
Hi fellow Dev,
In this article, I will walk you through the concept behind building a machine learning agent, which learns via reinforcement learning.
I have built an online demo, which you can tweak the agent's behaviour and training parameters. You can play against the agent.
The source code is also available for anyone who is interested to tweak it. Feel free to fork it, I am also glad to work with anyone who is interested to build more JavaScript demos in this repo.
Follow me if you are interested in JavaScript demos with machine learning application.
I hope you will enjoy this article and demo as much as I do building it. ❤️
Intuition
After a long day at work, you are deciding between 2 choices: to head home and write a Medium article or hang out with friends at a bar. If you choose to hang out with friends, your friends will make you feel happy; whereas heading home to write an article, you’ll end up feeling tired after a long day at work. In this example, enjoying yourself is a reward and feeling tired is viewed as a negative reward, so why write articles?
Because in life, we don’t just think about immediate rewards; we plan a course of actions to determine the possible future rewards that may follow. Perhaps writing an article may brush up your understanding of a particular topic really well, get recognised and ultimately lands you that dream job you’ve always wanted. In this scenario, getting your dream job is a delayed reward from a list of actions you took, then we want to assign some value for being at those states (for example “going home and write an article”). In order to determine the value of a state, we call this the “value function”.
So how do we learn from our past? Let’s say you made some great decisions and are in the best state of your life. Now look back at the various decisions you’ve made to reach this stage: what do you attribute your success to? What are the previous states that led you to this success? What are the actions you did in the past that led you to this state of receiving this reward? How is the action you are doing now related to the potential reward you may receive in the future?
Reward vs Value Function
A reward is immediate. It can be scoring points in a game for collecting coins, winning a match of tic-tac-toe or securing your dream job. This reward is what you (or the agent) wants to acquire.
In order to acquire the reward, the value function is an efficient way to determine the value of being in a state. Denoted by V(s), this value function measures potential future rewards we may get from being in this state s.
Define the Value Function
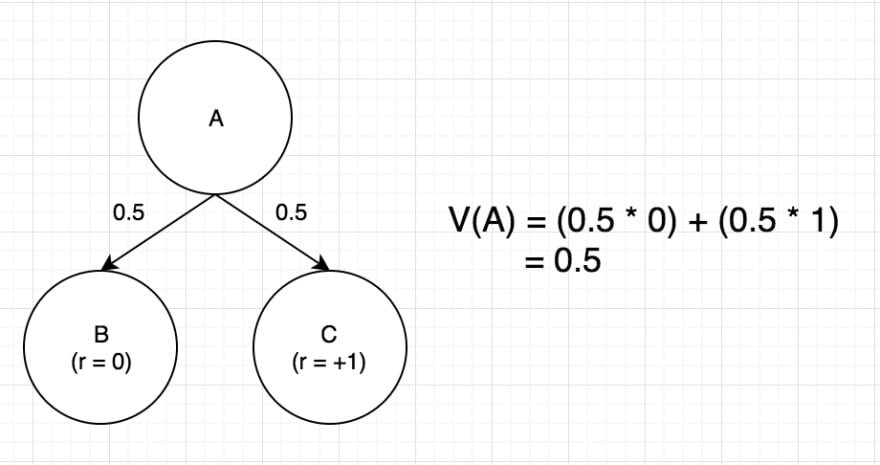
In figure 1, how do we determine the value of state A? There is a 50–50 chance to end up in the next 2 possible states, either state B or C. The value of state A is simply the sum of all next states’ probability multiplied by the reward for reaching that state. The value of state A is 0.5.
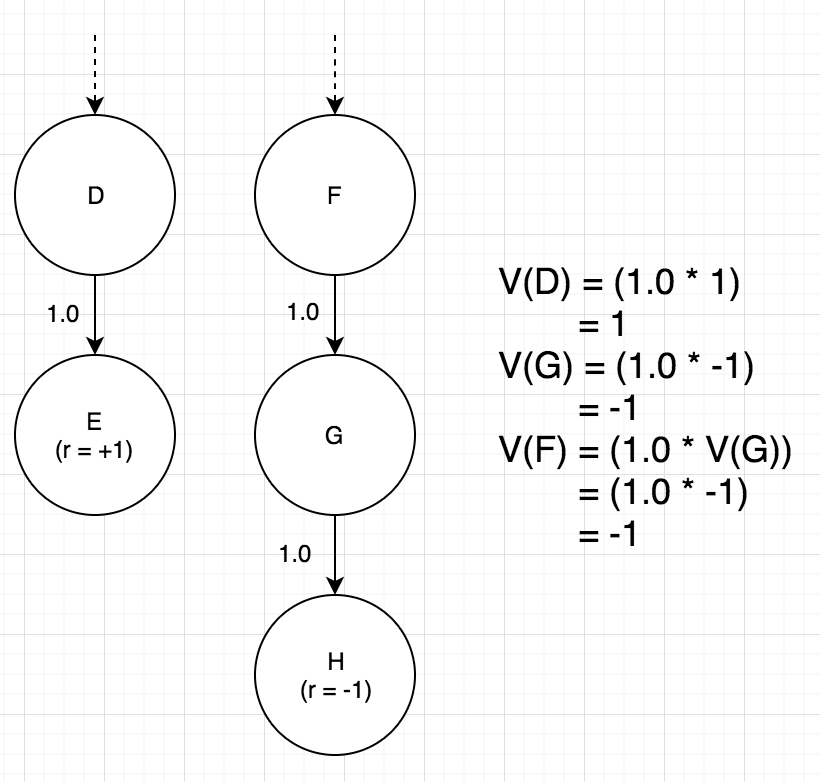
In figure 2, you find yourself in state D with only 1 possible route to state E. Since state E gives a reward of 1, state D’s value is also 1 since the only outcome is to receive the reward.
If you are in state F (in figure 2), which can only lead to state G, followed by state H. Since state H has a negative reward of -1, state G’s value will also be -1, likewise for state F.

