Combining the "Thinking Power" of AI Agents with the "Execution Power" of Automation Tools
Introduction: AI Transformation in Consulting
In a recent project, I explored how to combine the decision-making capabilities of AI agents with the system integration capabilities of the n8n workflow automation platform to build a complex multi-agent AI system for automating consulting business processes. This combination provides valuable experience for teams considering similar solutions.
Project Background
A consulting firm needed to automate their customer service, document processing, and application tracking workflows. They faced challenges including:
- Providing 24/7 customer support via WhatsApp
- Automatically parsing and understanding business documents
- Tracking application status in real-time and notifying clients
- Providing unified data views for administrators
Initially, this seemed to require building from scratch using Langchain or a custom Python framework. However, I decided to explore a hybrid approach: combining the "thinking ability" of AI agents with the "system connection ability" of n8n to see if this combination could support such a complex application.
System Architecture: Perfect Combination of Thinking and Execution
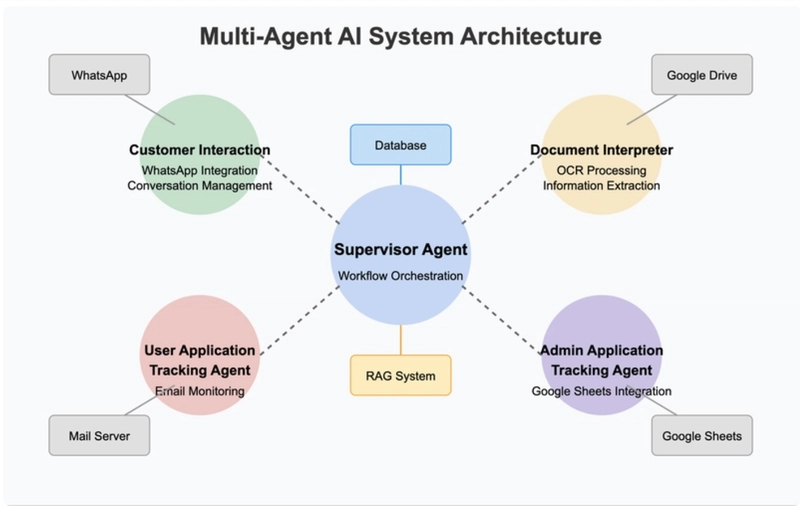
The core concept of this system is separating "thinking" from "execution":
"Brain" Layer - AI Agents
The system contains five specialized AI agents, each responsible for a specific functional area and coordinated through a central supervisory agent:
- Customer Interaction Agent - Interacts directly with customers via WhatsApp
- Document Interpretation Agent - Processes and analyzes uploaded business documents
- User Application Tracking Agent - Monitors application status and notifies customers
- Admin Application Tracking Agent - Provides data views for administrators
- Supervisory Agent - Coordinates the work of other agents
"Arm" Layer - n8n Automation Workflows
n8n workflows act as the system's "arms," responsible for:
- Data exchange with external systems (WhatsApp, Google Drive, email, etc.)
- Handling authentication and API calls
- Managing data flow and state persistence
- Executing specific operations based on agent decisions
This architecture allows us to fully leverage the strengths of both technologies: the decision-making capabilities of AI agents and the system integration capabilities of n8n.
Technical Implementation: From Simple to Complex
Customer Interaction Agent: Intelligent Conversation Management
This agent handles conversations with customers via WhatsApp, answering questions and collecting information. While it appears to be simple API calls on the surface, the actual implementation is much more complex.
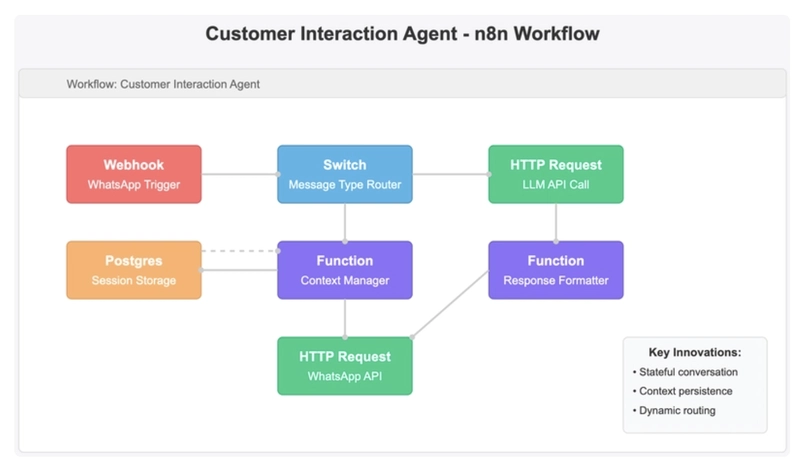
Basic Implementation:
- Using n8n's WhatsApp Business API node to receive and send messages
- Setting up basic conditional branches to handle different types of messages
Advanced Challenges and Solutions:
n8n workflows are inherently stateless, which is a challenge for conversation systems that need to remember context. I solved this by creating a state management system:
# Custom Code Node - Conversation State Management
# Retrieve conversation history and user preferences
cur.execute("""
SELECT
conversation_history,
user_preferences,
business_context,
decision_points
FROM user_sessions
WHERE session_id = %s
ORDER BY timestamp DESC
LIMIT 1
""", (session_id,))
data = cur.fetchone()
# Build enhanced context
def build_hierarchical_context(data):
# Complex context building logic
history = json.loads(data[0])
preferences = json.loads(data[1])
business_context = json.loads(data[2])
# Combine multi-level context
return {
"recent_interactions": history[-5:],
"user_preferences": preferences,
"business_insights": extract_key_insights(business_context)
}
return {
"json": {
"enhancedContext": build_hierarchical_context(data),
"conversationState": determine_dialogue_state(data),
"nextActionPredictions": predict_user_intent(data)
}
}
This approach not only maintains conversation state but also implements conversation intent prediction and context enhancement, making interactions more natural. In this example, n8n handles the connection with WhatsApp (arm), while the AI agent handles conversation understanding and response generation (brain).
