
Netflix uses Netflix Recommendation Engine to show user content based on what they watch and their likes. Netflix uses a deep learning algorithm to understand the users likes and dislikes and then use this data and evaluate what content the user may like and recommend it to them.
Recommender Pipeline:
- Pre-processing
- Hyperparameter tuning
- Model training and prediction
- Post-processing
- Evaluation
Data=>Machine Learning model=>Predictions
User Preferences=>Recommender System=>Recommendations
Collaborative filtering: Similar users like similar things.
Content based filtering: User and item features.
- Pre-processing:
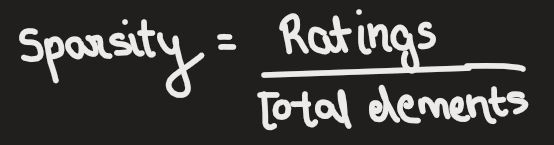
Let’s assume that we have data set that is dense enough to proceed.
Normalization:
Optimists = rate everything 4 or 5
Pessimists=rate everything 1 or 2
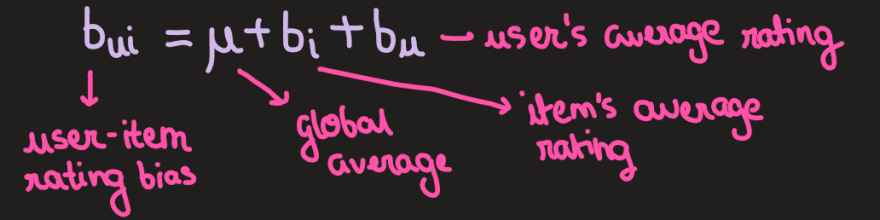
Need to normalize ratings by accounting for user and item bias.
Mean normalization:
subtract bi from each user’s rating for given item i.
Pick a Model:
Matrix Factorization:
Factorize the user-item matrix to get 2 latent factor matrices:
- User-factor matrix
- Item factor matrix
Missing ratings are predicted from the inner product of these two factor matrices.
 Algorithms that perform matrix factorization:
Algorithms that perform matrix factorization: - Alternating Least Squares (ALS)
- Stochastic Gradient Descent (SGD)
- Singular Value Decomposition (SVD)
- Pick an Evaluation Metric:
Precision at K:
Looks at the top K recommendations and calculates what proportion of those recommendations were relevant to a user. We will be focusing on the top 10 recommendations.
- Hyperparameter tuning
Alternating Least Square’s Hyperparameters
- K (# of factors)
- Lambda (regularization parameter)
Goal: Find the hyperparameter that give the best precision at 10.
Grid Search: Iterates over a number set of combinations of K and lambda. So, we basically run the model and evaluate it for each combination of lambda and K and see which of them gives us the best precision at 10.
Random Search: It just randomly selects values of lambda and K and evaluates that several times. This approach is less exhaustive and more effective than grid search.
Sequential Model-Based Optimization: It’s basically a smarter way of tuning your hyper parameters because it takes into consideration the results of your previous iterations when you sample hyper parameters and your current iteration.
You can consider using tools like sidekick optimize, hyper opt or metric optimization engine which was developed by Yelp.
- Model Training
We can train this model with these optimal hyperparameters to get our predicted ratings and we can use these results to generate our recommendations.
- Post-processing
Sort predicted ratings and get top N.
Filter out items that a user has already purchased, watched, interacted with.
Item-item recommendations
-Use a similarity metric (e.g., cosine similarity)
-“Because you watched Movie X”
- Evaluation
If you can do A|B testing or usability testing where you get actual feedback from real users, that is the best signal that you have a good recommender but in many cases that’s not possible. So, we’re going to have to do offline evaluation.
In traditional ML we split our dataset in half to create a training set and a validation set but this isn’t work for recommender models because the model won’t work if you train all your data on a separate user population then the validation set. So, for recommenders we actually mask random interactions in our matrix and use this as our training set. So, we pretend that we don’t know a user’s rating of a movie, but we actually do and we can compare the predicted rating with the actual rating and that’s our way of calculating precision at 10 or any metric we want in this case.

Precision and recall are very popular metrics for recommender systems and they’re both information retrieval metrics.

Top comments (0)