In this game of tic-tac-toe, getting 2 Xs in a row (state J in figure 3) does not win the game, hence there is no reward. But being at state J places you one step closer to reaching state K, completing the row of X to win the game, thus being in state J yields a good value.

In figure 4, you’ll find yourself in state L contemplating where to place your next X. You can place it at the top thus bringing you to state M with 2 Xs in the same row. The other choice would be to place it at the bottom row. State M should have a higher significance and value as compared to state N because it results in a higher possibility of victory.
Therefore, at any given state, we can perform the action that brings us (or the agent) closer to receiving a reward, by picking the state that yields us the highest value.
Tic Tac Toe — Initialise the Value Function
The Value function V(s) for a tic-tac-toe game is the probability of winning for achieving state s. This initialisation is done to define the winning and losing state. We initialise the states as the following:
- V(s) = 1 — if the agent won the game in state s, it is a terminal state
- V(s) = 0 — if the agent lost or tie the game in state s, it is a terminal state
- V(s) = 0.5 — otherwise 0.5 for non-terminal states, which will be finetuned during training
Tic Tac Toe — Update the Value Function
Updating the value function is how the agent learns from past experiences, by updating the value of those states that have been through in the training process.

State s’ is the next state of the current state s. We can update the value of the current state s by adding the differences in value between state s and s’. α is the learning rate.
As multiple actions can be taken at any given state, so constantly picking only one action at a state that used to bring success might end up missing other better states to be in. In reinforcement learning, this is the explore-exploit dilemma.
With explore strategy, the agent takes random actions to try unexplored states which may find other ways to win the game. With exploit strategy, the agent is able to increase the confidence of those actions that worked in the past to gain rewards. With a good balance between exploring and exploiting, and by playing infinitely many games, the value for every state will approach its true probability. This good balance between exploring and exploit is determined by the epsilon greedy parameter.
We can only update the value of each state that has been played in that particular game by the agent when the game has ended, after knowing if the agent has won (reward = 1) or lost/tie (reward = 0). A terminal state can only be 0 or 1, and we know exactly which are the terminal states as defined in during the initialisation.
The goal of the agent is to update the value function after a game is played to learn the list of actions that were executed. As every state’s value is updated using the next state’s value, during the end of each game, the update process read the state history of that particular game backwards and finetunes the value for each state.
Tic Tac Toe — Exploit the Value Function
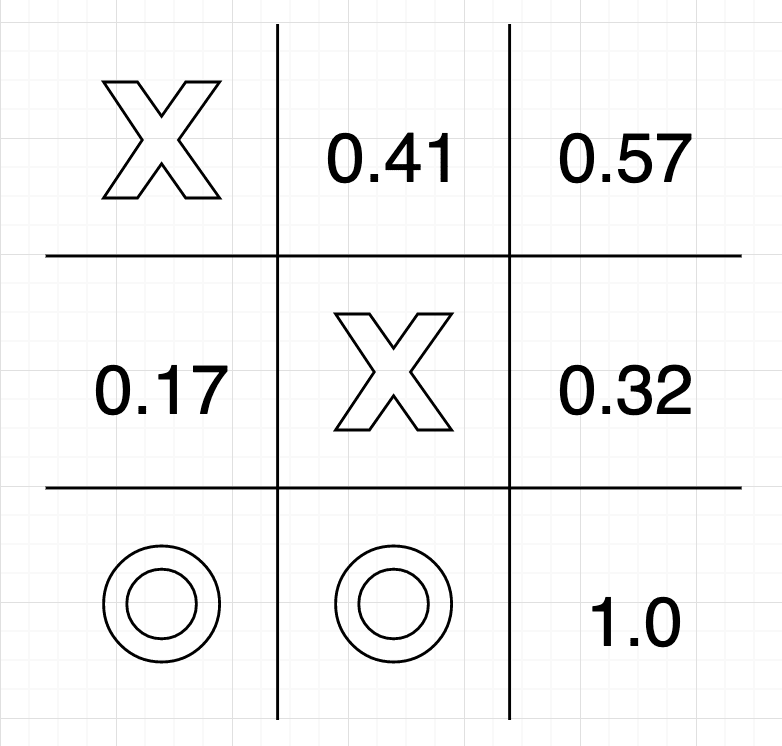
Given enough training, the agent would have learnt the value (or probability of winning) of any given state. So, when we play a game against our trained agent, the agent uses the exploit strategy to maximise winning rate. See if you can win against the agent.
At each state of the game, the agent loop through every possibility, picking the next state with the highest value, therefore selecting the best course of action. In figure 6, the agent would pick the bottom-right corner to win the game.
Conclusion
At any progression state except the terminal stage (where a win, loss or draw is recorded), the agent takes an action which leads to the next state, which may not yield any reward but would result in the agent a move closer to receiving a reward.
The value function is the algorithm to determine the value of being in a state, the probability of receiving a future reward.
The value of each state is updated reversed chronologically through the state history of a game, with enough training using both explore and exploit strategy, the agent will be able to determine the true value of each state in the game.
There are many ways to define a value function, this is just one that is suitable for a tic-tac-toe game.

Top comments (0)