RAG System: Improving AI Response Accuracy
Retrieval-Augmented Generation (RAG) is a key component of the system, enabling AI to provide accurate answers based on company documents. Implementing this functionality was one of the most technically challenging parts of the project.
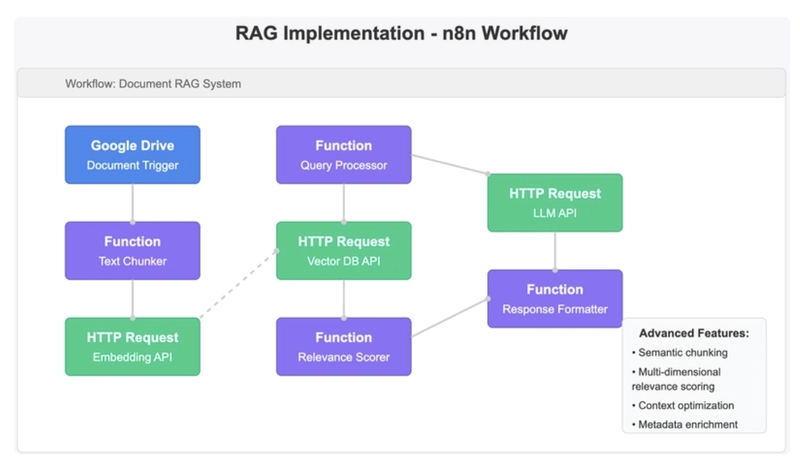
Basic Implementation:
- Retrieving documents from Google Drive
- Generating embeddings via HTTP requests to OpenAI API
- Storing embeddings and document chunks
Advanced Challenges and Solutions:
n8n doesn't have built-in vector storage nodes, so I implemented complex relevance scoring and retrieval using Python code:
# Relevance scoring logic in RAG implementation
def evaluate_relevance(query, documents, user_context):
results = []
for doc in documents:
# Calculate semantic similarity
semantic_score = cosine_similarity(
np.array(query["embedding"]),
np.array(doc["embedding"])
)
# Evaluate business relevance
business_context_score = evaluate_business_alignment(
doc,
user_context["businessType"]
)
# Calculate recency weight
doc_time = datetime.fromisoformat(doc["timestamp"])
current_time = datetime.now()
time_diff = (current_time - doc_time).days
recency_score = 1.0 / (1.0 + 0.1 * time_diff)
# Weighted combination scoring
relevance_score = (
semantic_score * 0.6 +
business_context_score * 0.3 +
recency_score * 0.1
)
results.append({
**doc,
"relevanceScore": relevance_score
})
# Sort by relevance
return sorted(results, key=lambda x: x["relevanceScore"], reverse=True)
In this implementation, n8n is responsible for document retrieval and data flow management (arm), while the AI agent is responsible for semantic understanding and relevance assessment (brain). This division of labor allows the system to efficiently handle complex knowledge retrieval tasks.
Multi-Agent Coordination: Core Challenge
n8n workflows are typically isolated from each other, which is a major challenge for multi-agent systems that need to work together. I designed an innovative "supervisory agent" architecture to coordinate the work of multiple agents.
