
This week we'll showcase our roadmap for implementing Machine Learning models for general testing purposes.
If you are interested in the background of Artificial Intelligence Implementation or how it goes, follow the links below:
Problem
Current Spec Tests are good for checking the presence, and type of extracted data. However, special tests must be implemented to check for the quality of the extracted data.
| Example | Checks |
|---|---|
{"title": "SerpApi"} |
✅ passes if it is always present in a set or not, and its class will be checked. |
{"title": "<a href='https://serpapi.com'>SerpApi</a>"} |
✅ same set of tests will pass. |
Both titles are present, their occurrence will be the same, and both of them will be String class. So it takes a special test to implement to the problematic part to check if it includes any http code inside the string. Not to mention, this process will take place only if someone notices it, not the original spec as it should.
Background Research and Useful Methods to Utilize
KNN (k-nearest neighbors) Algorithm
This algorithm has been around since 1951, and being used for statistical classification. Its effectiveness is in its elegant simplicity. If you can express the traits of data in a mathematical way, you can create an n-dimensional vector out of these numbers.
The end of this vector represents a point in that n-dimensional space. Closeness of these points will define the mathematical similarity between each vector's behavior. Hence, each similar behavior gives us the opportunity to classify them under categories.
Same approach could be utilized to classify these points. What we want to utilize for our problem is one more step further, which is to check whether individual extracted values behave in the same way as the past extracted data.
These formulas have also been derived long ago, in 18th century by creating a connection between the formulas of Euclid, and Pythagoras. They are essential in higher dimensional distance calculation between points. Here's a cheatsheet for them:
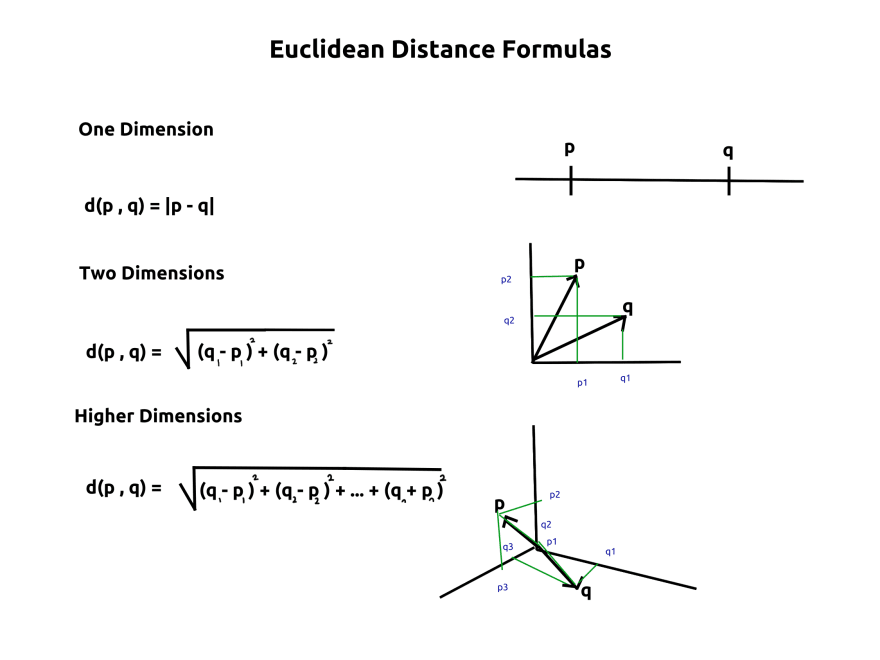
Before the reader gets confused, let me explain why and how these two concepts are important. Each trait we will cover for an extracted data, whether its class, or length, or simply index of its letters; they will all be covered in one dimension of the cartesian plane.
Here's an example to break it down:
Assume the key title consists of strings with 7-10 length for the majority of the cases.
If the title is SerpApi, the vector will be [7]. Let's imagine a set we trained a model for the individual key title:
[
{
"title": "SerpApi",
"type": "API",
"place": "Austin"
},
...
