Hi everyone,
This is going to be a small get-together with LangChain4j. We'll build a simple CLI-based chatbot that can:
- Remember the conversation
- Search the internet if required to get time accurate answers.
This guide contains two parts:
A simpler implementation using high-level abstractions provided by LangChain4j.
A deeper dive into how these abstractions might work under the hood.
Link to full code: https://github.com/karan-79/cli-chatbot-langchain4j
So lets get into it.
What will we use
- OpenAI as the LLM provider (you can use any other provider or even run a local model).
- LangChain4j, the Java library that simplifies working with LLMs.
- Tavily, a tool that makes extracting useful information from webpages easier. Sign up and get a free API key here: https://tavily.com/
Setup.
- Open your IDE, setup a Java project using maven or build tool of your choice (I am using Intellij and maven)
- Add the following dependencies to your pom.xml:
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.15.2</version>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-web-search-engine-tavily</artifactId>
<version>1.0.0-beta1</version>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j</artifactId>
<version>1.0.0-beta1</version>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai</artifactId>
<version>1.0.0-beta1</version>
</dependency>
Using out of the box abstractions
Step 1: Build a ChatLanguageModel.
ChatLanguageModelis a language level API that sort of abstracts the API calls to the LLM.
In simple terms its an Interface which have different implementations for different LLM providers, and since we're usinglangchain4j-open-aiso will use Open AI model's implementationOpenAiChatModelprovided bylangchain4j-open-ai.
ChatLanguageModel model = OpenAiChatModel.builder()
.apiKey(System.getenv("OPENAI_API_KEY"))
.modelName(OpenAiChatModelName.GPT_4_O_MINI)
.build();
Here we use builder available on OpenAiChatModel and provide some configuration stuff, like the model we want to use, the API key.
Now, we have a model ready, we can invoke it by sending ChatMessage
ChatMessageis also a language level API that helps ease the communication for chat completions with LLM. There are various types ofChatMessages messages check more here
Step 2: Now we declare our AI chat service.
The concept is, To have an AI powered (non-agentic) app, you need to have a structured way to communicate your needs to LLM and have it give relevant answers. which involves:
- Formatting inputs for the LLM.
- Ensuring the LLM responds in a specific format.
- Parsing responses (e.g., from custom tools).
So one way is to have the consumer (you) define that structure. Langchain (python) introduced a concept of
Chainswhich lets you define a flow where your input goes through a bunch of chains invoking LLM, custom tools, parsers etc. and at the end you get your desired result.
LangChain4j do have the concept of Chains but it encourages a different solution which they call AI Services
Idea is to abstract away all the complex manual structuring of flows and give a simple declarative interface, And everything is getting taken care of by LangChain4j
So we create our own service,
public interface ChatService {
String chat(String userMessage);
}
Now, we can see that ChatService has a method chat that deals with String input and String output.
And here we build our service by telling langchain4j our desired structure:
ChatService service = AiServices.builder(ChatService.class)
.chatLanguageModel(model)
.build();
Now, our service is ready we can invoke the it by calling the chat method we specified.
service.chat("Hi how are you");
// I'm just a computer program, but I'm here and ready to help you! How can // I assist you today?
Langchain4j is calling the OpenAI API's but look how we didn't had to deal with all the API level responses.
If we change our interface. we get still get the desired response in desired structure. here we can see more supported structures
interface ChatService {
AiMessage chat(String message);
}
AiMessage aiMessage = service.chat("Hi how are you");
aiMessage.text();
/**
Hello! I'm just a program, so I don't have feelings, but I'm here and ready to help you. How can I assist you today?
*/
Step 3: Lets add some interaction
We enable a short console based input from user and send it to LLM and print the response
var scanner = new Scanner(System.in);
while (true) {
try {
System.out.print("User: ");
var userInput = scanner.nextLine();
if(List.of("q", "quit", "exit").contains(userInput.trim()) {
System.out.print("Assistant: Bye Bye");
break;
}
var answer = service.chat(userInput);
System.out.println("Assistant: " + answer);
} catch (Exception e) {
System.out.println("Something went wrong");
break;
}
}
here we can see the output:

Now we have the interface and are able to send messages, but we lack something.
Each input is independent. Hence, it appears chat bot does not remember previous interactions.

Lets fix that.
Step 4: Adding memory to our chatbot
LLMs are stateless—they process one input at a time without remembering previous interactions. To enable conversational flow, we need to send the conversation history along with the current message.
So to do so in langchain4j we have concept of Chat Memory
Chat Memory is different from just sending the whole history. Because when history grows large you need to perform some optimizations to not exceed the context window of the LLM model
learn more Chat memory
LangChain4j provides MessageWindowChatMemory class which will store our interactions with the LLM. we provide it in our AI service and it automatically takes care of messages. By default it stores the interactions in memory but can be made to persist them also
ChatService service = AiServices.builder(ChatService.class)
.chatLanguageModel(model)
.chatMemory(MessageWindowChatMemory.withMaxMessages(20))
.build();
Here we used MessageWindowChatMemory.withMaxMessages(20) which configures a MessageWindowChatMemory instance that will only store recent 20 messages.
There are a couple of techniques to enable memory for LLM like:
- Summarizing of history.
- Selective eviction (removal) of messages from history.
- Eviction of oldest message in history. For our use case we just use a simple one that will only keep upto 20 messages in a conversation with LLM and evict the oldest one as count increases from 20.
So, now we can see it in action:

Step 5: Adding internet search ability to our chat.
Since LLMs are trained on data upto a certain date. So they do not know latest knowledge. So, we use something called Tool calling
Tool calling

LLM providers such as Open AI gives feasibility of tool calling.
What essentially happen is, you tell the LLM in the conversation that you have some tools (functions in your code) with all their descriptions (what they do, what is the return type, what arguments they take) and then LLM can request the execution of tools (your functions) to get more accurate context or information. which is just a normal response and its our responsibility to ensure if LLM asked us to run a tool (function) with required arguments and then send back the results to process a proper response. See the above image from open ai
Find more info: openai , langchain4j tools
Langchain4j provides a pretty decent way to call your java methods as tools.
@Tool annotation makes a proper tool specification for your methods inside class as required by chat API from LLM providers like Open AI.
Below is one example how you can achieve this
public class Tools {
@Tool("Searches the internet for relevant information for given input query")
public String searchInternet(String query) {
// the implementaion
return "";
}
}
Which then can be provided to LLM in API calls via LangChain4j's AI Service:
ChatService service = AiServices.builder(ChatService.class)
.chatLanguageModel(model)
.chatMemory(MessageWindowChatMemory.withMaxMessages(20))
.tools(new Tools()) // here we instantiate the Tools class which then can be read by the LangChain4j
.build();
And now LangChain4j automatically generates a properly formatted description of your tool, which can be sent to Open AI's APIs.
Now that we have setup a tool, let's implement what we want the tool to do.
Tavily usage
We are using an API from Tavily.
Tavily saves us from all the cumbersome efforts of extracting a LLM ready information from webpages of a web search. And they also do more content optimizations that make the content somewhat rich for LLM.
We'll use a Tavily API abstraction provided by LangChain4j via langchain4j-web-search-engine-tavily. Just some language level API :).
@Tool("Searches the internet for relevant information for given input query")
public List<WebSearchOrganicResult> searchInternet(String query) {
// we make a client for tavily
TavilyWebSearchEngine webSearchEngine = TavilyWebSearchEngine.builder()
.apiKey(System.getenv("TAVILY_API_KEY"))
.build();
// we invoke the search passing 'query'
var webSearchResults= webSearchEngine.search(query);
// since there can be many results from different webpages so we'll only pick 4
return webSearchResults.results().subList(0, Math.min(4, webSearchResults.results().size()));
}
Here we just wrote a usage of tavily API.
The query argument will get the value what the LLM requires to search so we just channel it to tavily.
and lastly we just return the results.
Now we are all set. let's chat!

So we got a proper response on latest information, Also look the Tool we defined have List<WebSearchOrganicResult> return type, Langchain4j ensure the results of the tool (function) are properly formatted and sent back to llm.
Enable langchain4j logging
To see more things in action enable logs:
langchain4j logs using SL4J so lets a dependency for that in pom.xml:
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.5.8</version>
</dependency>
now on Model enable logs for requests and responses:
ChatLanguageModel model = OpenAiChatModel.builder()
.apiKey(System.getenv("OPENAI_API_KEY"))
.logRequests(true)
.logResponses(true)
.modelName(OpenAiChatModelName.GPT_4_O_MINI)
.build();
lets try again:
We see that lanchain4j is sending out information about our method that runs tavily

Now we got our response back

See how we get tool_calls in response which is understood as a Tool call request by LangChain4j. And it executes our method and see the results logged out.

Now we see another request happened to LLM:

Here we see LangChain4j sent another request to LLM on its own. because now it had gotten tool response and it attaches the results of tool call in the messages with role = tool. Thus providing the more context about what user had asked about.
And finally, we get our response back with LLM responding


There you have it, a simple chat bot with search capabilities :).
Getting under the surface
Here we'll go little bit under the surface of LangChain4j and try to understand how it may be working to enable the magic we saw.
We start and create a model first:
ChatLanguageModel model = OpenAiChatModel.builder()
.apiKey(System.getenv("OPENAI_API_KEY"))
.modelName(OpenAiChatModelName.GPT_4_O_MINI)
.build();
Lets understand memory
As we know, LLMs are stateless. We ought to give the whole history of the chat to emulate a conversational interaction.
So MessageWindowChatMemory class we used by creating instance like this MessageWindowChatMemory.withMaxMessages(20), is just a holder that keeps track of the messages that are to be sent in a conversation.
Looking inside the class we see:

-
MessageWindowChatMemorycontains aChatMemoryStorewhich further have its implementationInMemoryChatMemoryStorewhich maintains aConcurrentHashMap - this
ConcurrentHashMapholds aList<ChatMessage>thats where our history goes - the key in the
ConcurrentHashMapis to distinguish conversations. In our case we only had one so we ended with a default behavior
So technically we can maintain a our own List<ChatMessages>, right? Yes
var chatMemory = new ArrayList<ChatMessage>();
Now our conversation code will look like this:
while (true) {
try {
System.out.print("User: ");
var userInput = scanner.nextLine();
if (List.of("q", "quit", "exit").contains(userInput.trim())) {
System.out.print("Assitant: Bye Bye");
break;
}
// append the user input as UserMessage
chatMemory.add(UserMessage.from(userInput));
var answer = model.generate(chatMemory);
// append the model's answer
chatMemory.add(answer.content());
} catch (Exception e) {
System.out.println("Something went wrong");
break;
}
}
Here, we are using generate method on model by passing the current state of chatMemory list
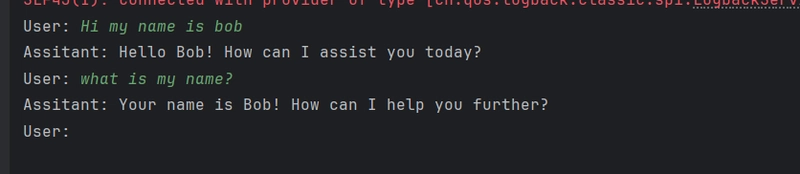
As you can see we have given the chat bot ability to remember :).
Lets understand tool
Tools like we saw are functions, whose description we can provide to LLM in its desired format. and it can respond with a tool call request if it sees a need
LangChain4j have ToolSpecification class which holds the required structure of a tool description which LLM demands. we can specify that using the builder or some helper methods like ToolSpecifications.toolSpecificationsFrom(Tools.class)
Lets see what its doing under the hood.

we see,
-
toolSpecificationsFrommethod inToolSpecificationsuses java reflection to get all methods of the class - filter methods that have a
@Toolannotation - extract the information about parameters, name of method and description provided in
@Tooland buildsList<ToolSpecification>for ourToolsclass.
List<ToolSpecification> is something that Langchain4j understands and it works with the model like this:
var answer = model.generate(chatMemory, toolSpecifications); // we send in toolSpecification
Now the request to LLM will include our tool's specification
Executing the tool
Since we've now taken responsibility to set tool specifications we now need to manually run the tool.
var scanner = new Scanner(System.in);
while (true) {
try {
System.out.print("User: ");
var userInput = scanner.nextLine();
if (List.of("q", "quit", "exit").contains(userInput.trim())) {
System.out.print("Assitant: Bye Bye");
break;
}
chatMemory.add(UserMessage.from(userInput));
var answer = model.generate(chatMemory, toolSpecifications);
chatMemory.add(answer.content());
// we check after the response if LLM request a tool call
if (answer.content().hasToolExecutionRequests()) {
// we iterate on the tool requests, in our case we've only given one tool so its going iterate once
for (var toolReq : answer.content().toolExecutionRequests()) {
var toolName = toolReq.name();
// we ensure that only 'searchInternet' tool is requested or not
if(!"searchInternet".equals(toolName)) {
continue;
}
// now we extract the input that we must pass to 'searchInternet' method
var objMapper = new ObjectMapper();
var input = objMapper.readTree(toolReq.arguments()).get("arg0").textValue();
// we just access that method directly
var toolResults = new Tools().searchInternet(input);
// since the response is in an Object and we must respond to LLM with a text so we do our little formatting of response from tavily search
var toolResultContent = writeToolResultsInText(toolResults);
// Now we append a ToolExecutionResultMessage in our history/memory
var toolMessage = ToolExecutionResultMessage.from(toolReq, toolResultContent);
chatMemory.add(toolMessage);
// now we again invoke the LLM, see this is that similar automatic request to LLM that LangChain4j did for us in previous section
// at this moment chatMemory consist of (UserMessage, ToolRequestMessage, ToolExecutionResultMessage)
var aiAnswerWithToolCall = model.generate(chatMemory, toolSpecifications);
System.out.println("Assistant (after tool execution): " +
aiAnswerWithToolCall.content().text());
// we now have the AiMessage and appent to chatMemory
chatMemory.add(aiAnswerWithToolCall.content());
}
} else {
System.out.println("Assitant: " + answer.content().text());
}
} catch (Exception e) {
System.out.println("Something went wrong");
break;
}
}
private static String writeToolResultsInText(List<WebSearchOrganicResult> toolResults) {
return toolResults.stream().reduce(new StringBuilder(), ((s, webSearchOrganicResult) -> {
s.append("Title: ").append(webSearchOrganicResult.title());
s.append("\n Content: ").append(webSearchOrganicResult.content());
s.append("\n Summary: ").append(webSearchOrganicResult.snippet());
s.append("\n");
return s;
}), (a, b) -> {
a.append(b.toString());
return a;
}).toString();
}
Alright. we now have done a pretty raw implementation of the whole flow. Lets try it out:


Top comments (0)