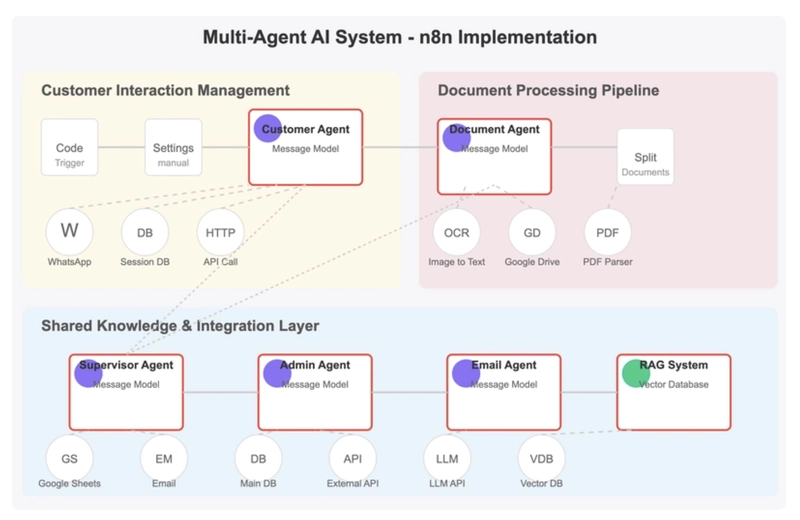
Basic Implementation:
- Using a database to store shared state
- Creating triggers to pass information between agents
Advanced Challenges and Solutions:
I implemented a task orchestration system to manage collaboration between agents:
# Supervisory Agent - Task Allocation and Coordination
# Create new task
def create_task(agent_type, priority, data):
task_id = str(uuid.uuid4())
task = {
"id": task_id,
"agent": agent_type,
"priority": priority,
"status": "pending",
"created_at": datetime.now().isoformat(),
"data": data
}
# Add to appropriate queue
r.lpush(f"tasks:{agent_type}", json.dumps(task))
r.set(f"task:{task_id}", json.dumps(task))
return task_id
# Assign tasks based on current state
current_state = items[0]["json"]["systemState"]
user_request = items[0]["json"]["userRequest"]
if "document" in user_request:
# Assign to document interpreter agent
task_id = create_task("document_interpreter", 2, {
"document_url": user_request["document"],
"user_id": current_state["userId"]
})
# Notify customer interaction agent
create_task("customer_interaction", 1, {
"message": "Your document is being processed, please wait...",
"user_id": current_state["userId"],
"related_task": task_id
})
# Return updated system state
return {
"json": {
"systemState": {
**current_state,
"pendingTasks": get_pending_tasks(current_state["userId"])
}
}
}
In this architecture, the supervisory agent acts as the "brain of brains", deciding which agent should handle which tasks, while n8n workflows act as the "nervous system", ensuring these decisions are correctly communicated and executed. This allows the system to handle complex business scenarios, such as automatically coordinating the work of multiple agents after a document upload.
Practical Challenges and Solutions
Challenge 1: Handling High Concurrency
n8n is not designed for high concurrency loads, but the consulting system needs to serve multiple clients simultaneously.
Solution: I implemented a custom queue management system and load balancing mechanism:
# Request Queue Management System
# Add request to queue
def add_to_queue(request_id, priority, payload):
r.rpush(queue_key, json.dumps({
"requestId": request_id,
"priority": priority,
"timestamp": time.time(),
"payload": payload
}))
# Worker implementation
def worker():
while True:
# Block until next request
next_request = r.blpop(queue_key, 0)
request_data = json.loads(next_request[1])
# Process request
process_request(request_data)
# Simple rate limiting
time.sleep(0.1)
This approach demonstrates how to use n8n as a frontend interface while delegating high-load processing to specially designed backend systems.
Challenge 2: Implementing Complex Business Logic
Consulting business involves complex decision trees and business rules that go beyond the capabilities of n8n's visual condition nodes.
Solution: I created a business rules engine that uses configuration files to define complex rules:
# Business Rules Engine Example
# Load business rules
with open('./rules/business_structure.json', 'r') as file:
business_rules = json.load(file)
user_profile = items[0]["json"]["userProfile"]
industry_type = user_profile["industry"]
# Condition evaluation function
def evaluate_condition(condition, profile):
if condition["type"] == "equals":
return profile[condition["field"]] == condition["value"]
elif condition["type"] == "contains":
return condition["value"] in profile[condition["field"]]
elif condition["type"] == "greater_than":
return profile[condition["field"]] > condition["value"]
# More condition types...
# Find applicable rules
applicable_rules = [
rule for rule in business_rules
if evaluate_condition(rule["condition"], user_profile)
]
# Generate personalized recommendations
recommendations = []
for rule in applicable_rules:
# Recommendation generation logic
This example shows how to separate complex business logic (brain) from n8n workflow execution (arm), making the system easier to maintain and extend.
Conclusion: Perfect Combination of Thinking and Execution
This project demonstrates that building enterprise-grade AI systems doesn't have to be limited to a single technology stack. By combining the decision-making capabilities of AI agents ("brain") with the system integration capabilities of n8n ("arm"), we can create a system that is both intelligent and practical.
The main advantages of this approach include:
- Separation of Expertise - Each technology focuses on what it does best
- Rapid Integration - Leverage n8n's existing connectors to quickly interface with business systems
- Flexibility - Components can be replaced or upgraded as needed
- Maintainability - Business logic is separated from system integration, making maintenance simpler
For teams considering building similar systems, I recommend:
- Clearly distinguish between tasks that require "thinking" and tasks that require "execution"
- Choose the most appropriate tool for each type of task
- Design good interfaces for seamless collaboration between the two systems
With this approach, even small teams can build complex, powerful AI systems that deliver real business value.

Top comments (3)
Learned a lot, thanks for sharing James. n8n with AI agents sounds like a powerful combo for automating complex consulting workflows.
If you're considering n8n, the self-hosted option gives you full control over your data and workflows. Great for businesses with compliance requirements.
n8n is excellent for complex workflows, especially when you need self-hosting for data privacy. The learning curve is steeper than Zapier but the flexibility is worth it for advanced use cases.