Refactoring code is innately risky. In the payments domain, the risks are amplified and can be (or feel) catastrophic. Simple regressions can lead to significant losses both financially and in customer trust. As a result, it's far too common for a codebase's payments side to suffer from entropy due to simple aversion.
Having worked with legacy1 payment systems, I've seen first hand the type of mess that can be built when code is tiptoed around. The results are akin to what happens with the broken window theory where the codebase deteriorates because it looks like nobody cares. Instead of broken windows, these are spooky windows, and nobody wants to get near them. As a result, new functionality gets shoehorned in with the slight possibility of spec coverage.
The good thing is that it doesn't have to be this way, and you don't need to live with spooky windows. Given sharp tools, it's possible to safely and confidently refactor critical code paths that deal with money.
Mystery comments, missing tests, and spaghetti conditionals
I'm going to use a real-world example, but first, allow me to set the stage. I needed to add some new functionality that would impact the total amount a customer would be charged. The core calculation logic was encapsulated in a single module but was teetering on being incomprehensible due to years of churn. New features were mostly comprised of additional conditionals that didn't quite make sense.
To make matters worse, there were no unit tests to help explain the behavior – instead, there were sporadic integration style tests smathered across the test suite leaving large gaps in spec coverage. And to top it all off, the code in question was riddled with comments like # not sure why we do this and # how can this be zero?. This is code the determines how much to charge someone...horrifying, right?
In most cases, when the surface area of code is small, a test harness can be added to guide a new feature. This wasn't most cases. The module was the antithesis of orthogonal and had enough code branches to warrant pen and paper to follow. I like to enjoy writing code, so a refactor was in order.
Feedback loops in production
I took a stab at refactoring the calculator logic and added unit tests for every line. Even though all the original integration specs passed, I knew that here be dragons. To eliminate any uncertainty and ensure zero customer impact, I reached for Verify Branch by Abstraction.
Coined by Steve Smith, Verify Branch by Abstraction is a strategy to introduce new code while reducing the risk of failure. I highly recommend you check out Steve's post, but to summarize: A toggle is placed in front of your code in question that delegates to a verifying implementation to ensure both code paths return the same result. If the results differ, the original implementation's result is returned, and the error is logged.
Test suites are great. Testing with production data is even better. In an
ideal world, you'd have the ability to record production data for playback in a test suite, but that introduces complexity and infrastructure requirements that may be limiting factors. This approach delivers a similar outcome at a fraction of the cost.
Here's a basic overview of what it looked like:
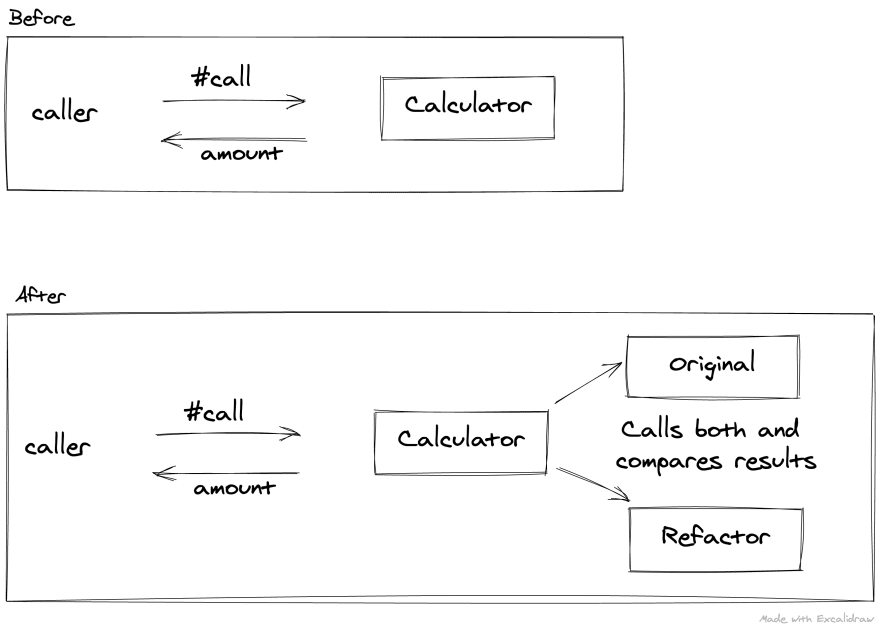
It's worth noting the following strategy doesn't work if your code under question has side effects that result in persisted changes. In those scenarios, you may need to be a bit creative. One idea would be to push any state changes to the edge of your domain logic so that you can verify the code under question independently.
Run both code paths
There was a single entry-point for the price calculation logic via a #call method that I chose to hijack by moving all the original logic into a new file called old_calculator.rb. The refactor candidate was placed in candidate_calculator.rb.
# This method once held the contents of `original_calculator.rb`.
def call(input)
original = OriginalCalculator.call(input)
if Feature.enabled?("calculator_refactor")
candidate = CandidateCalculator.call(input)
compare(original, candidate)
end
rescue => e
log_error(e)
ensure
original
end
def compare(original, candidate)
# compares the attributes of both objects and logs
# an error if they differ
end
Fairly simple stuff – run both code paths, compare the results, but always return the original implementation. For extra safety, rescue and ensure were added if the candidate code did something unexpected.
Granted, this isn't the fanciest representation of Verify Branch by Abstraction. My toggle is a feature flag (no sense in running both code paths if the refactor is causing too much noise or latency), and the verifying implementation is a simple #compare method. I opted not to add the ability to return the refactor candidate response simply because there wasn't any value added. My deviation from Verify Branch by Abstraction has the tradeoff of requiring soak time. In my scenario, I was OK with letting the refactor candidate bake, but if a quicker turnaround were necessary, then a smarter verifying implementation that returns the new code and falls back to the original code would be preferred. I went for a quick and easy to test implementation. Your mileage may vary!
Observe failures and lock them down
With both code paths running in production, it was easy to see that I had missed something.

The logs (from the comparison) showed two bugs in my refactor:
1) A misunderstanding of how a particular discount was being used.
2) A completely unexpected scenario that didn't even seem possible.
Two patches later and the failure rate was down to zero. I was able to add regression specs and document an unknown feature that was hidden in the weeds. Success!
At this point, I could've switched over to using the new refactor code, but for precaution, I let the code sit for two weeks. Lo and behold, another bug popped up due to an obscure use case, which wasn't very comforting. For precaution, I let the branched code sit in production for a month before fully switching over to using the refactor candidate.
Big code changes require patience.
Other tools
I've used this approach numerous times and have found it reliable to ship large changes. You may find that you need a bit more tooling to get this done for more complex changes. There's a great Ruby library called scientist that does just that. I used it to migrate an Elasticsearch cluster from version 1.X to 6.X without any downtime. One of my favorite benefits of scientist is that it provides a succinct API to ramp up experiments.
If Ruby isn't your language of choice, there's a whole list of alternatives.
-
I like Michael Feather's definition of legacy code being "code without tests". ↩

Top comments (0)