{
"title": "XCompany",
"type": "X",
"place": "XXX"
}
]
All of these values will create a datatable such as:
| Value | Length | Key |
|---|---|---|
| SerpApi | 7 | title |
| API | 3 | type |
| Austin | 6 | place |
| ... | ... | ... |
| XCompany | 8 | title |
| X | 1 | type |
| XXX | 3 | place |
Imagine the entries in the Length column as individual points in a line. A line is one dimensional. So we can use:
=|p-q|")
If we wanted to find what is the XCompany, without having Key column, we would use the formula for each of these values compared to 8, take the minimum (1-nn), or the majority case for the n closest neighbors (k-nn), and classify that it is title.
Now let's repurpose this statement and ask if XCompany is a title. But to do that, we need to rearrange our datatable with not_title for all rows with something other than title in its Key column:
| Value | Length | Key |
|---|---|---|
| SerpApi | 7 | title |
| API | 3 | not_title |
| Austin | 6 | not_title |
| ... | ... | ... |
| XCompany | 8 | title |
| X | 1 | not_title |
| XXX | 3 | not_title |
Now if we use the same method for XCompany in here, the point with the minimum distance will be SerpApi, which suggests us that the key is title.
Clustering with Weights
The reader may ask how this will prove useful since the length of a string is hardly a classifying actor in many cases. This is where the Machine Learning Process takes place.
Each of these vectors could be adjusted with their weight vectors, each weight vector starting as vector 1, and adjusted with each correct and incorrect guess accordingly, getting away or getting closer to the compared vector.
This will create different clusters of vectors where similar ones will be closer and dissimilar ones will be away from each other in the end.

Hypothesis
Implementing above-mentioned technique could be utilized in testing the quality of the extracted data, and could be used for testing any kind of JSON data. The process should be in such order:
- Creating a database with keys inside (each inner key with its unique identifier)
[
{
"title": "SerpApi",
"text": "Scrape Google Organic Results"
"usecases": {
"text": "Scraping SERP Results"
...
},
...
}
...
]
The key text, and the key usecases -> text will be treated differently:
| Value | Length | Key |
|---|---|---|
| SerpApi | 7 | title |
| Scrape Google Organic Results | 29 | text |
| Scraping SERP Results | 21 | usecases__text |
| ... | ... | ... |
- Creating Database for Each Key (Exclusion of same key names in inner_keys)
| Value | Length | Key |
|---|---|---|
| SerpApi | 7 | not_text |
| Scrape Google Organic Results | 29 | text |
| ... | ... | ... |
Notice that usecases__text is omitted not to cause confusion in modeling. Since we are measuring if this key contains a defined text or not, it won't hurt the accuracy of the overall model. An estimation we will test for sure.
Creating individual models for each present key in each example. This process should be an easy Rake command
-
Integrate these models inside Rspec. tests as improving part for checking the quality to warn the developer that something is off with the result when a certain statistical threshold is reached in
falseresponses throughout examples, and point to the problematic models with higher certainty of error.- The statistical threshold mentioned here will be tested throughout different extracted data. We will see if it can be generalized or if it should be suggested for each different data structure.
Testing and Analyzing Structure
- Word Level Indexing (N-gram) alongside general traits
- Character Level Indexing alongside different general traits such as class of the extracted value, its length, etc.
- Sentence to Character Level Indexing
- Whether this implementation should use third party libraries such as
Torchor not (for modularity across different languages and stacks) - What should be the Statistical Error Threshold to raise error in Rspec tests?
- Should the Error Threshold be different in different structured data?
We will start by writing JSON to CSV Datatable creator. After that, making this process independent of libraries is important. For that, we'll investigate how we can store the individual models inside a file.
Word Level Indexing will be the first choice to test the hypothesis since it held valuable to us in the ML-Hybrid Parser mentioned in previous blog posts.
Conclusion
I'd like to thank the user for the attention, and brilliant people of SerpApi for all their support.
Next week, we'll investigate how to create key-specific model creation as mentioned above.
Read my other blog posts if you found this blog post useful.
Join us on | Twitter | YouTube | Dev.to | Hashnode | SerpApi Medium |
Originally published at https://serpapi.com on March 23, 2022.

Top comments (0)