’m listing them here so you can search for the relevant problems easily.
With a domain, we refer to the data domain, as the source and type of the data we use. There are three ways to move forward:
- Solve the data gap by collecting more representative data
- Use data curation methods to make the data already collected more representative
- Focus on building a robust enough model to handle such domain gaps
The latter approach is focusing on building models for out-of-distribution tasks.
Picking a train test split for out-of-distribution tasks
In machine learning, we refer to out-of-distribution whenever our model has to perform well in a situation where the new input data is from a different distribution than the training data. Going back to our autonomous driving example from before, we could say that for a model that has only been trained on sunny California weather, doing predictions in Europe is out of distribution.
Now, how should we do the split of the dataset for such a task?
Since we collected the data using different sensors we also might have additional information about the source for each of the samples (a sample could be an image, lidar frame, video, etc.).
We can solve this problem by splitting the dataset in the following way:
- we train on a set of data from cities in list A
- and evaluate the model on a set of data from cities in list B
There is a great article from Yandex research about their new dataset to tackle distributional shifts in datasets.
Things that could go wrong
The validation set and test set accuracy differ a lot
You very likely overfitted your model to the validation set or validation and test set are very different. But how?
You likely did several iterations of tweaking the parameters to squeeze out the last bit of accuracy your model can yield on the validation set. The validation set is no longer fulfilling its purpose. At this point, you should relax some of your hyperparameters or introduce regularization methods.
After deriving my final hyperparameters I want to retrain my model on the full dataset (train + validation + test) before shipping
No, don’t do this. The hyperparameters have been tuned for the train (or maybe the train + validation) set and might yield a different result when used for the full dataset.
Furthermore, you won’t be able to answer the question anymore of how good your model really performs as the test set no longer exists.
I have a video dataset and want to split the frames randomly into train, validation, and test set
Since video frames are very likely highly correlated (e.g. two frames next to each other almost look the same) this is a bad idea. It’s almost the same as if we would evaluate the model on the training data. Instead, you should split the dataset across videos (e.g. videos 1,3,5 are used for training and video 2,4 for validation). You can again use a random train test split but this time on the video level instead of the frame level.
Igor, co-founder
Lightly.ai
This blog post has originally been published here: https://www.lightly.ai/post/train-test-split-in-deep-learning

Top comments (0)