Hello everyone and new years greetings!
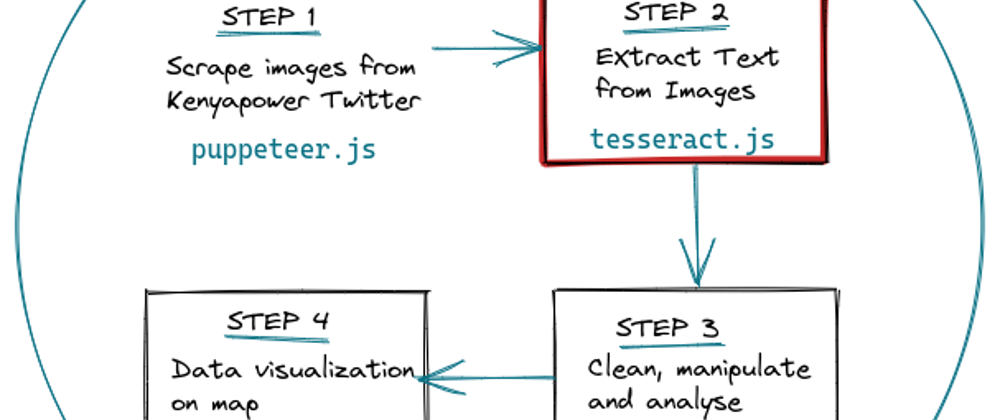
We'll extract text from our scraped photos in Part 2 of our Analyzing Kenya Power Interruption Data.
Tools/Libraries used
- TesseractJS - This is a pure JS port of Tesseract OCR which is a popular Optical Character Recognition engine.
Tesseract is built in C and C++, but I wanted to make the project as JS-centric as possible, so I chose the Javascript port.
Text Extraction Process
The images we grabbed from Twitter are all text-based, which is exactly what we need to map out this data. Remember that this is how our images will appear, and we want to be able to save this text as a.txt file.

This stage is straightforward and follows the steps below.
- Read all files from the source folder containing our images, KenyaPower in our case.
- If it does not already exist, create a folder in the text/destination folder with the same name as the source folder.
- Extract text from all images in the source folder and save it to txt files in the destination folder.
The Tesseract.recognize() function accepts an image path, reads it, extracts text from it, and saves it to a txt file in this example.
await Tesseract.recognize(
path.resolve(`${__dirname}/images/${sourceImageFolder}`, `${files[i]}`),
"eng"
).then(({ data: { text } }) => {
const textPath = path.resolve(
`${__dirname}/text/${sourceImageFolder}`,
`${files[i].replace(".png", "")}.txt`
);
const writeStream = fs.createWriteStream(textPath);
writeStream.write(text);
});
Here's an example of how our text files look once they've been extracted. Everything stayed aligned as it was in our images, which I was extremely impressed with.

Perfomance
My initial goal was simply to be able to extract the text, and I didn't give performance a priority. However, after getting the script to run, I decided to look into ways to speed up the process, especially because the entire project flow will be automated in the end.
To calculate the time it took for my entire script to run, I used NodeJS perf hooks. It was quite useful, and I will definitely use it again if I encounter a similar situation.
Node v8.5.0 added Performance Timing API, which includes the performance#now()
A simple example of how to use perfomance.now():
const { performance } = require('perf_hooks');
const howToLive = ['lead', 'with', 'love'];
const startTime = performance.now();
for (let i = 0; i < howToLive.length; i++) {
console.log(howToLive[i]);
}
const endTime = performance.now();
console.log(`Loop took ${endTime - startTime} milliseconds`);
I utilized 67 images to evaluate my performance, and extracting text from the images took about 803321 milliseconds, that is about 13 minutes for all and 11 seconds each image.
Conclusion
Please let me know if there are any improvements I could make to speed up this process. This process' codebase may be found here: Tesseract Text Extraction
Part 3 of our project, which I am very enthusiastic about, is data cleaning and analysis, which I will do using pandas, so don't worry, Python gurus:-)





Top comments (0)